




🌞欢迎来到深度学习实战的世界
🌈博客主页:卿云阁💌欢迎关注🎉点赞👍收藏⭐️留言📝
🌟本文由卿云阁原创!
📆首发时间:🌹2025年2月6日🌹
✉️希望可以和大家一起完成进阶之路!
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢!
目录

引入
在深度学习的世界里,我们经常会听到一个问题:网络越深,效果一定越好吗?
其实,答案是否定的!如果你直接把网络层数加深,模型的训练反而可能变得更难,甚至出现
梯度消失 或 退化问题(深度越大,训练效果可能反而变差)。
ResNet(Residual Network,残差网络)就是为了解决这个问题而诞生的,它的核心思想是
加一条“捷径”,让数据可以跳跃传播!。
ResNet-18 是 ResNet 家族 的一员,它的数字 “18” 指的是网络总共有 18 层(主要是包含可学
习参数的卷积层和全连接层)。ResNet 的核心特点是 “残差连接”(Residual Connection),它能
让信息在网络中 跳跃 传播,避免梯度消失,让深层网络更容易训练。
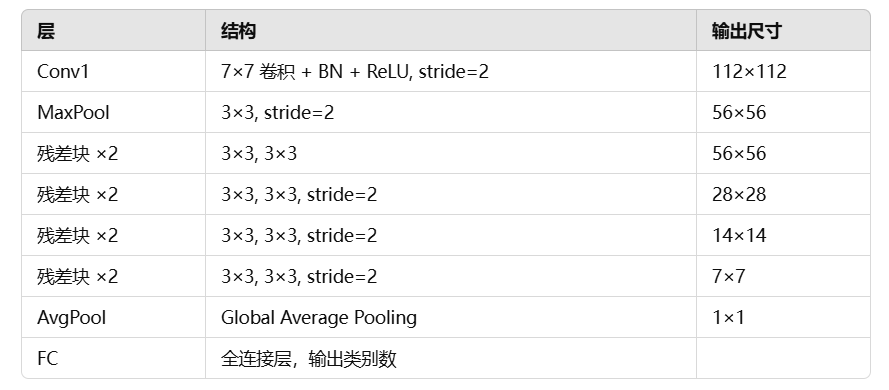
ResNet-18的网络简图如下图(假设网络的输入的张量的形状为3 × 64 × 64 ),如图resnet的结
构分为四个stage,完整的ResNet-18的结构图在最后。

ResNet-18 的基本架构如下:
🔹 这里的 残差块(Residual Block) 负责做特征提取,每个块内部包含两个 3×3 卷积。
🔹 跳跃连接(Shortcut)让数据既可以通过卷积层,也可以 直接“抄近路” 传递到下一层。
残差连接
假设 输入是 X,而普通 CNN 的目标是直接学一个映射 F(X),但 ResNet 让网络学的是 F(X) -
X,这样一来,我们可以重写成:
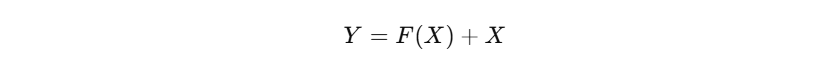
F(X) 是卷积层学习的内容(残差)。
X 是输入的跳跃连接(shortcut)。
F(X) + X 就是输出。
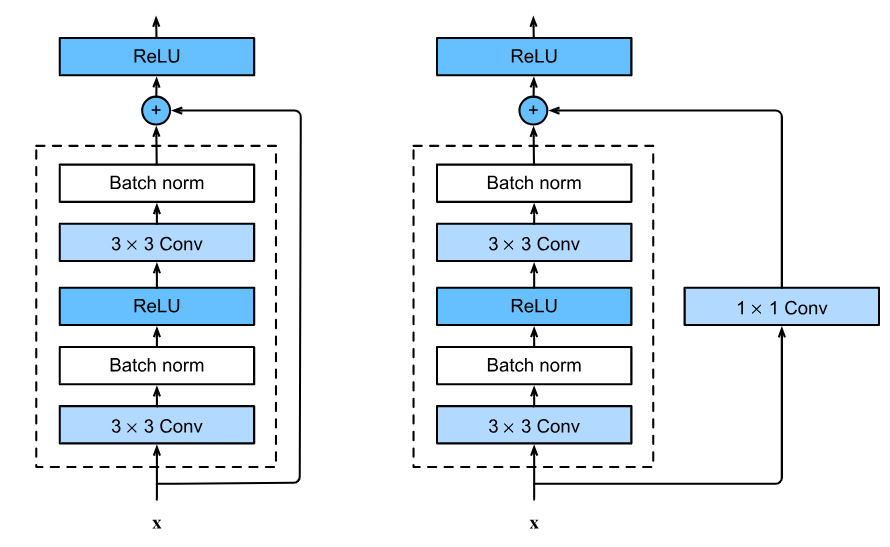
残差块通常包含两个卷积层,每个卷积层后面跟着批量归一化(Batch Normalization)和激
活函数(如ReLU)。这些层负责提取和转换输入特征。
为啥残差块有这两种模式呐?
