






本节介绍各式各样的Self-attention的技术
预备知识:见Lecture 4(Preparation):Self-attention部分
回顾Self-attention的知识:Self-attention需要处理输入的sequence,设这个sequence的长度为N。做Self-attention的时候会产生N个key的vector和N个query的vector,它们两两之间要做dot product,一共要做N^2次dot product。把N^2次dot product的结果集合起来就得到一个N*N大小的Attention Matrix。
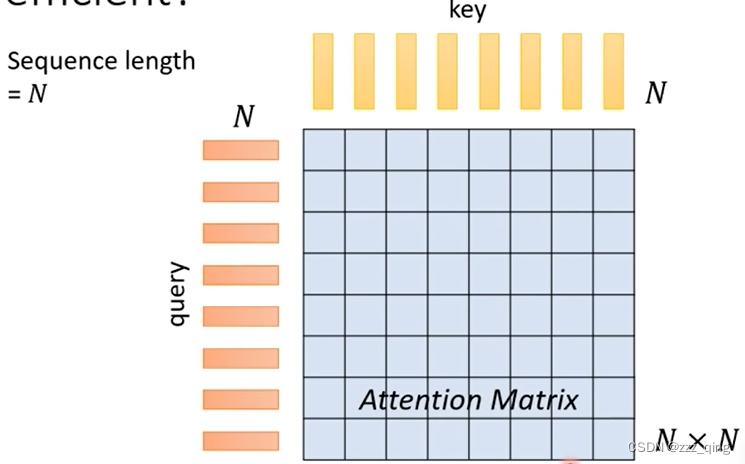
