







引子
Sa2VA模型通过结合SAM-2和LLaVA,将文本、图像和视频统一到共享的LLM标记空间中,能够在少量指令微调下执行多种任务,如图像/视频对话、指称分割和字幕生成。该模型在视频编辑和内容创作中展现出强大的性能,在相关基准任务中达到了SOTA水平。OK,那就让我们开始吧。

一、模型介绍
Sa2VA 模型通过结合基础视频分割模型 SAM-2 和高级视觉语言模型 LLaVA,将文本、图像和视频统一到共享的 LLM 标记空间中。这种架构设计使得 Sa2VA 能够在最少指令微调的情况下,执行多种任务,包括图像对话、视频对话、图像指称分割、视频指称分割和基于单次指令调整的字幕生成。
Sa2VA 在多个实际应用中展示了其强大的性能和潜力,其能够与用户进行自然语言交互,理解和生成与图像和视频内容相关的对话;在复杂视频场景中,准确分割用户指称的对象,因此非常适用于视频编辑、内容创作等场景。Sa2VA 具备 Qwen2-VL 和 InternVL2.5 所缺乏的视觉提示理解和密集对象分割能力,并且在图像和视频基础和分割基准上都实现了 SOTA 性能。
二、环境搭建
模型下载
https://huggingface.co/ByteDance/Sa2VA-4B/tree/main
代码下载
git clone https://github.com/magic-research/Sa2VA.git
docker run -it -v /datas/work/zzq/:/workspace --gpus=all pytorch/pytorch:2.4.0-cuda12.4-cudnn9-devel bash
cd /workspace/Sa2VA/Sa2VA-main
pip install mmcv==2.2.0 -f https://download.openmmlab.com/mmcv/dist/cu121/torch2.4/index.html
cd demo
pip install -r requirements.txt -i Simple Index
三、推理测试
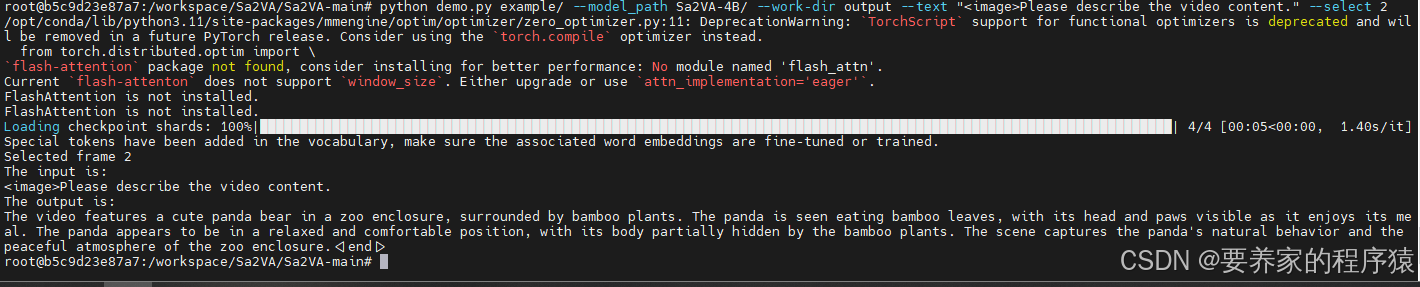
python demo.py example/ --model_path Sa2VA-4B/ --work-dir output --text "Please describe the video content." --select 2



















 261
261

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











