







一、总结
这是一篇发表在2015年CCS上的一篇论文,相见恨晚,虽然时间比较久了,但是这篇论文还是很值得去读。
文章介绍的是模型逆向攻击,模型逆向攻击(model inversion attack)可以利用黑盒模型输出中的 confidence 等信息将训练 集中的人脸恢复出来。他们针对常用的面部识别 模型,包括 softmax 回归、多层感知机和自编码器网络实施模型逆向攻击。他们认为模型输出的confidence 包含的输入数据信息,也可以作为 输入数据恢复攻击的衡量标准。他们将模型逆向攻击问题转变为一个优化问题,优化目标为使逆向数据的输出向量与目标数据的输出向量差异尽可能地小,即假如攻击者获得了属于某一类别的输出向量,那么他可以利用梯度下降的方法使逆向的数据经过目标模型的推断后,仍然能得到同样的输出向量[1]。
二、introduction
许多公司建立了ML即服务云系统,其中客户可以上传数据集,训练分类器或回归模型,然后获得使用训练过的模型执行预测查询的访问权。这些模型使用一些特征后,调用API实现预测,而这些API含有很多隐私信息。
原文研究了API模式的攻击,作者首先表明,Fredrikson的攻击,即使它在计算上易于进行,在我们的新环境下中也不是特别有效。因此,我们引入了新的攻击,来推断作为决策树模型输入的敏感特征,以及从API访问面部识别服务中恢复图像的攻击。在这两种情况下关键是,我们可以构建利用api暴露的置信度值的攻击算法。我们的面部识别攻击的一个例子如图1所示:攻击者可以生成一个可识别的人的图像,左边为攻击提取的图像,右边是训练集的图像。

图1
1.ML APIs and model inversion(ML API 模型逆向)
作者大致将客户端访问划分为黑盒或白盒。在黑盒设置中,对抗性的客户端可以对模型进行预测查询,但不能实际下载模型结构。在白框设置中,允许客户端下载该模型的结构。
对于ML 模型来说,我们可以把其比作成一个函数F,然后函数有一些输入[x1,x2,...,xn],这叫做模型的特征,然后模型输出的结果 Y = F(x1,x2,...xn)。
Fredrikson等人[2]的模型反演攻击中,黑客使用黑盒访问 F 来推断一个敏感特征,比如x1,是一个敏感特征,通过一些其他相关特征和输出值y,模型的损失值[3],以及单个变量的边际先验[4]。他们的算法是一个最大后验(MAP)估计器[5],它选取的是的值,使观察到已知值的概率最大化。然而,要做到这一点,需要计算f(x1, ..., xd)的每一个可能的x1值。这限制了它适用于x1可能值有限的设置的范围。
作者的第一个贡献是在一个新的背景下应用了MAP。BigML模型库[4]上的决策树模型中,弗雷德里克森等人的算法会错误地得出结论,但事实上,作者提出了可以显著提高模型逆向效能的新攻击。
2.White-box decision tree attacks (白盒决策树攻击)
调查通过BigML服务API提供的实际数据,我们可以看到模型描述所包含的信息比黑盒攻击所利用的在黑盒攻击中利用的更多信息。特别是,它们提供了训练集中符合决策树中每个决策树中的每个路径的实例数。除以实例总数实例的总数给出了分类的confidence。虽然先验地看,这个额外的信息似乎是无害的,但我们表明它实际上是可以被利用的。我们给出了一个新的MAP估计器,该估计器使用白盒设置中的confifidence信息来推断敏感信息。
confidence就是可信度,可信度就是我的分类器把这个结果预测出来了,这个结果的可信度是多少,有多少的概率认为这个模型是可信的。
三、BACKGROUND
1.ML basics
对于ML 模型来说,我们可以把其比作成一个函数F,然后函数有一些输入[x1,x2,...,xn],这叫做模型的特征,然后模型输出的结果 Y = F(x1,x2,...xn)。
一个ML模型只是一个简单的确定性函数f:Rd→Y,从d个特征到一组输出Y。当Y是一个有限集时,我们将f称为分类器。如果是Y=R,那么f是一个回归模型。
对于多分类模型来说,模型的输出可能有好几个,然后模型一般输出的是每一个类的概率,这个概率成为confidence(可信度)
2.ML APIs
API一般是为用户提供了一个模型训练平台,用户在线训练模型,然后平台为用户提供一个接口,用户通过接口来预测。一个模型可能是白盒也可能是黑盒,然后一般通过计费的方式限制API的查询次数。
3.Threat model
作者关注的是一个攻击者可以对模型的随意使用,对手拥有API公开的任何信息。在白框设置中,这意味着可以下载模型f。在黑盒设置中,攻击者选择特征向量进行预测查询。作者关注的是,攻击者可以从模型信息中逆向的获得原始数据集部分内容。
四、THE FREDRIKSON ET AL. ATTACK
Fredrikson等人考虑了一个线性回归模型F,他们通过白盒和辅助信息得到秘密信息,简单来说 y, = F(x1,x2,...xn) 。攻击者通过(x2,x3,...,xn, z1,z2,...zt,y)获得x1。其中y是模型输出,x1,x2,...xn是模型输入,z1,z2,...zt是辅助信息。
图2给出了 Fredrikson的逆向算法。err 是高斯误差模型,边际先验pi的计算方法是首先将x划分为不想交的一些范围,然后计算xi落在这个范围db的次数,用该次数除以该范围db所有向量的总数。然后
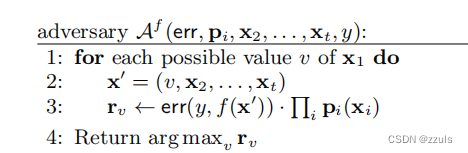
五、MAP INVERTERS FOR TREES
1.Decision tree background
这里介绍的是决策树,决策树模型递归地将特征空间划分为不相交的区域R1,...,Rm。通过找到包含x的区域,并返回该区域内训练数据中观察到的y的最可能值,对一个实例(x,y)进行预测。一个树可以这样描述:
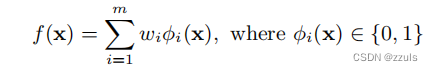
下面是一个树的例子 :