Self-attention的痛点是当input sequence非常长的时候,即N非常大的时候,要得到N*N的Attention Matrix,运算量会非常惊人。
下面介绍加速计算Attention Matrix的方法:
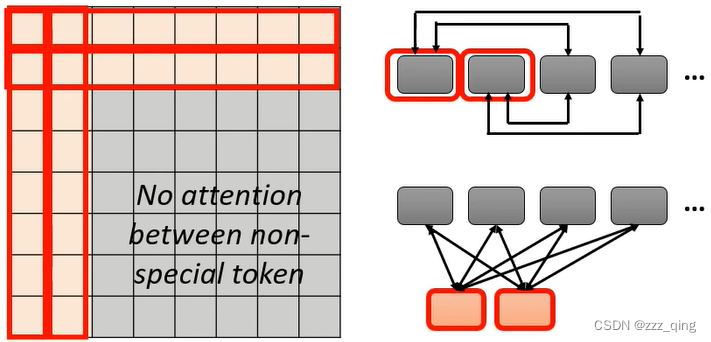
① Local Attention/Truncated Attention
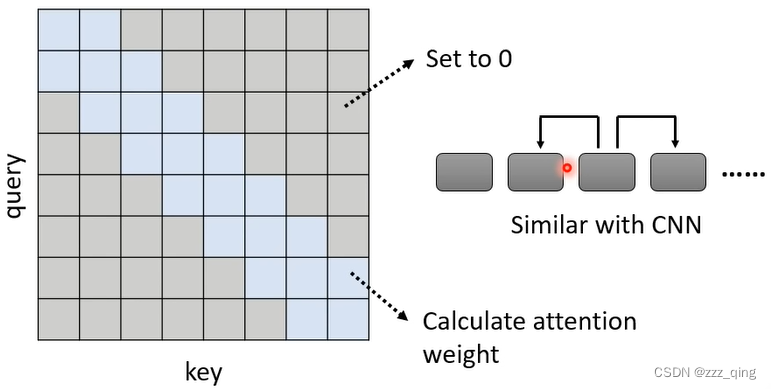
② Stride Attention
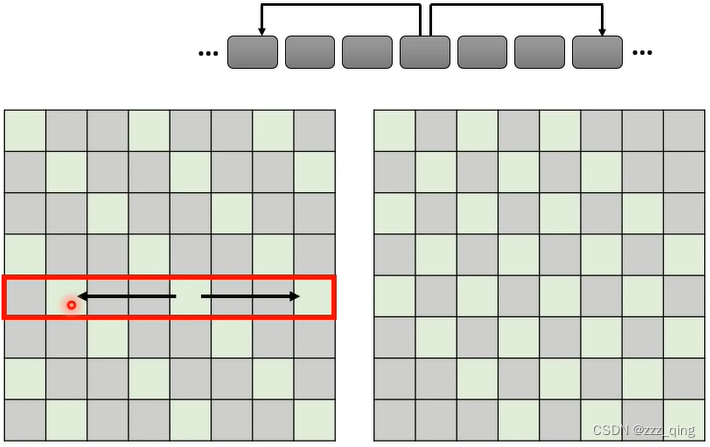
③ Global Attention
Add special token into original sequence
- Attend to every token - collect global information