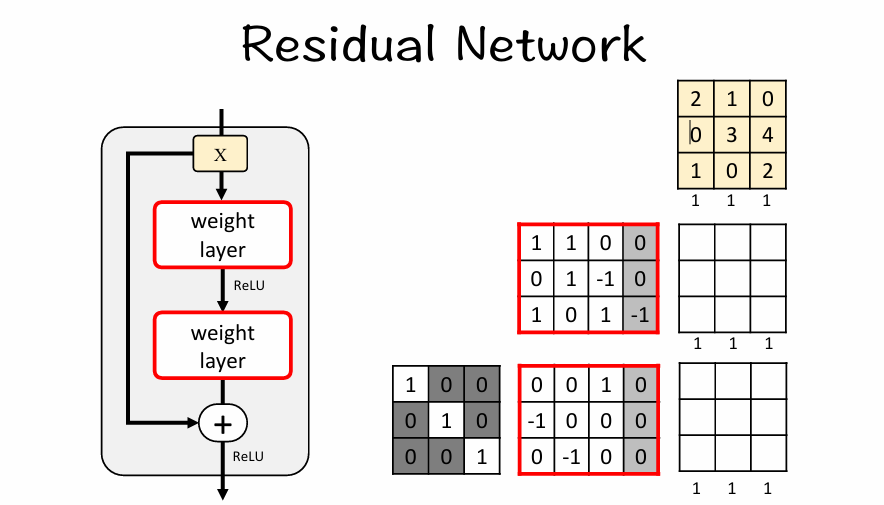
现在我们手动模拟一下残差块的运算:
【1】给定3 ×3的输入张量
【2】通过第一个卷积层,批量归一化,激活函数(ReLU)(负数变成0)
【3】通过第二个卷积层,批量归一化,激活函数(ReLU)(负数变成0)得到 F(X)
【4】F(X)+ X 得到最后的输出
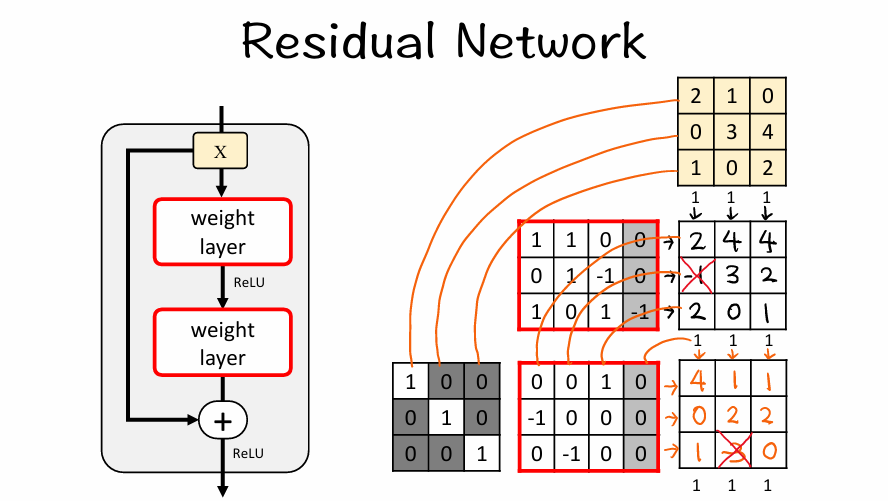
F(X)+ X 可以直接相加的前提的是两者的大小一样,通道数一样
所以当两者不一样的时候我们需要增加一个分支(1×1的卷积进行调整)(需要 shortcut 的情况)
可以通过设置1×1的卷积的卷积核的数量来调整通道数
可以通过设置1×1的卷积的填充padding=0来调整大小
啥时侯两者不一样鸭?
