







一、网络资源(URLs)撷取套件。
可以使用REST操作(POST, PUT, GET, DELETE)存取网络资源。以新浪新闻网站为例:
import requests
res = requests.get('http://news.sina.com.cn/china/')
res.encoding = 'utf-8'
print(res.text)
二、BeautifulSoup4
2.1 将保存的网络资源转化为DOM Tree,可提取每个节点文字信息。
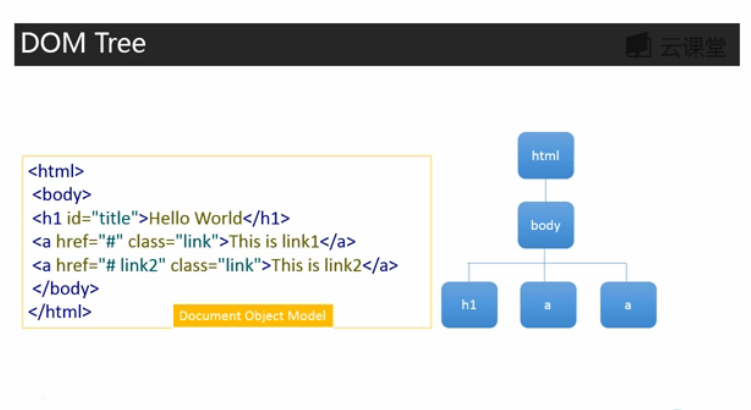
from bs4 import BeautifulSoup
html_sample = ' \
<html> \
<body> \
<h1 id='title'>Hello World</h1> \
<a href="#" class="link">This is link1</a> \
<a href="# link2" class="link">This is link2</a> \
</body> \
</html>'
soup = BeautifulSoup(html_sample, 'html.parser')
print(soup.text)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2775
2775











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