- Attended by every token - it knows global information
可以将上面这些方法组合起来使用,在Multi-head Self-attention中,不同的head使用不同的方法:
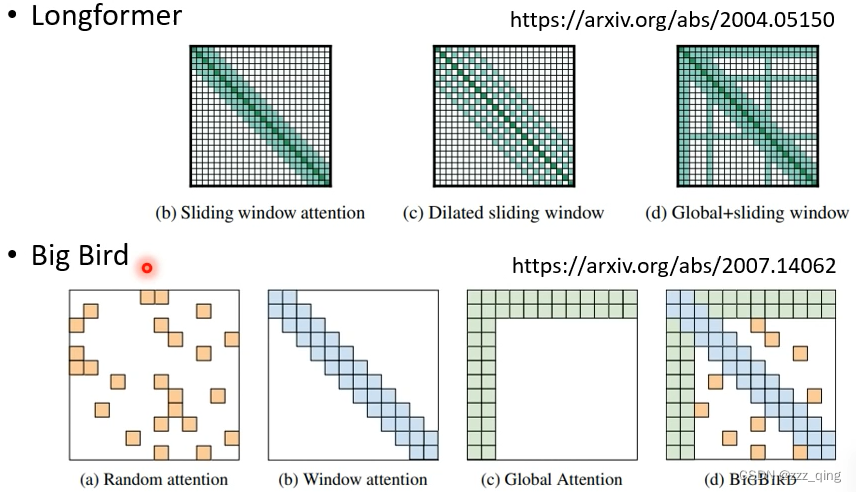
上面三种方法都是人为设定的,由人来规定Attention Matrix哪些位置需要计算,哪些位置直接补0。但是人为的设定不一定能得到最好的结果。
④ Clustering

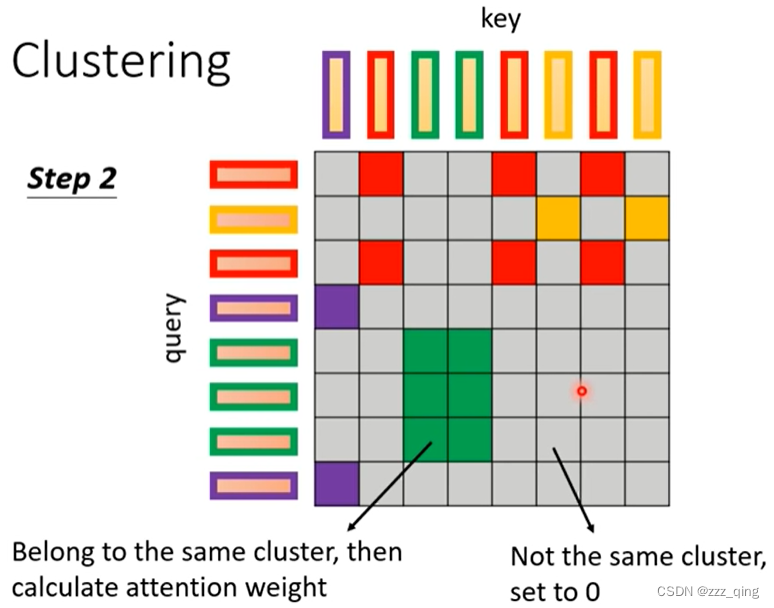
⑤ Learnable Patterns

以上五种方法都会产生一个N*N的Attention Matrix,Linformer的文章中指出Attention