步长 ≠ 1 时,意味着 输入的尺寸会缩小,比如 stride=2 时 H × W 变为 H/2 × W/2。
由于 x 形状变小了,我们需要用 1×1 卷积 让 x 也变小,以便与 F(x) 匹配。
in_channels != out_channels:
输入通道数 ≠ 输出通道数,意味着 x 的通道数 不能直接加到 F(x) 上。
例如:之前的特征图有 64 个通道,当前块的 F(x) 计算出了 128 个通道。
这样 x 是 64 通道,而 F(x) 是 128 通道,无法相加。解决办法:用 1×1 卷积 升维/降维,把 x 变
成 F(x) 一样的通道数。
代码实现
# 1️⃣ 定义残差块(Basic Block)
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 残差连接:如果输入通道数不匹配,则使用 1x1 卷积调整
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
identity = self.shortcut(x)
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += identity
return F.relu(out)
def _make_layer(self, out_channels, num_blocks, stride):
layers = [] # 创建一个空列表,用于存储这一层的 BasicBlock
# 第一个 BasicBlock 的 stride 为输入参数 stride,这里是第一个块
layers.append(BasicBlock(self.in_channels, out_channels, stride))
# 更新当前通道数
self.in_channels = out_channels
# 接下来的 num_blocks - 1 个 BasicBlock 都使用 stride=1
for _ in range(1, num_blocks):
layers.append(BasicBlock(out_channels, out_channels, stride=1))
# 将所有的 BasicBlock 堆叠成一个 nn.Sequential 模块
return nn.Sequential(*layers)
初始化 layers 列表
layers 列表用于存储构建的每一个 BasicBlock,最终返回的是一个 nn.Sequential(一个有序的模块容器)。
添加第一个 BasicBlock:
layers.append(BasicBlock(self.in_channels, out_channels, stride))
第一个 BasicBlock 使用了传入的 stride,并且将当前的输入通道数(self.in_channels)作为输入通道数,输出通道数为 out_channels。
stride 影响卷积操作的步长,通常第一个 BasicBlock 需要通过卷积来改变特征图的尺寸(例如降采样)。
更新当前通道数:
self.in_channels = out_channels
每次添加一个 BasicBlock 后,输入的通道数变为该 BasicBlock 输出的通道数(即 out_channels)。
添加后续的 BasicBlock:
for _ in range(1, num_blocks):
从第 2 个 BasicBlok 开始,使用 stride=1,即不改变特征图尺寸。
这里是为了保持相同的空间分辨率,通常在残差网络的后续块中使用步长为 1 来保证特征图尺寸不变。
返回 nn.Sequential:
return nn.Sequential(*layers)
最后通过 nn.Sequential 将所有的 BasicBlock 按顺序组合成一层(layer)。nn.Sequential 会按照列表中的顺序依次执行每个 BasicBlock。初始化 layers 列表
layers 列表用于存储构建的每一个 BasicBlock,最终返回的是一个 nn.Sequential(一个有序
的模块容器)。
添加第一个 BasicBlock:
layers.append(BasicBlock(self.in_channels, out_channels, stride))
第一个 BasicBlock 使用了传入的 stride,并且将当前的输入通道数(self.in_channels)作为输
入通道数,输出通道数为 out_channels。
stride 影响卷积操作的步长,通常第一个 BasicBlock 需要通过卷积来改变特征图的尺寸(例如
降采样)。
更新当前通道数:
self.in_channels = out_channels
每次添加一个 BasicBlock 后,输入的通道数变为该 BasicBlock 输出的通道数(out_channels)。
添加后续的 BasicBlock:
for _ in range(1, num_blocks):
