







Self-attention,自注意力机制
词向量关联性计算:Dot-product、Inner-product
(自己与自己计算关联性?)
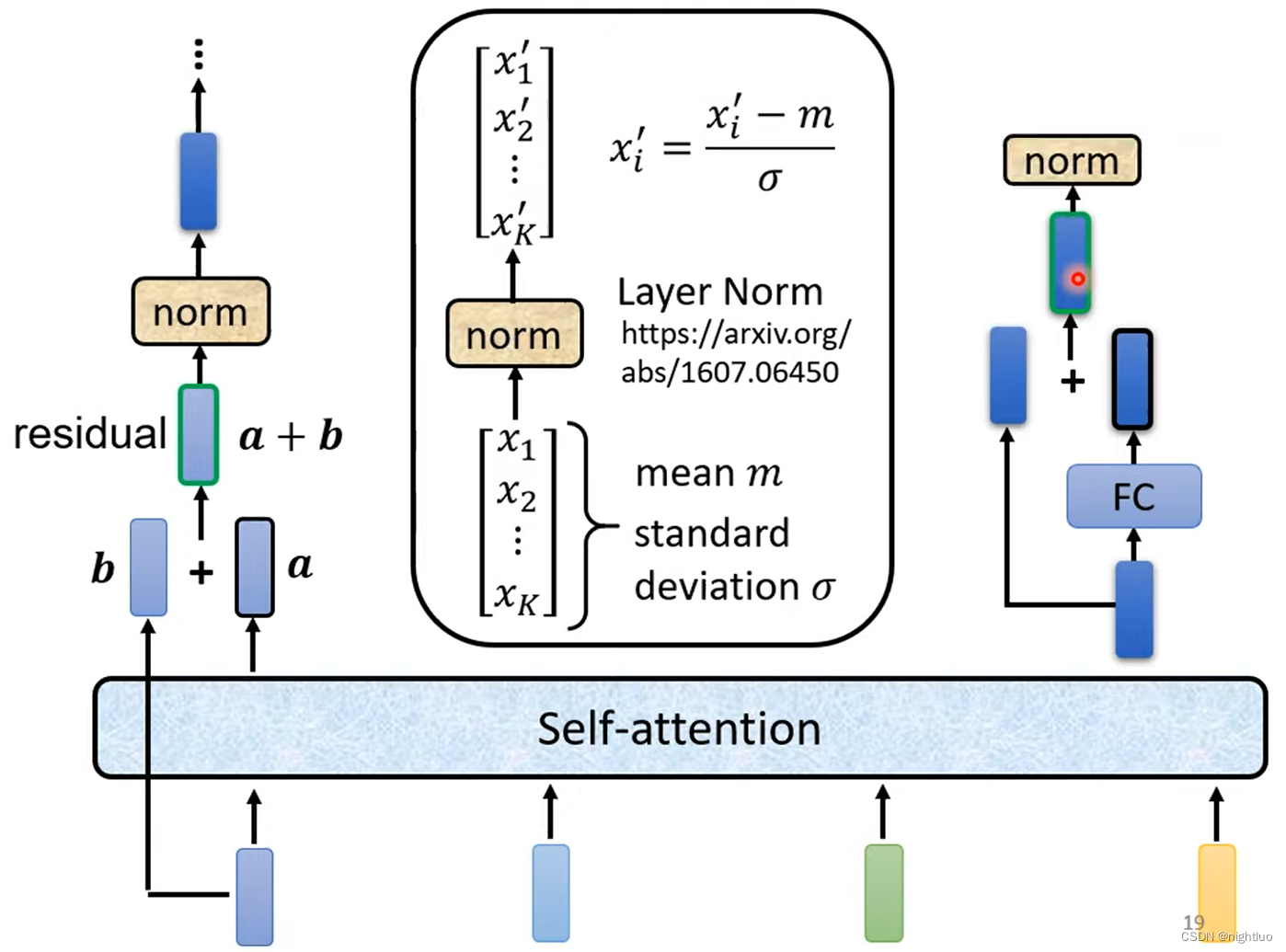
Batch Normalization