Matrix里会有很多redundant的columns,如下图,所以我们并不需要一个N*N的Attention Matrix,里边会有很多重复的资讯:
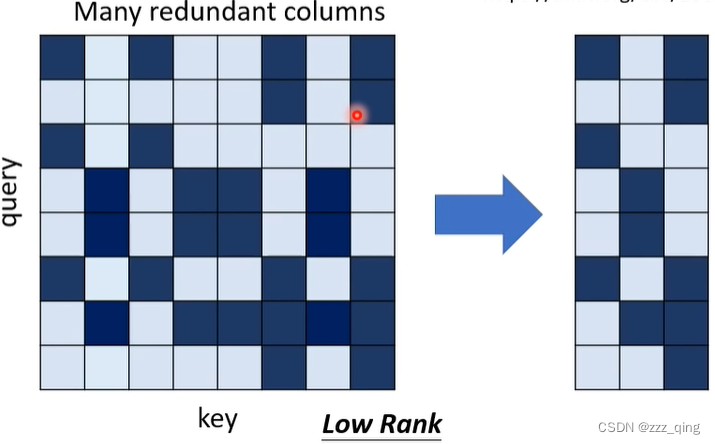
⑥ 减少Attention Matrix的大小
通过减少key的数量来减少Attention Matrix的大小。query在有的情况下可以减少,有的情况下不可以。当输入N个sequence,输出也是N个sequence的时候,减少query会改变输出的数量,此时query不可以减少。
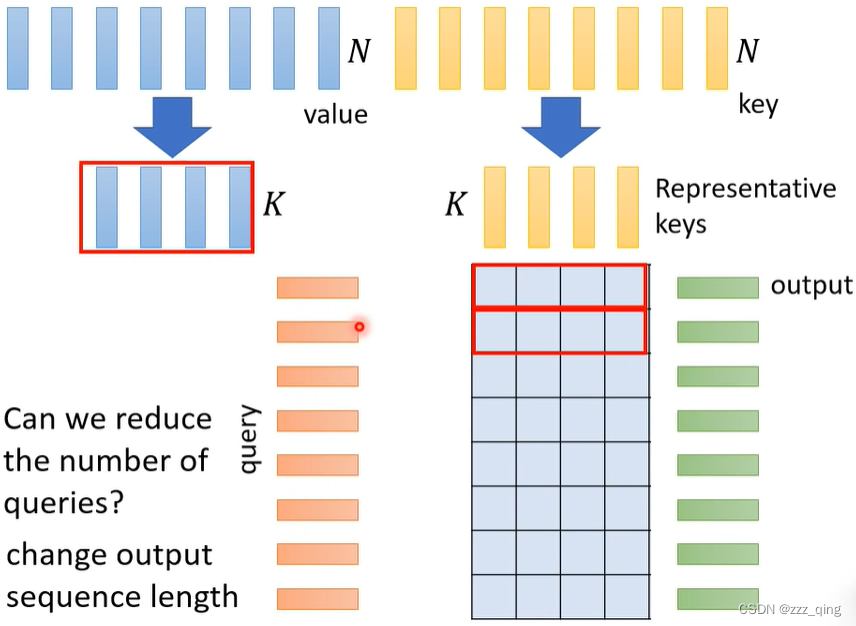
有两种方式可以减少key的数量,如下图:
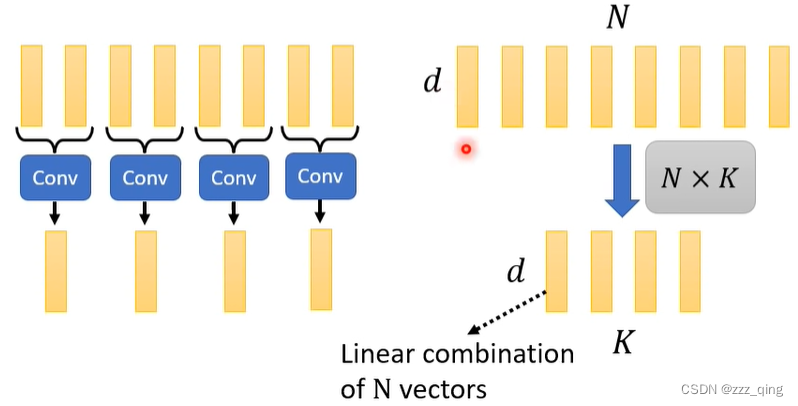
⑦ 改变矩阵计算的顺序