从第 2 个 BasicBlok 开始,使用 stride=1,即不改变特征图尺寸。这里是为了保持相同的空间
分辨率,通常在残差网络的后续块中使用步长为 1 来保证特征图尺寸不变。
返回 nn.Sequential:
return nn.Sequential(*layers)
最后通过 nn.Sequential 将所有的 BasicBlock 按顺序组合成一层(layer)。nn.Sequential 会
按照列表中的顺序依次执行每个 BasicBlock。
实战
网络结构代码(network.py)
import torch
import torch.nn as nn
import torch.nn.functional as F
class BasicBlock(nn.Module):
def __init__(self, in_channels, out_channels, stride=1):
super(BasicBlock, self).__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
# 只有在通道数不匹配或者 stride 不等于 1 时,才需要 1x1 卷积层匹配维度
self.shortcut = nn.Sequential()
if stride != 1 or in_channels != out_channels:
self.shortcut = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels)
)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
out += self.shortcut(x) # 残差连接
return F.relu(out)
class ResNet18(nn.Module):
def __init__(self, num_classes=2):
super(ResNet18, self).__init__()
self.in_channels = 64
self.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.layer1 = self._make_layer(64, 2, stride=1)
self.layer2 = self._make_layer(128, 2, stride=2)
self.layer3 = self._make_layer(256, 2, stride=2)
self.layer4 = self._make_layer(512, 2, stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512, num_classes)
def _make_layer(self, out_channels, num_blocks, stride):
layers = []
layers.append(BasicBlock(self.in_channels, out_channels, stride))
self.in_channels = out_channels # 更新通道数,确保匹配后续的 block
for _ in range(1, num_blocks):
layers.append(BasicBlock(out_channels, out_channels, stride=1))
return nn.Sequential(*layers)
def forward(self, x):
out = F.relu(self.bn1(self.conv1(x)))
out = self.layer1(out)
out = self.layer2(out)
out = self.layer3(out)
out = self.layer4(out)
out = self.avgpool(out)
out = torch.flatten(out, 1)
out = self.fc(out)
return out
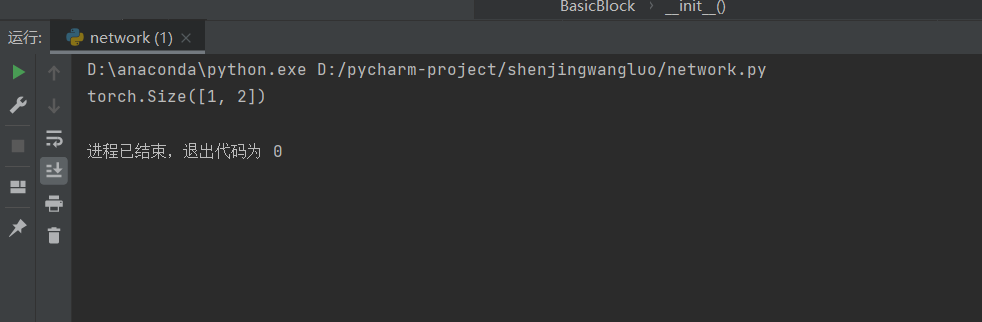
# 测试网络
if __name__ == "__main__":
model = ResNet18(num_classes=2)
x = torch.randn(1, 3, 32, 32)
print(model(x).shape) # 应该输出 torch.Size([1, 2])
训练(train.py)
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset
from torchvision.datasets import ImageFolder
from tqdm import tqdm
from network import ResNet18 # 确保你在 network.py 中正确定义了 ResNet18
# 定义水质数据集
class WaterQualityDataset(Dataset):