Pytorch 在 Training 过程中将持续计算一个 moving avrage
Internal Covariate Shift
Transformer
Encoder的Block
Decoder自己决定输出的向量的长度
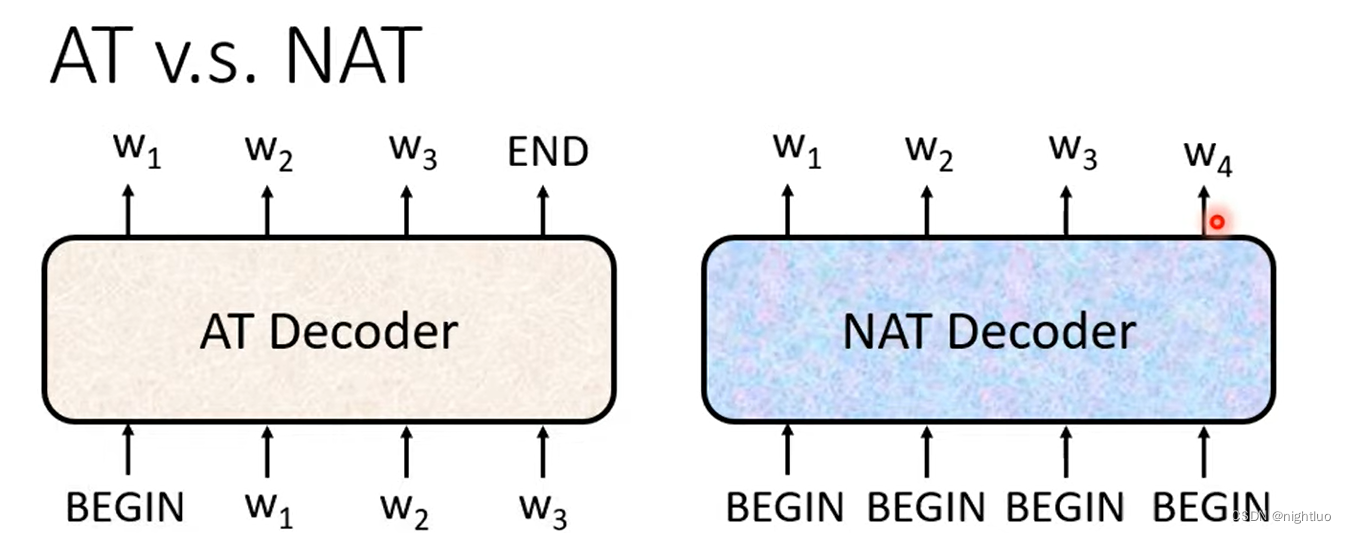