Attention Mechanism是由三个矩阵相乘得到的:
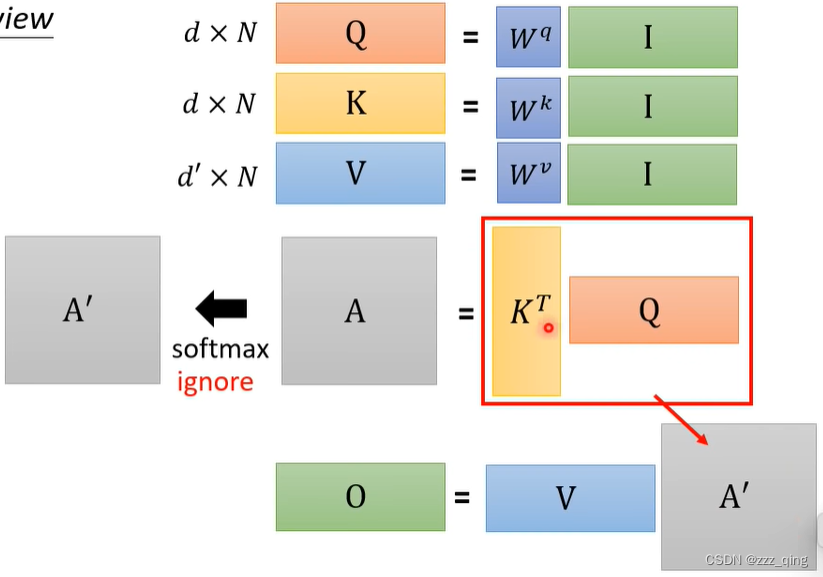
忽略掉softmax这一过程,把矩阵相乘顺序由V*(KT*Q)变为(V*KT)*Q,可加速运算:
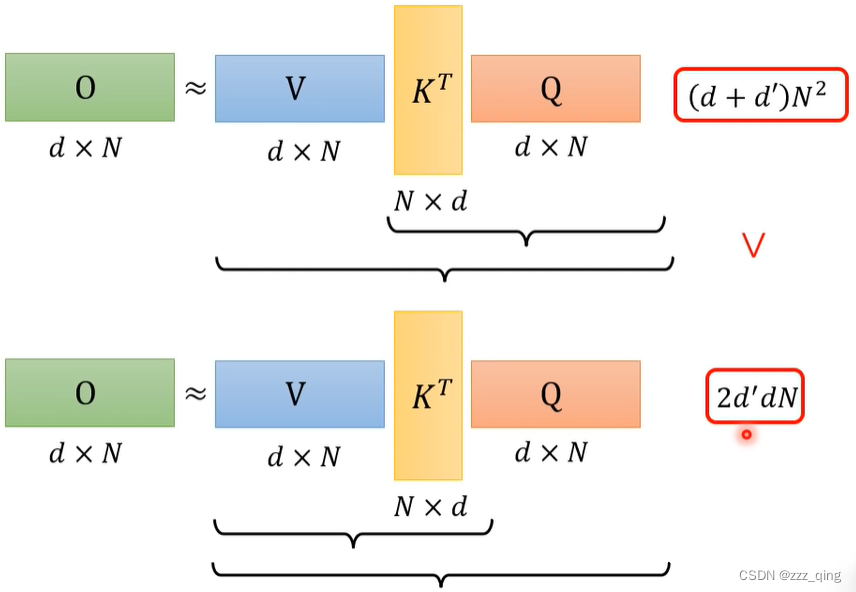
把softmax加回来,推导可得输出的计算公式如下,计算所有的输出(所有的bi)时,每个bi计算公式中黄色和蓝色的矩阵都是相同的,所以分别只需要计算一次就可以得到黄色和蓝色的矩阵,后续直接用这两个矩阵即可:
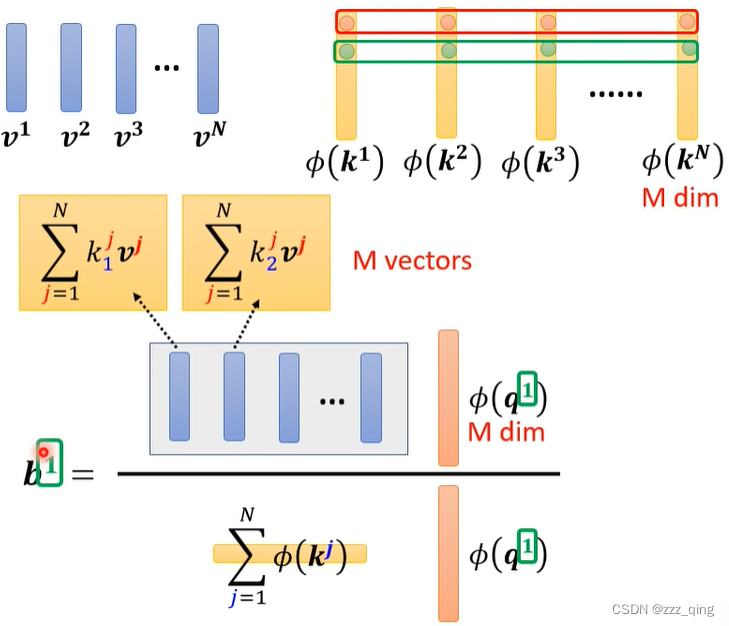
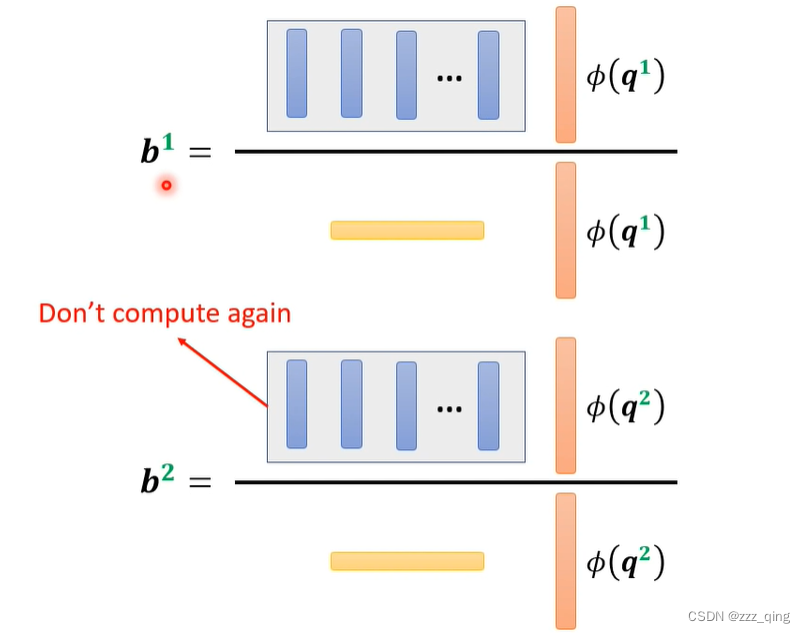
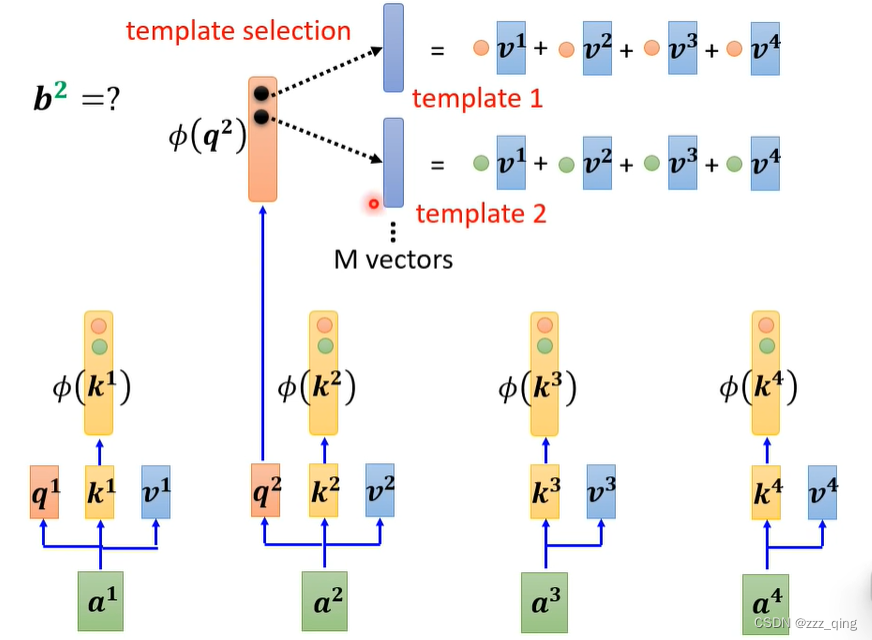
