






目的
- 使用随机森林建模
- 特征选取
- 微调
数据信息

数据表中
- year,moth,day,week分别表示的具体的时间
- temp_2:前天的最高温度值
- temp_1:昨天的最高温度值
- average:在历史中,每年这一天的平均最高温度值
- actual:这就是我们的标签值了,当天的真实最高温度
- friend:这一列可能是凑热闹的,你的朋友猜测的可能值,咱们不管它就好了
代码
数据大小
print('The shape of our features is:', features.shape)
数据描述
features.describe()
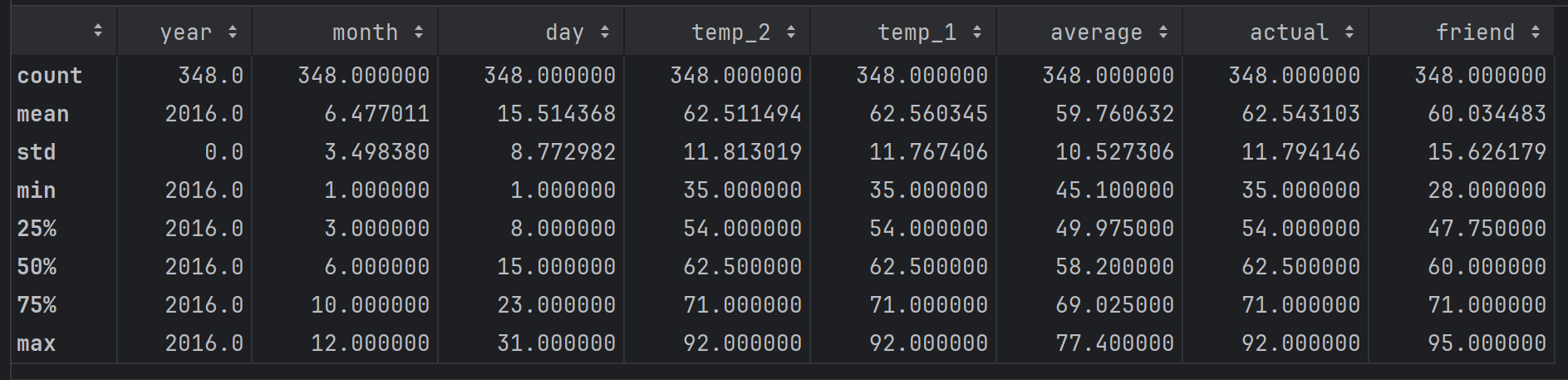
count都为38代表每列都没有缺失数据
数据预处理
将星期用独热编码处理One-Hot Encoding
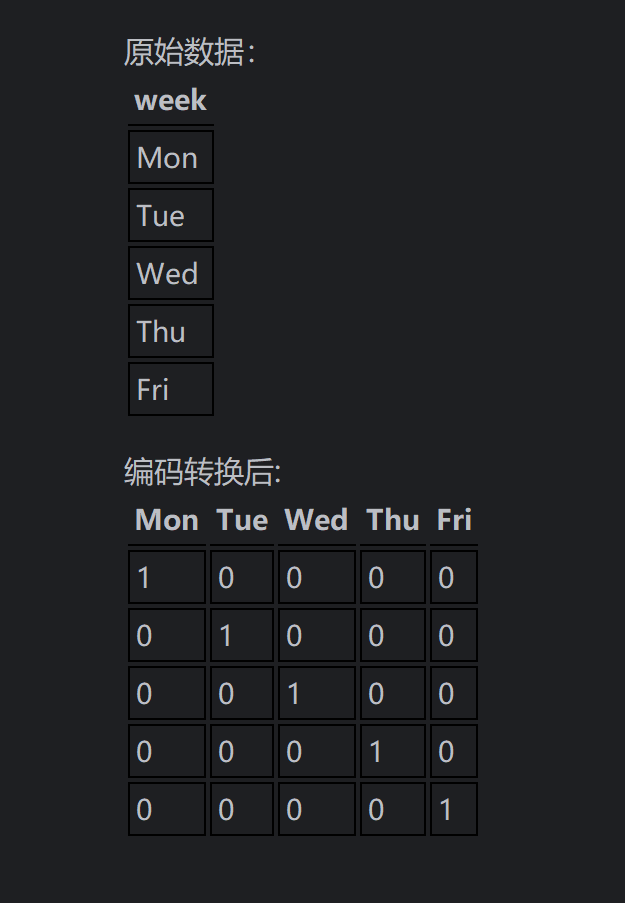
# 独热编码
features = pd.get_dummies(features)
features.head(5)