NAT:
- parallel 平行化
- controllable output length 输出长度可控
Tricks
- Copy Mechanism
- Guided Attention:Monotonic Attention、Location-aware attention
- Beam Search: Greedy Decoding
- Scheduled Sampling
BLEU score
Sequence Labeling
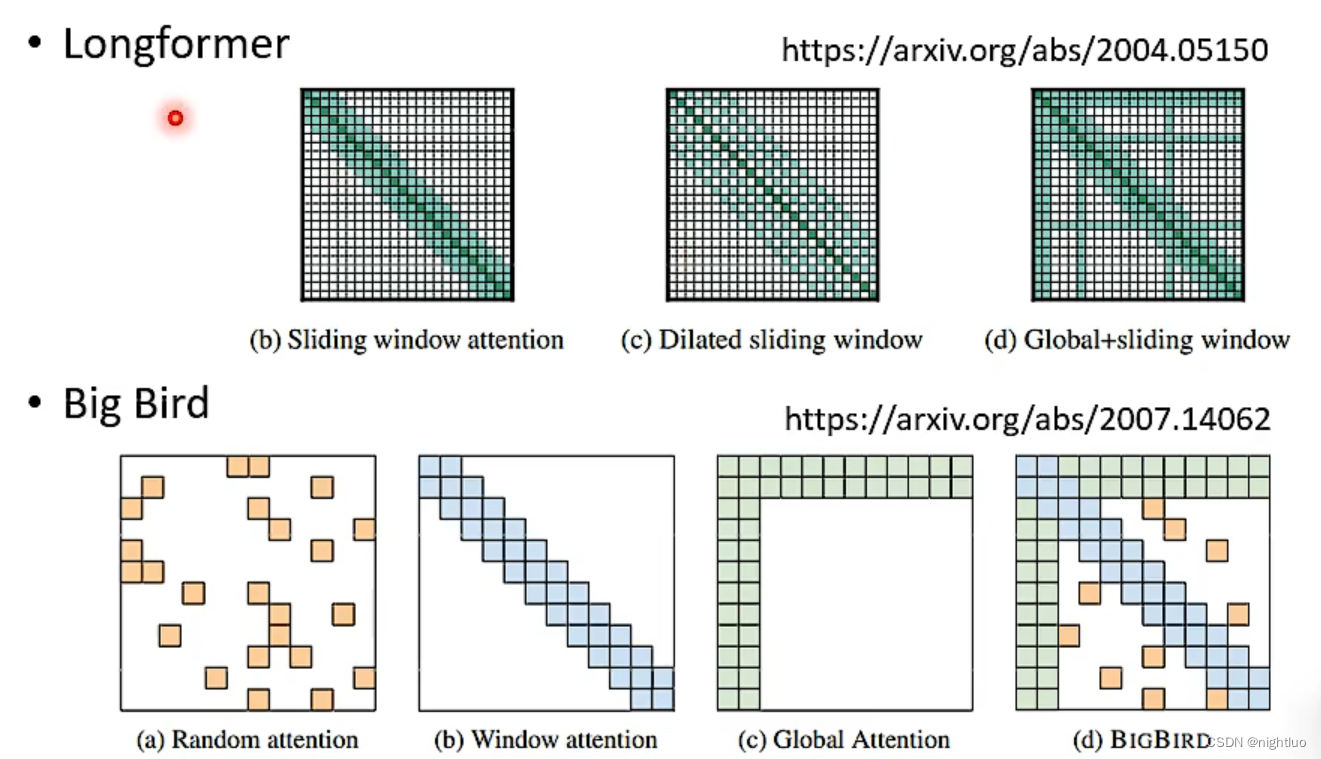
类似于卷积
