










〔更多精彩AI内容,尽在 「魔方AI空间」 ,引领AIGC科技时代〕
本文作者:猫先生
引言:多模态智能进入「具身化」新纪元
本期导读:多模态融合持续深化,生成式AI迎来效率与质量双重突破,开源大模型生态呈现国产崛起之势。
2025年开年之际,AIGC领域迎来技术架构的范式转移:从单一模态的独立优化转向多模态深度融合的协同进化。
本月的开源项目展现出三大核心趋势:视频生成与编辑的时空一致性突破、多模态大模型的轻量化适配、国产大模型崛起以及工业级应用的技术平权化。
值得关注的是,以FramePainter、Omni-RGPT为代表的项目通过「视频扩散先验」与「区域级Token化」技术,将传统图像编辑的维度扩展至时空连续体;而DeepSeek-V3、Phi-4等模型的迭代则昭示着MoE架构在参数效率与推理速度上的新高度。
从技术哲学视角观察,当前发展正突破「感知-认知」的二元割裂:Sa2VA通过SAM2与LLaVA的耦合实现了从像素级分割到语义理解的闭环,MagicMirror的适配器设计则验证了无需微调的个性化生成可行性。
这些突破不仅标志着多模态对齐(Multimodal Alignment)技术的成熟,更预示着AIGC系统将具备「跨模态涌现」的类人智能特性。
一、视频生成:时空一致性的新解法
FramePainter:视频扩散模型驱动的交互式图像编辑
项目主页:https://github.com/YBYBZhang/FramePainter
技术亮点:FramePainter通过将图像编辑问题重新表述为图像到视频生成问题,利用视频扩散先验降低训练成本并确保时间一致性。其轻量级稀疏控制编码器和匹配注意力机制使其在少量数据下即可实现无缝图像编辑,展现出卓越的泛化能力。
技术点评:该方法为交互式图像编辑提供了一种全新的视角,通过视频扩散模型的引入,解决了传统图像编辑方法在细节保留和风格一致性上的难题。其在少量数据下的高效训练能力使其在实际应用中具有显著优势。
MagicMirror:在Video DiT中生成身份一致且高质量个性化视频
项目主页:https://julianjuaner.github.io/projects/MagicMirror/
技术亮点:MagicMirror框架通过轻量级适配器和条件自适应归一化等创新设计,解决了个性化视频生成中的数据稀缺问题,并在身份一致性和自然动态性之间取得了良好平衡。
技术点评:MagicMirror的出现为个性化视频生成领域带来了新的突破。其在身份一致性和自然动态性方面的出色表现使其在视频内容创作和个性化应用中具有广阔的应用前景。