而对于决策树而言,不仅要考虑描述树,还需要考虑过拟合,因此要对树进行剪枝。要训练一个决策树需要不断的优化参数,下面是决策树的描述以及可信度计算方法。
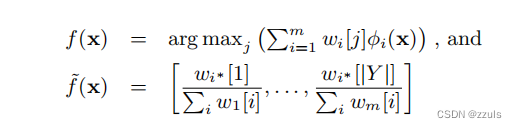
2.Decision tree APIs
介绍了BigML决策树也可以提供在线的API服务,有黑盒和白盒两种
3.Black-box MI
作者考虑决策树模型产生离散输出,损失值信息是不同的,作为一个混淆矩阵,而不是高斯分布的标准差。因此,为了我们这里的目的,我们使用混淆矩阵C 定义 err(y, y0 ) ∝ Pr [ f(x) = y0 | y is the true label ]
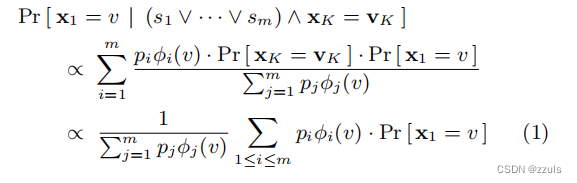
4.White-box MI
在白盒模型中,攻击者不仅知道 φi ,也知道样本的总数 。攻击者也知道X
, 在这个集合S中,S = {si} 1≤i≤m : S = {(φi, ni) | ∃x' ∈ Rd . x'
= x
∧ φi(x')}。此外每个φi 对应一个ni ,然后Pi = ni/N,然后代入算法就可以计算。
六、FACIAL RECOGNITION MODELS
作者在这个模型中主要讨论了两种攻击:reconstruction attack、deblurring attack。reconstruction attack是攻击者知道模型输出的结果,然后攻击者根据输出的结果可以还原出原始的图像。deblurring attack 则是攻击者得到了一副模糊图像,可以使用该模糊图像作为侧信息,输出去模糊的图像。
1.background
(1)Softmax regression:softmax 通常用于最后一层,多用于多分类任务,输出每一个类别的得分值
(2)Multilayer perceptron network:多层感知网络,有3000个sigmod的隐藏层,加上一个softmax层。该分类器可以理解为在首先对特征向量应用非线性变换后执行softmax回归。
(3)Stacked denoising autoencoder network:两个隐藏层,分别是1000个sigmod和300个sigmod,然后连接上一个softmax层
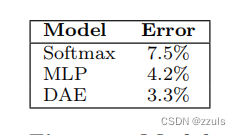
(4)Dataset:每组10张,40组总共400张图像。我们将每个人的图像分为训练集(7张图像)和验证集(3张图像),准确率如图:
(5)Basic MI attack:
模型的输出是一个向量,每一个分量是属于某一个类的概率,是输出的第i个分量。
使用梯度下降(GD)来最小化涉及的代价函数,以在此设置下进行模型反演。梯度下降通过将一个候选解迭代地变换为在该候选解处的梯度的负值来找到一个可微函数的局部最小值。我们的算法由算法1中的函数MI-Face给出:


c是损失函数,AuxTERM 函数是一个针对不同案例,会变化的函数,λ是梯度下降的步长。
2.Reconstruction Attack
作者定义了 AuxTerm(x) = 0 对于所有的 x. 作者对于 MI-Face 算法的参数为: α = 5000, β = 100, γ = 0.99, and λ = 0.1; 对于DAE来说,process过程使用的是算法2。ProcessDAE将候选像素解码到原始像素空间中,应用去噪滤波器,然后使用锐化滤波器,并将得到的像素重新编码到潜在空间中。我们发现,这种处理从最终的重建中消除了大量的噪声,同时增强了可识别的特征,并使相对像素强度更接近来自训练集的图像。
七、 reference
[1] Kui REN, Quanrun MENG, Shoukun YAN, Zhan QIN. Survey of artificial intelligence data security and privacy protection[J]. Chinese Journal of Network and Information Security, 2021, 7(1): 1-10
[2] M. Fredrikson, E. Lantz, S. Jha, S. Lin, D. Page, and T. Ristenpart. Privacy in pharmacogenetics: An end-to-end case study of personalized warfarin dosing. In USENIX Security Symposium, pages 17–32, 2014.
[3] https://blog.csdn.net/qq_31020665/article/details/100080181


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