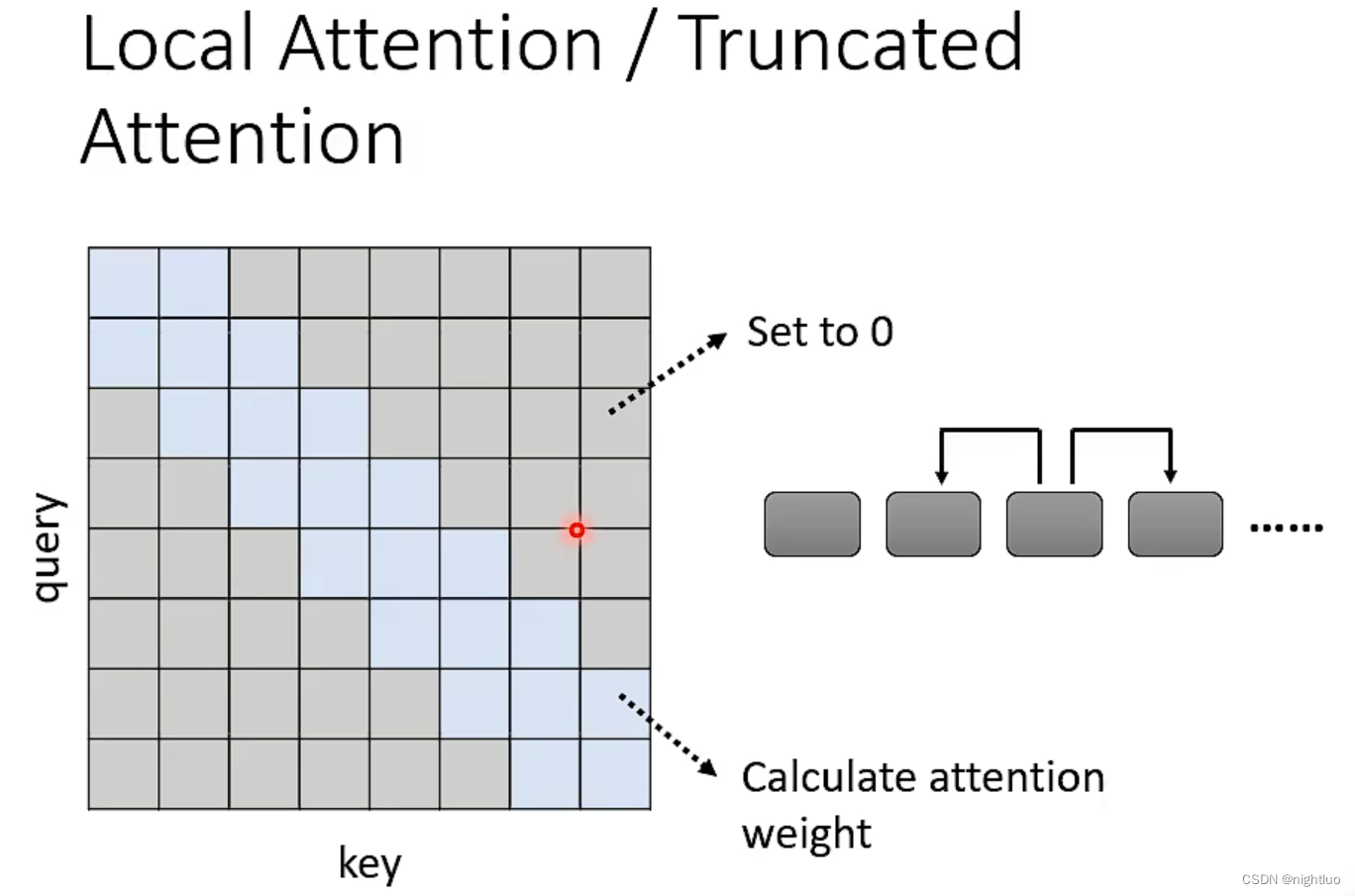
类似于空洞卷积???

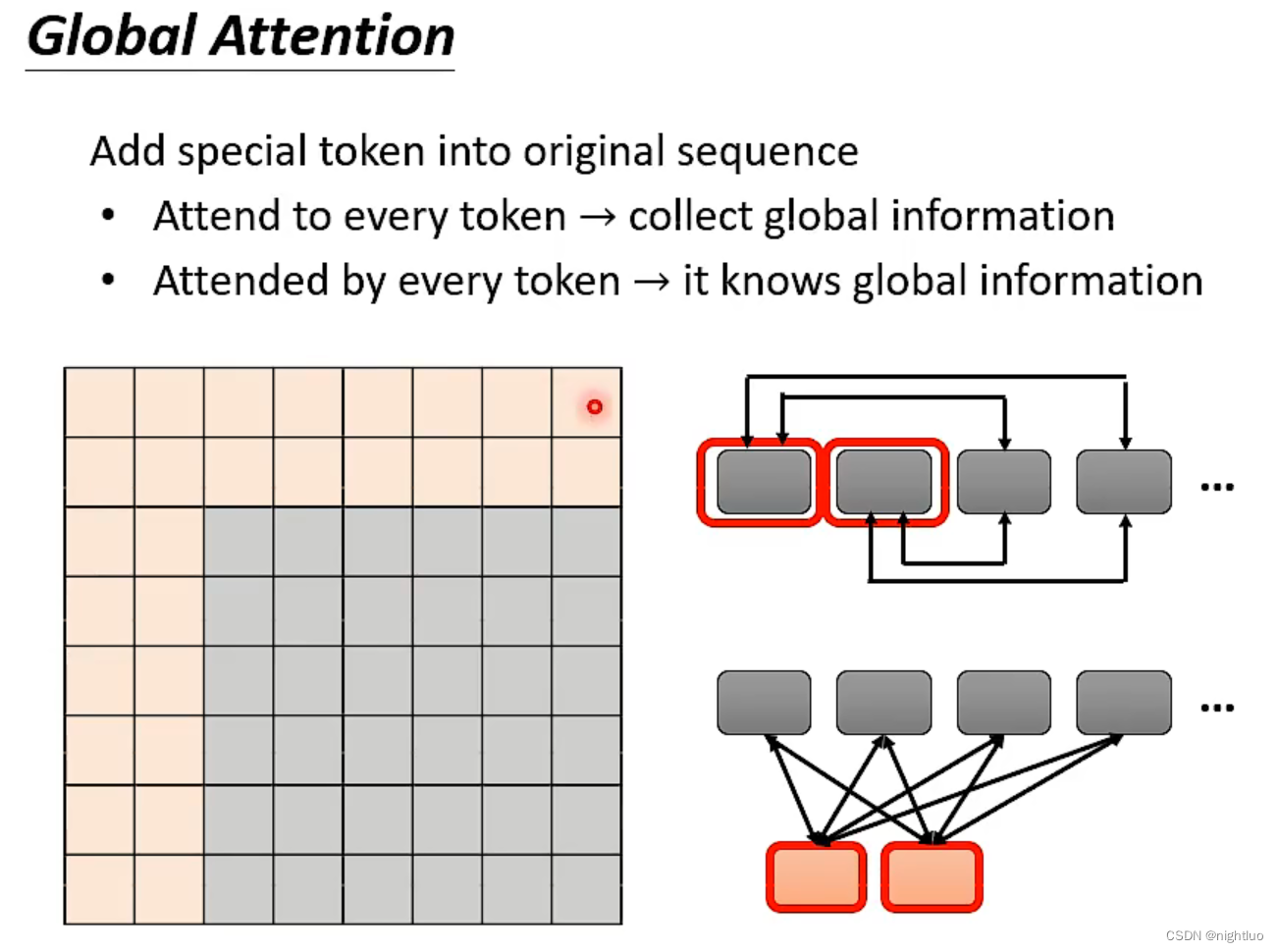
special token:前两行、前两列,所有token通过special token传递信息,token两两间无通信
