







参考 : 哔哩哔哩8天Hadoop大数据
参考: 大数据学习路径
Hadoop出现
-
痛点:数据量大,需要并发,单机中采用多线程、多进程等,但是依然还是一台机器,最多也就充分利用一个计算机资源,需要集群并发处理,多个进程分布到多个机器中要比在单个机器中更复杂,涉及网络通信、数据之间同步等
-
解决:Hadoop框架的出现解决这些海量数据在不同节点计算、存储、分析、调度等问题,让研发人员更关注业务逻辑,降低研发成本。
note:
hadoop不是一个存储大量数据的数据库,里面包含数据库的功能,它是一个解决海量数据分布式计算、存储的技术框架的生态系统,说白了,里面包含很多功能,数据库只是其中一个。
Hadoop中的技术框架(组件)
- HDFS :解决海量数据分布式存储的问题,将数据存储在多个节点上的文件系统
- MapReduce:解决分布式的海量数据并行处理的分析、计算
- Yarn:为上层应用提供统一的资源管理和调度,将MapReduce程序分配到集群中
HDFS
HDFS出现之前的一些解决方案:例如:NFS(网络文件共享系统)
将其他节点上的文件夹共享,挂载到一个总电脑的目录下,实现分布式的海量文件存储,但是存在一些问题:
- 如果一个节点出现故障,那么这个节点上的文件丢失了
- 如果需要对某个节点上的数据进行计算、分析,那么其他节点空闲了,当前的节点过载了