二、多模态理解:从区域感知到逻辑推理
Omni-RGPT:图像和视频的区域级理解
项目主页:https://miranheo.github.io/omni-rgpt/
技术亮点:Omni-RGPT通过引入Token Mark实现图像和视频的区域级理解,能够将用户定义的区域输入与文本提示相结合,生成针对特定视觉区域的定制化响应。此外,该研究还提出了一个大规模区域级视频指令数据集RegVID-300k。
技术点评:Omni-RGPT的区域级理解能力为多模态交互提供了新的可能性。其在图像和视频的常识推理、字幕生成以及引用表达理解等任务中的出色表现,展示了其广泛的应用前景。
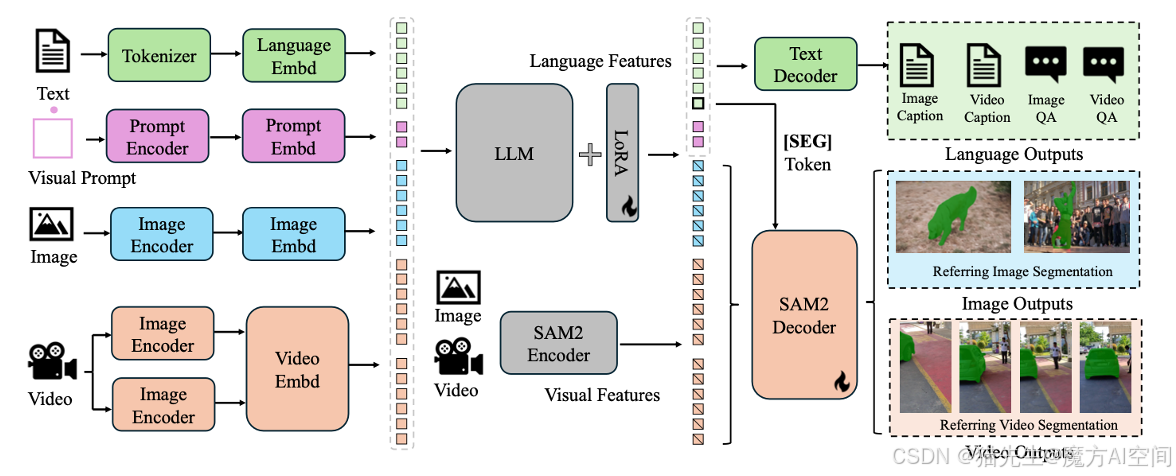
Sa2VA:将SAM2与LLaVA结合,实现对图像和视频的深入理解
项目主页:Sa2VA: Marrying SAM2 with LLaVA
技术亮点:Sa2VA通过结合SAM2(一种基础视频分割模型)和LLaVA(一种先进的视觉语言模型),将文本、图像和视频统一到一个共享的LLM Token空间中,支持图像和视频的多模态理解。
技术点评:Sa2VA的创新之处在于其对多模态数据的统一处理能力,能够实现图像和视频的细粒度理解。这种结合方式为未来多模态应用提供了新的思路,尤其是在视频分割和视觉问答领域。
三、生成技术平权化:从实验室到产业落地
FitDiT:开源高保真虚拟试穿技术
项目主页:https://byjiang.com/FitDiT/
技术亮点:FitDiT通过引入服装纹理提取器和频域学习等创新方法,解决了虚拟试穿中的纹理细节保留和尺寸适配问题。其在性能和速度上优于现有方法,单张1024x768图像的推理时间仅为4.57秒。
技术点评:虚拟试穿技术一直是AIGC领域的热点之一,FitDiT的出现为该领域带来了新的突破。其高效的推理能力和出色的细节表现使其在商业应用中具有巨大的潜力。
TangoFlux:超快速且可靠的文本到音频生成技术
项目主页:https://github.com/declare-lab/TangoFlux
技术亮点:TangoFlux能够在单个A40 GPU上在约3秒内生成长达30秒的44.1kHz立体声音频。该模型基于FluxTransformer块构建,训练流程包括预训练、微调和偏好优化,支持通过Python API、Web界面和命令行界面进行音频生成。
技术点评:TangoFlux的高效生成能力和高质量音频输出使其在文本到音频生成领域具有显著优势。其创新的训练流程和优化方法为音频生成技术的进一步发展提供了新的思路。