multi-head:通过不同的head,使用多种attention机制
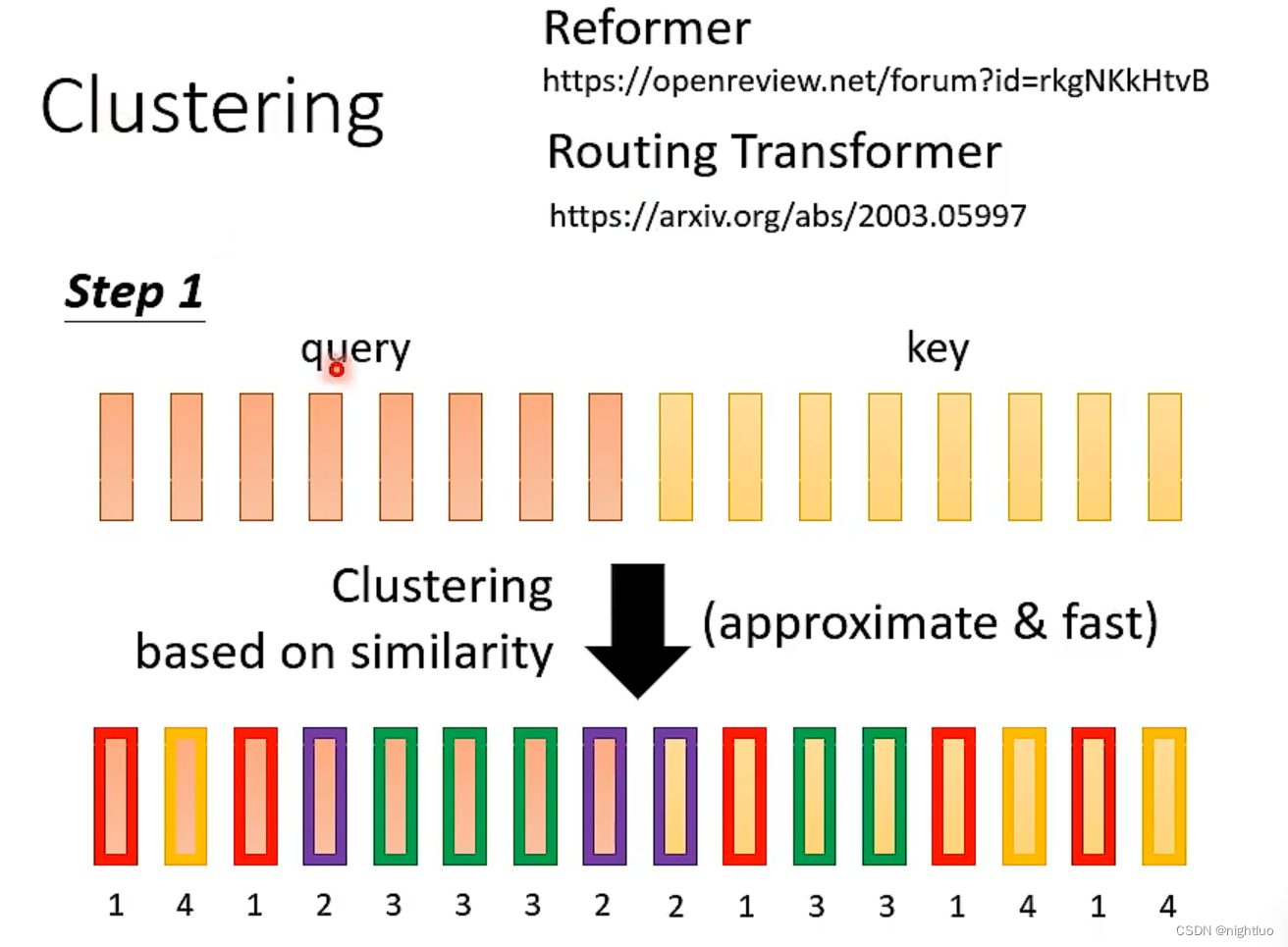
query和key在同一cluster里才计算其attention value,否则直接置0