随机森林模型
# 导入算法
from sklearn.ensemble import RandomForestRegressor
# 建模
rf = RandomForestRegressor(n_estimators= 1000, random_state=42)
# 训练
rf.fit(train_features, train_labels)
mape评估
# 预测结果
predictions = rf.predict(test_features)
# 计算误差
errors = abs(predictions - test_labels)
# mean absolute percentage error (MAPE)
mape = 100 * (errors / test_labels)
print ('MAPE:',np.mean(mape))
可视化展示树
from sklearn.tree import export_graphviz
import pydot #pip install pydot
# 拿到其中的一棵树
tree = rf.estimators_[5]
# 导出成dot文件
export_graphviz(tree, out_file = 'tree.dot', feature_names = feature_list, rounded = True, precision = 1)
# 绘图
(graph, ) = pydot.graph_from_dot_file('tree.dot')
# 展示
graph.write_png('tree.png');

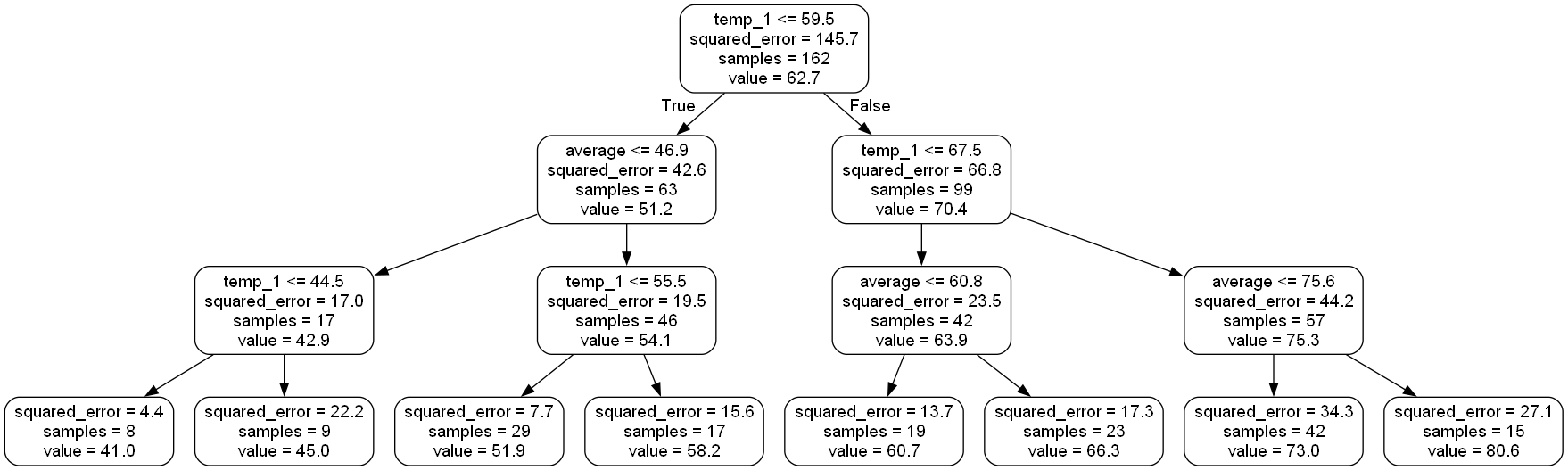
获取一个小一点的树
# 限制一下树模型
rf_small = RandomForestRegressor(n_estimators=10, max_depth = 3, random_state=42)
rf_small.fit(train_features, train_labels)
# 提取一颗树
tree_small = rf_small.estimators_[5]
# 保存
export_graphviz(tree_small, out_file = 'small_tree.dot', feature_names = feature_list, rounded = True, precision = 1)
(graph, ) = pydot.graph_from_dot_file('small_tree.dot')
