







 本文介绍了Hadoop的MapReduce框架,包括其工作原理、编程规范和数据输入处理。MapReduce适用于大规模数据计算,通过Map和Reduce阶段进行分布式处理。文章详细讲解了InputFormat的切片、TextInputFormat和CombineTextInputFormat,以及Shuffle机制中的分区。此外,还阐述了自定义Partitioner的重要性以及如何配置ReduceTask数量。
本文介绍了Hadoop的MapReduce框架,包括其工作原理、编程规范和数据输入处理。MapReduce适用于大规模数据计算,通过Map和Reduce阶段进行分布式处理。文章详细讲解了InputFormat的切片、TextInputFormat和CombineTextInputFormat,以及Shuffle机制中的分区。此外,还阐述了自定义Partitioner的重要性以及如何配置ReduceTask数量。
介绍
mapreduce 是分布式的计算的编程框架,核心功能是将用户编写的业务逻辑代码和自带的默认组件整合成一个完整的分布式程序,并发运行在hadoop集群上。
优点:
- 易用:用户只关心业务,底层代码框架已实现
- 易扩展:可动态增加服务器解决计算资源不够的问题
- 高容错性:任一节点挂掉,可提前将计算任务转移到其他节点
- 适合海量数据计算(TB/PB), 几千台服务器共同计算
缺点:
- 不擅长实时计算,mysql 擅长
- 不擅长流式计算,spark flink 擅长
- 不擅长有向图无环图计算(一个节点的计算依赖上一个节点的计算结果),spark擅长
工作原理
MapReduce 的过程分成两个部分:
- Map在每个节点上做block的局部处理,处理完交给Reduce节点
- Reduce节点做汇总工作
例子:统计单词的逻辑图
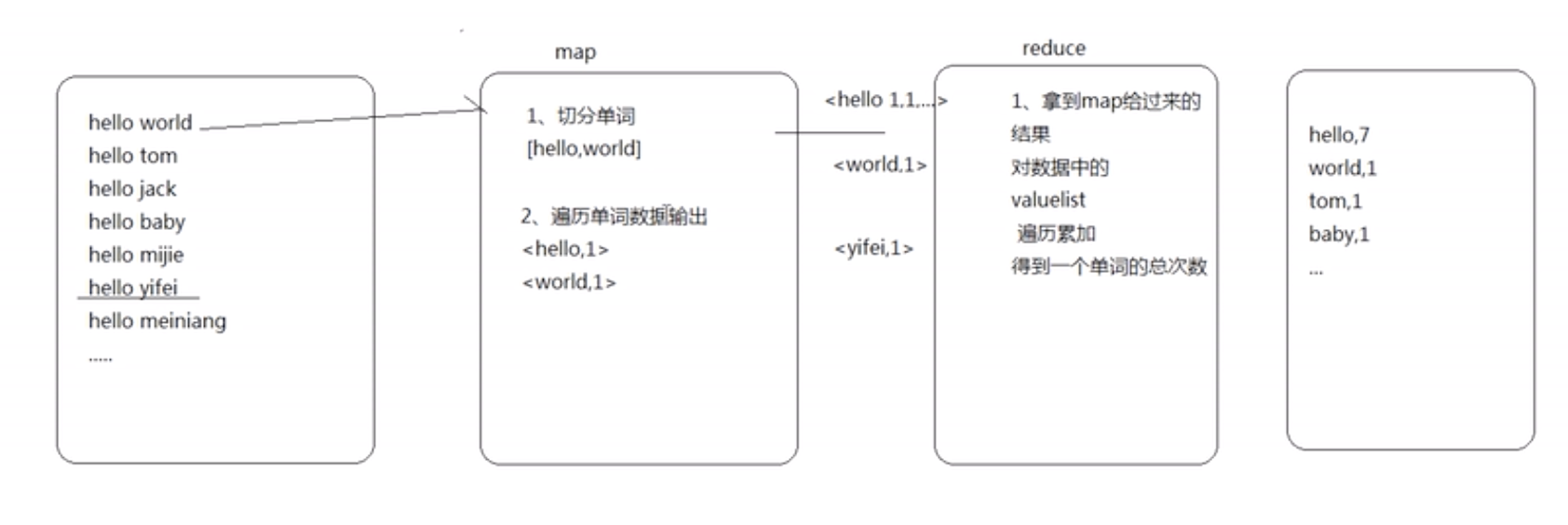
编程规范
MapReduce程序分为3个部分:Mapper、Reducer、Driver:
Mapper阶段:
- 用户自己定义的mapper类继承系统的Mapper
- Mapper输入的数据是 key-v
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