四、基础模型进化:效率与能力的再平衡
国产之光DeepSeek-V3 正式发布:性能领先
官方主页:DeepSeek
架构优势:MoE设计(64专家,激活4个)实现671B参数规模下的60 TPS生成速度,在知识类任务、长文本生成、代码生成和数学问题解决方面有显著提升。
产业影响:FP8量化权重开源推动边缘设备部署,预计将催生新一代端侧智能助手。
VITA-1.5: 迈向 GPT-4o 级别的实时视觉和语音交互
项目主页:https://github.com/VITA-MLLM/VITA
技术亮点:实现200ms级语音-视觉实时交互,支持中英双语,或为国产多模态OS提供基座能力。

微软开源phi-4:性能超越GPT-4o
项目主页:https://huggingface.co/microsoft/phi-4
训练创新:该模型经过严格的增强和调整过程,采用SFT和DPO,以确保精确的教学遵守和强大的安全措施。
范式意义:验证了小模型通过高质量数据筛选实现“超参数能力”的可能性。
伦理挑战:合成数据的偏见控制仍需加强。
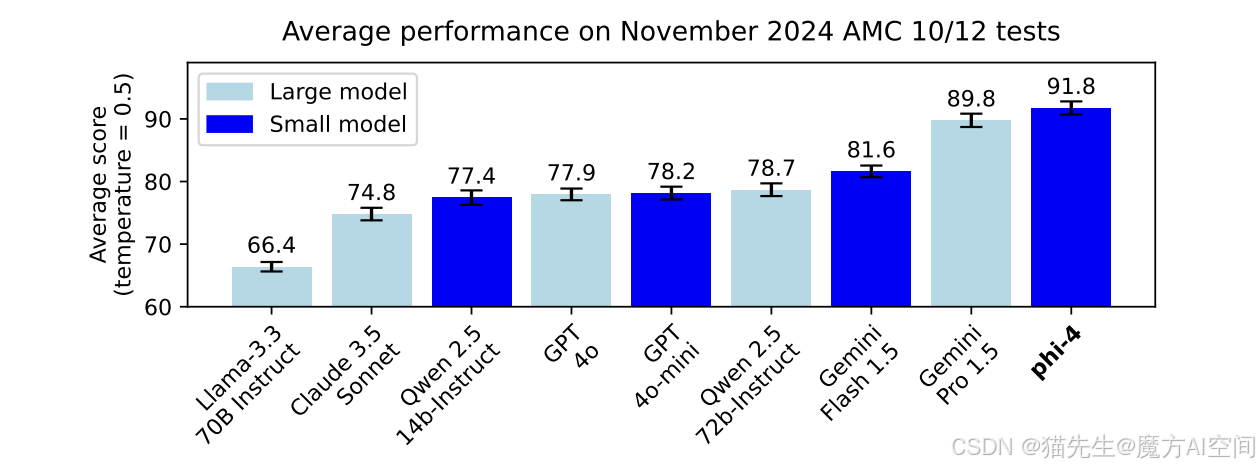
核心趋势:2025年或成"MoE架构普及元年",参数效率与推理速度的平衡将重构大模型竞争格局。
技术前瞻:2025年关键突破方向
1、多模态大一统:Sa2VA、Omni-RGPT等项目验证了「分割+理解+生成」三位一体架构的可行性,2024年或将出现首个千亿参数级视觉通用模型。
2、实时生成工业化:MagicMirror、TangoFlux等技术突破显示,生成延迟正从分钟级向秒级迈进,实时交互式AIGC应用即将爆发。
3、开源生态重构:DeepSeek-V3与phi-4的「MoE+小模型」组合策略,正在挑战传统Transformer架构的统治地位,开源社区迎来架构创新黄金期
4、实时生成硬件协同设计:Phi-4的FP8量化与DeepSeek-V3的60 TPS生成速度表明,模型架构将与推理芯片(如NPU)进行联合设计,催生端侧实时AIGC设备。
当多模态大模型开始理解“为什么”而不仅是“是什么”,当生成技术从创造内容转向塑造物理世界,我们正站在AGI黎明前的临界点。开源社区不仅是技术实验场,更将成为智能时代新伦理体系的奠基者。
结语:技术民主化浪潮下的机遇
本月的开源生态展现出显著的技术下沉特征:Gaze-LLE通过冻结视觉编码器实现参数效率的指数级提升,StereoCrafter利用基础模型先验降低3D生成门槛。这些进展不仅加速了AIGC技术的普惠化,更预示着开源社区将成为下一代多模态基础设施的核心构建者。
当微软Phi-4与国产DeepSeek-V3同台竞技,我们正见证着一个去中心化智能时代的黎明。


















 1001
1001

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