def __init__(self, root, transform=None):
self.dataset = ImageFolder(root, transform=transform)
def __getitem__(self, index):
return self.dataset[index]
def __len__(self):
return len(self.dataset)
# 数据预处理
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
])
# 读取数据集
train_dataset = WaterQualityDataset('D:/dataset1', transform=transform)
test_dataset = WaterQualityDataset('D:/dataset1', transform=transform)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=0)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=0)
# 初始化 ResNet18 模型
model = ResNet18(num_classes=2) # 二分类任务
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model.to(device)
# 定义损失函数和优化器
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# 训练模型
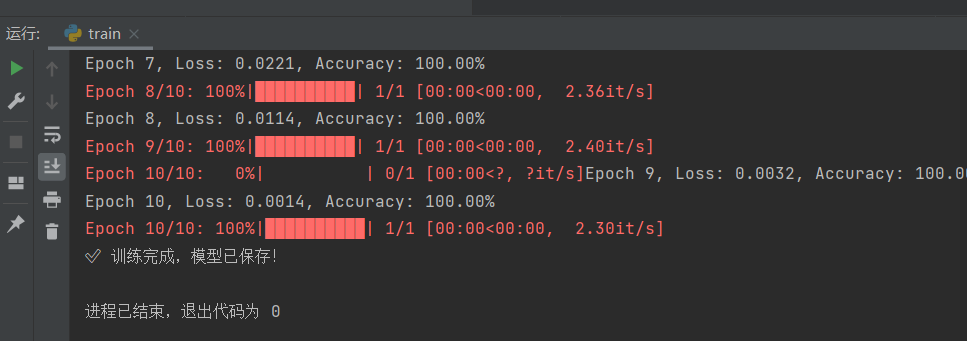
epochs = 10
for epoch in range(epochs):
model.train()
running_loss = 0.0
correct = 0
total = 0
for images, labels in tqdm(train_loader, desc=f'Epoch {epoch + 1}/{epochs}'):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
running_loss += loss.item()
_, predicted = torch.max(outputs, 1)
correct += (predicted == labels).sum().item()
total += labels.size(0)
accuracy = correct / total * 100
print(f'Epoch {epoch + 1}, Loss: {running_loss / len(train_loader):.4f}, Accuracy: {accuracy:.2f}%')
# 保存训练好的模型
torch.save(model.state_dict(), "water_quality_resnet18.pth")
print("✅ 训练完成,模型已保存!")
评估(evaluation.py)
import torch
import torchvision.transforms as transforms
from torch.utils.data import DataLoader
from torchvision.datasets import ImageFolder
from network import ResNet18 # 确保 network.py 定义了 ResNet-18
import os
from tqdm import tqdm
# 1. 设置设备(优先使用 GPU)
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 2. 数据预处理(与训练时一致)
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
])
# 3. 加载测试数据集
data_path = 'D:/dataset1' # 确保测试集路径正确
if not os.path.exists(data_path):
raise FileNotFoundError(f"❌ 数据集路径 {data_path} 不存在,请检查!")
test_dataset = ImageFolder(data_path, transform=transform)
test_loader = DataLoader(test_dataset, batch_size=32, shuffle=False, num_workers=0)
# 4. 加载训练好的模型
model_path = 'water_quality_resnet18.pth' # 训练时保存的模型权重
if not os.path.exists(model_path):
raise FileNotFoundError(f"❌ 模型文件 {model_path} 不存在,请检查!")