⑧ 不一定要使用q和k计算产生Attention Matrix——Synthesizer
把Attention Matrix里的元素当做network的parameters:

⑨ Attention-free
把Attention去掉,下面是一些Attention-free的方法:
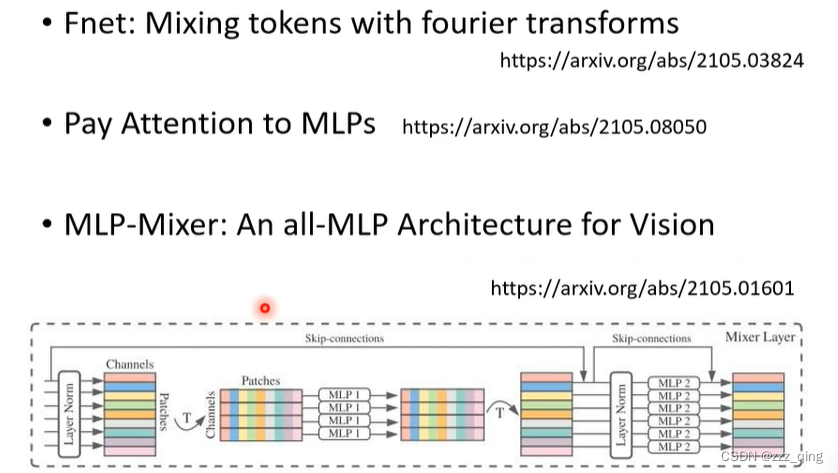
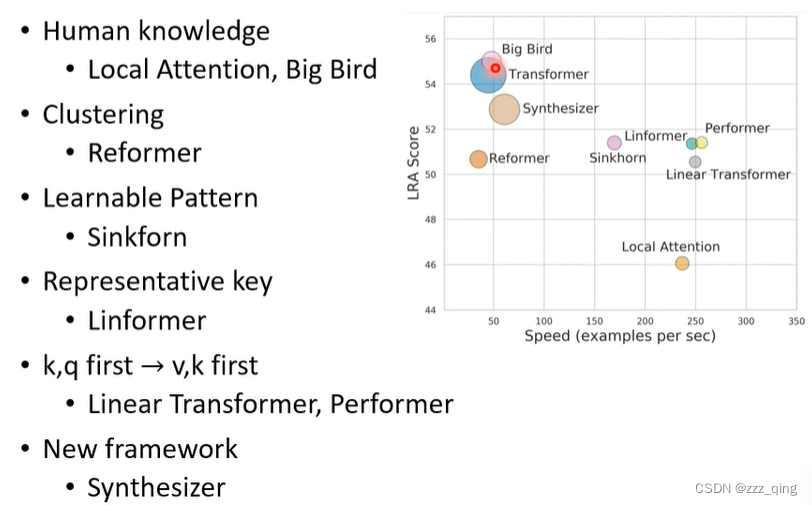
一系列Self-attention方法的对比:















 1165
1165











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