HDFS的解决方案:
- 把大的文件切成小的块,放在不同的节点(Datanotes),也就是一个大的文件分布在不同节点中
- 每个块有多个副本(replication),解决了NFS的一个节点损坏文件丢失的问题,提高数据可靠性;另一个好处是如果多个用户访问这个文件,可以分配用户到不同的副本,提高数据吞吐量(并发)
- 客户端访问数据只知道路径,并不知到一个文件被切成多少块,分配到哪些节点里面,所以中间会有“一个文件路径和哪些块在哪些节点中”的映射管理(Namenode),所以客户端必须先访问Namenode,然后再去Datanode中读写。
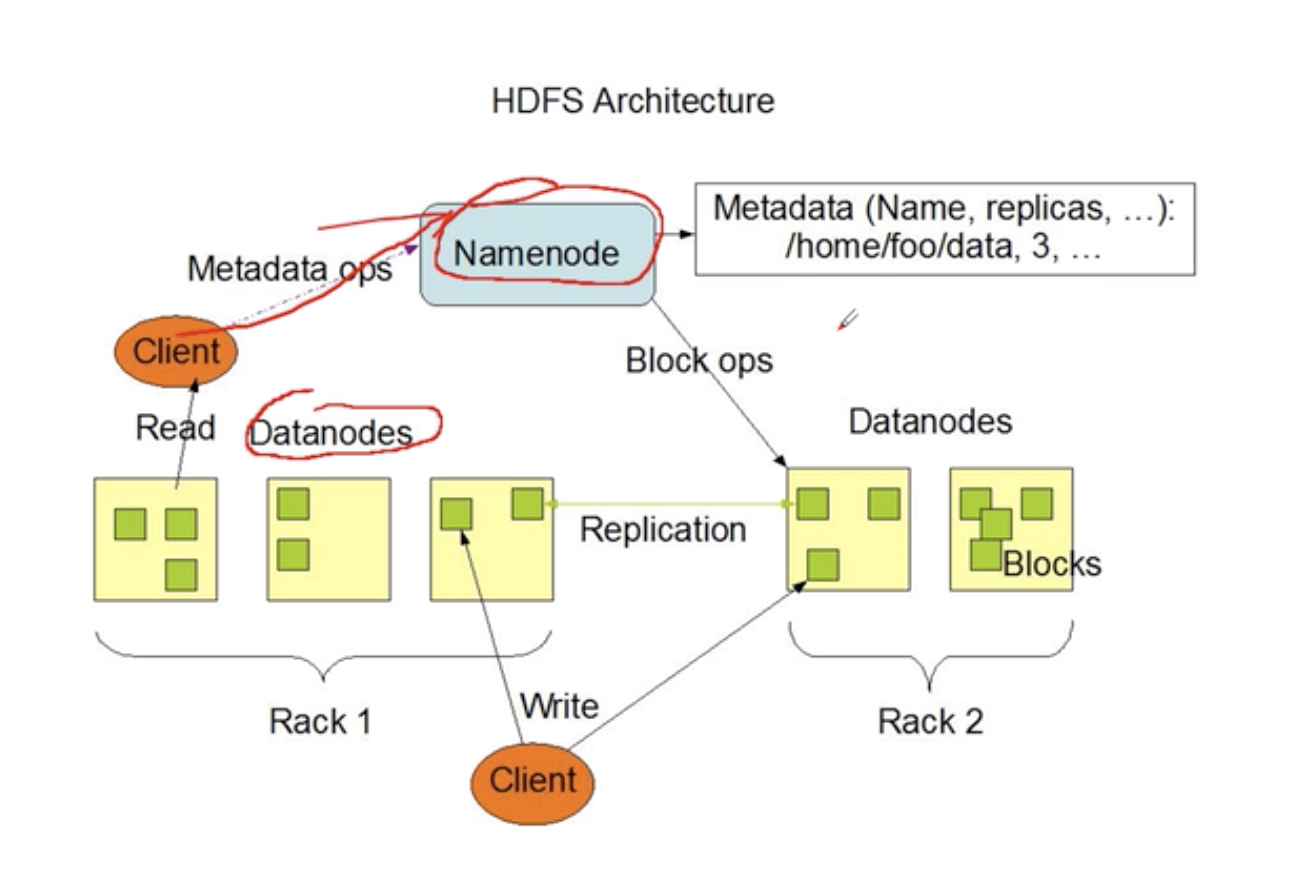
百度网盘等应用就是这个原理
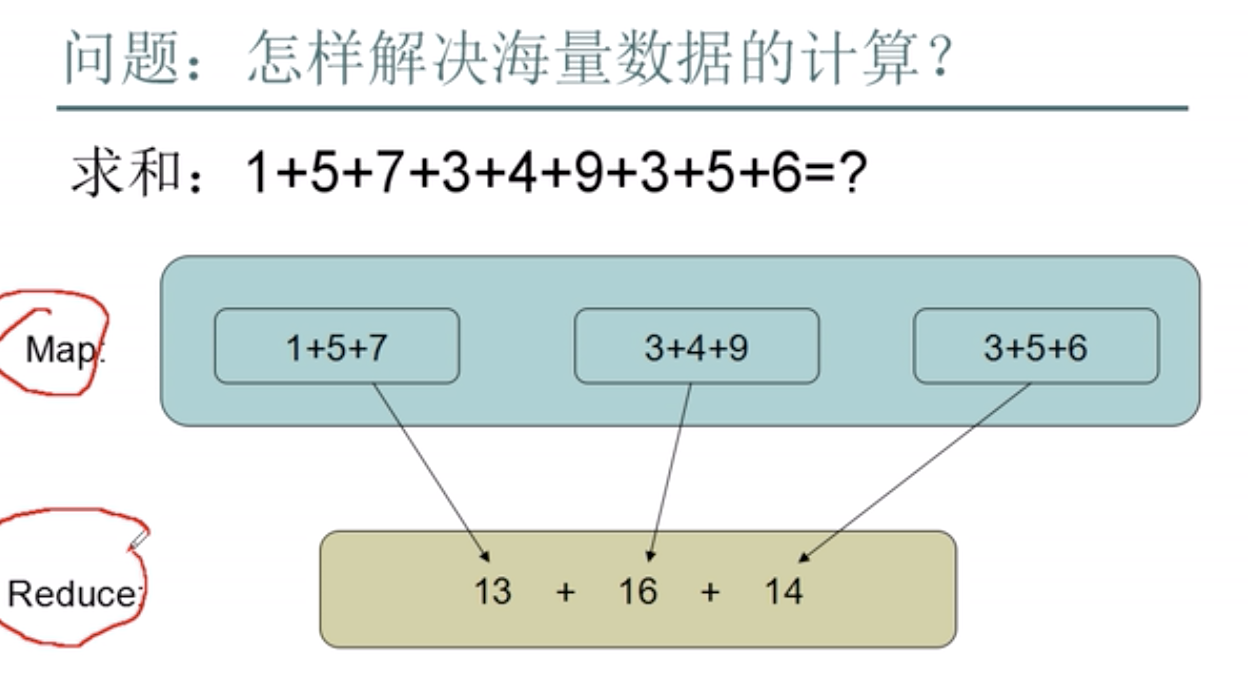
MapReduce
- Map程序:计算节点的局部结果,在分布在每个节点本地运行的
- Reduce程序:通过网络将Map运行的中间结果取回来,再计算全局的结果,可以做多个Reduce分组统计(取决于业余逻辑)















 1024
1024











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