model = ResNet18(num_classes=2) # 你的任务是 2 类分类
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device)
model.eval()
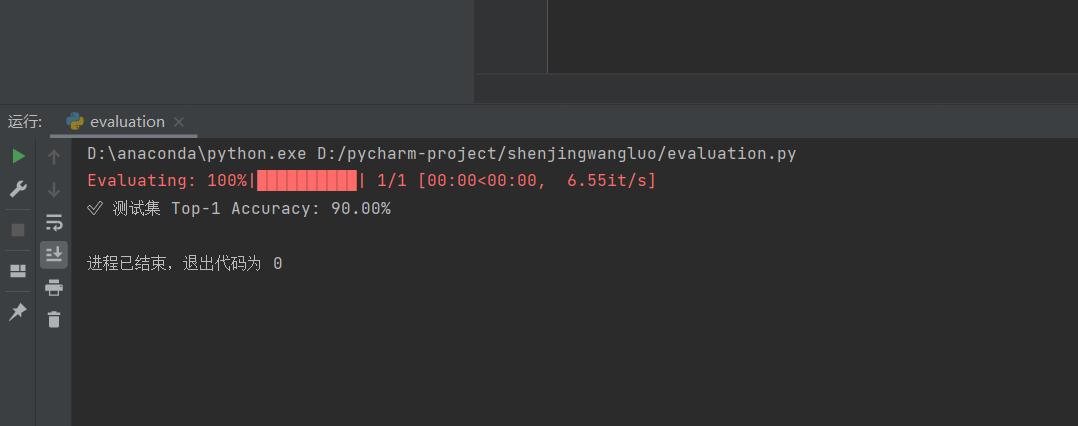
# 5. 计算 Top-1 准确率
correct = 0
total = 0
with torch.no_grad():
for images, labels in tqdm(test_loader, desc="Evaluating"):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1) # 取最大概率类别
correct += (predicted == labels).sum().item()
total += labels.size(0)
# 6. 输出最终准确率
accuracy = correct / total * 100
print(f"✅ 测试集 Top-1 Accuracy: {accuracy:.2f}%")
UI.py:可视化的UI页面
import sys
import torch
import torchvision.transforms as transforms
from PyQt5.QtWidgets import QApplication, QWidget, QLabel, QPushButton, QFileDialog, QVBoxLayout, QMessageBox
from PyQt5.QtGui import QPixmap, QImage
from torchvision.datasets import ImageFolder
from PIL import Image
from network import ResNet18 # 确保 network.py 里有 ResNet-18
import os
# 1. 设置设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# 2. 预处理转换(与训练时保持一致)
transform = transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor(),
])
# 3. 加载模型
model_path = 'water_quality_resnet18.pth' # 你的训练模型路径
if not os.path.exists(model_path):
raise FileNotFoundError(f"❌ 模型文件 {model_path} 不存在,请检查!")
model = ResNet18(num_classes=2) # 你的分类任务是 2 类
model.load_state_dict(torch.load(model_path, map_location=device))
model.to(device)
model.eval()
# 4. 定义 UI 界面
class WaterQualityApp(QWidget):
def __init__(self):
super().__init__()
self.setWindowTitle("水质分类 - ResNet18")
self.setGeometry(200, 200, 400, 500)
self.image_label = QLabel(self)
self.image_label.setFixedSize(300, 300)
self.select_button = QPushButton("选择图片", self)
self.select_button.clicked.connect(self.load_image)
self.predict_button = QPushButton("预测", self)
self.predict_button.clicked.connect(self.predict)
self.predict_button.setEnabled(False)
self.result_label = QLabel("分类结果:", self)
layout = QVBoxLayout()
layout.addWidget(self.image_label)
layout.addWidget(self.select_button)
layout.addWidget(self.predict_button)
layout.addWidget(self.result_label)
self.setLayout(layout)
self.image_path = None
def load_image(self):
file_dialog = QFileDialog()
file_path, _ = file_dialog.getOpenFileName(self, "选择图片", "", "Images (*.png *.jpg *.jpeg)")
if file_path:
self.image_path = file_path
pixmap = QPixmap(file_path)
self.image_label.setPixmap(pixmap.scaled(300, 300))
self.predict_button.setEnabled(True)
def predict(self):
if self.image_path is None:
QMessageBox.warning(self, "警告", "请先选择一张图片!")
return
# 加载图片并进行预处理
image = Image.open(self.image_path).convert("RGB")
image = transform(image).unsqueeze(0).to(device)
# 进行推理
with torch.no_grad():
output = model(image)
_, predicted = torch.max(output, 1)
# 解析结果
class_labels = ["Ⅰ类水", "Ⅱ类水"] # 请替换为你的数据集类别
result_text = f"分类结果:{class_labels[predicted.item()]}"
self.result_label.setText(result_text)
# 5. 运行应用
if __name__ == "__main__":
app = QApplication(sys.argv)
window = WaterQualityApp()
window.show()
sys.exit(app.exec_())




















 9532
9532

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











