







Ex5_机器学习_吴恩达课程作业(Python):偏差预方差(Bias vs Variance)
文章目录
使用说明:
本文章为关于吴恩达老师在Coursera上的机器学习课程的学习笔记。
- 本文第一部分首先介绍课程对应周次的知识回顾以及重点笔记,以及代码实现的库引入。
- 本文第二部分包括代码实现部分中的自定义函数实现细节。
- 本文第三部分即为与课程练习题目相对应的具体代码实现。
0. Pre-condition
This section includes some introductions of libraries.
# Programming exercise 5 for week 6
import numpy as np
import matplotlib.pyplot as plt
import ex5_function as func
from scipy.io import loadmat
00. Self-created Functions
This section includes self-created functions.
-
linearRegCost(theta, X, y, l):损失函数
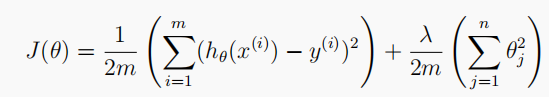
# Cost function of Regularized linear regression 计算损失 # theta: 模型参数; X: 训练特征集; y: 训练标签集; l: 正则化参数lambda def linearRegCost(theta, X, y, l): cost = np.sum((X @ theta - y.flatten()) ** 2) reg = (l * (theta[1:] @ theta[1:])) return (cost + reg) / (2 * len(X)) -
linearRegGradient(theta, X, y, l):梯度计算函数
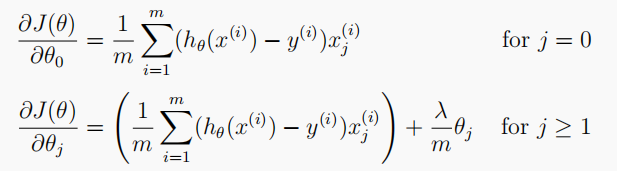
# Gradient of Regularized linear regression 计算梯度 # theta: 模型参数; X: 训练特征集; y: 训练标签集; l: 正则化参数lambda def linearRegGradient(theta, X, y, l): grad = (X @ theta - y.flatten()) @ X reg = np.zeros([len(theta)]) reg[1:] = l * theta[1:] reg[0] = 0 # don't regulate the bias term return (grad + reg) / len(X) -
trainLinearReg(X, y, l):正则化线性回归训练
# Train linear regression using "scipy" lib 训练拟合 # X: 训练特征集; y: 训练标签集; l: 正则化参数lambda def trainLinearReg(X, y, l): theta = np.zeros(X.shape[1]) res = opt.minimize(fun=linearRegCost, x0=theta, args=(X, y, l), method='TNC', jac=linearRegGradient) return res.x -
learningCurve(X, y, Xval, yval, l):绘制学习曲线
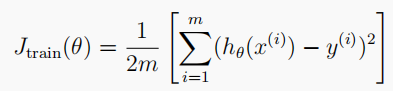
# Plot the learning curves to diagnose bias-variance problem # 绘制学习曲线,观察训练误差和交叉验证误差随样本数量变化而发生的变化 # X: 训练特征集; y: 训练标签集; Xval: 交叉验证特征集; yval: 交叉验证标签集; l: 正则化参数lambda def learningCurve(X, y, Xval, yval, l): xx = range(1, len(X) + 1) train_cost, cv_cost = [], [] # Gradually expand the size of the set for later computing cost for i in xx: # Compute temp parameters 计算临时最优参数 temp_theta = trainLinearReg(X[:i], y[:i], l) # Compute on part of the training set 计算此时模型在部分训练集上的损失 train_cost_i = linearRegCost(temp_theta, X[:i], y[:i], 0) # Compute on the whole cross validation set 计算此时模型在整个验证集上的损失 cv_cost_i
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 1227
1227











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