graph.write_png('small_tree.png');
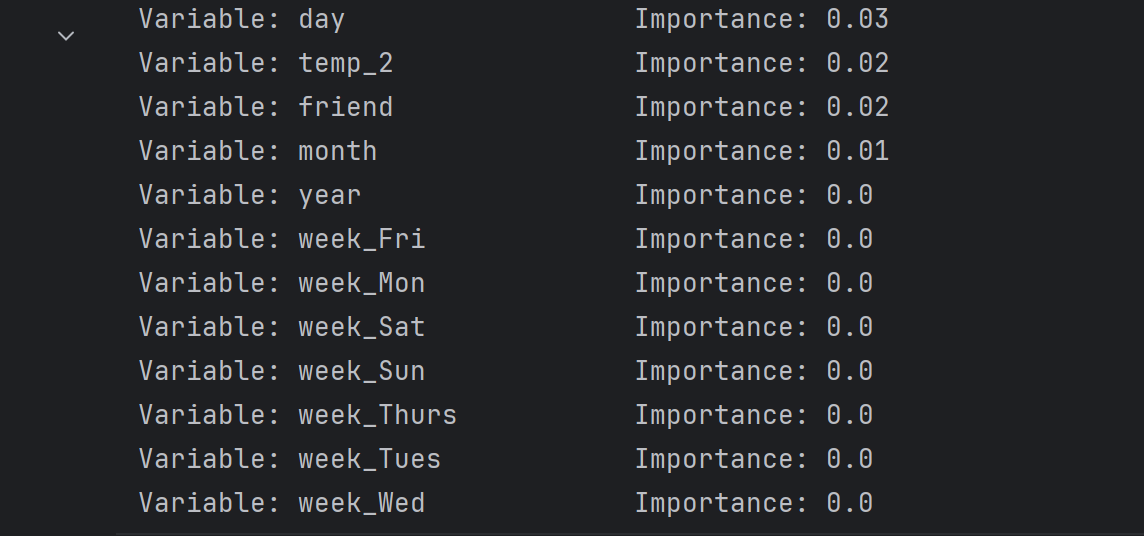
特征重要性
# 得到特征重要性
importances = list(rf.feature_importances_)
# 转换格式
feature_importances = [(feature, round(importance, 2)) for feature, importance in zip(feature_list, importances)]
# 排序
feature_importances = sorted(feature_importances, key = lambda x: x[1], reverse = True)
# 对应进行打印
[print('Variable: {:20} Importance: {}'.format(*pair)) for pair in feature_importances]
使用重要特征
# 选择最重要的那两个特征来试一试
rf_most_important = RandomForestRegressor(n_estimators= 1000, random_state=42)
# 拿到这俩特征
important_indices = [feature_list.index('temp_1'), feature_list.index('average')]
train_important = train_features[:, important_indices]
test_important = test_features[:, important_indices]
# 重新训练模型
rf_most_important.fit(train_important, train_labels)
# 预测结果
predictions = rf_most_important.predict(test_important)
errors = abs(predictions - test_labels)
# 评估结果
mape = np.mean(100 * (errors / test_labels))
print('mape:', mape)
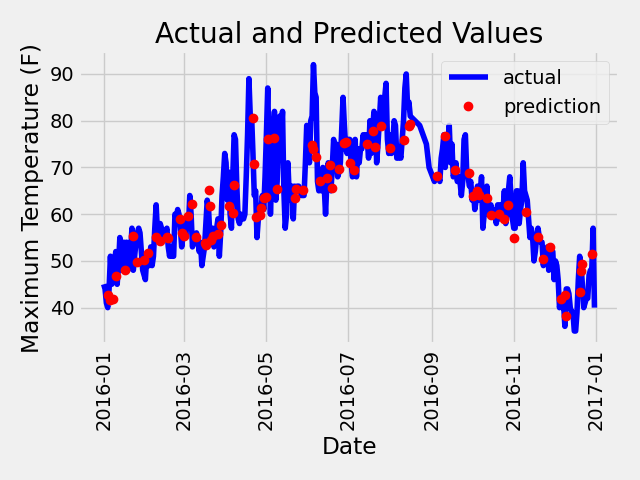
最后需要画图展示
















 873
873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