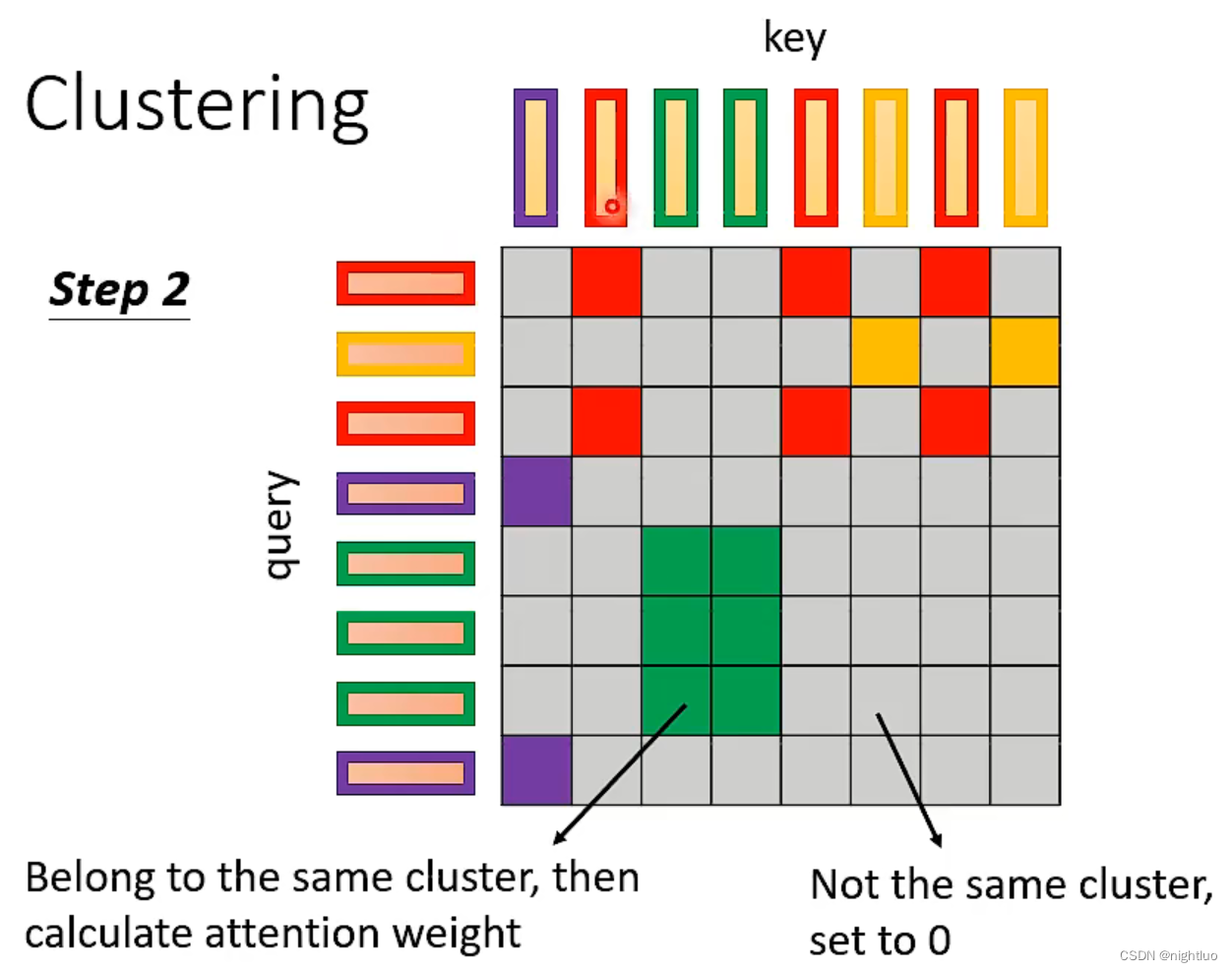
上述模型,对于要不要计算attention,都是基于人类的理解
基于learnable决定要不要计算attention
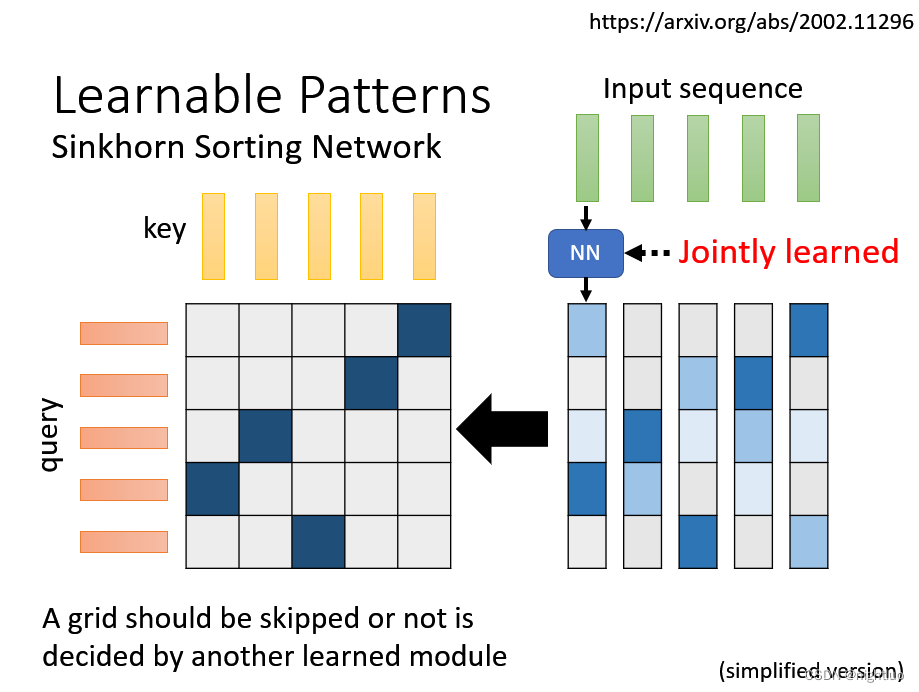
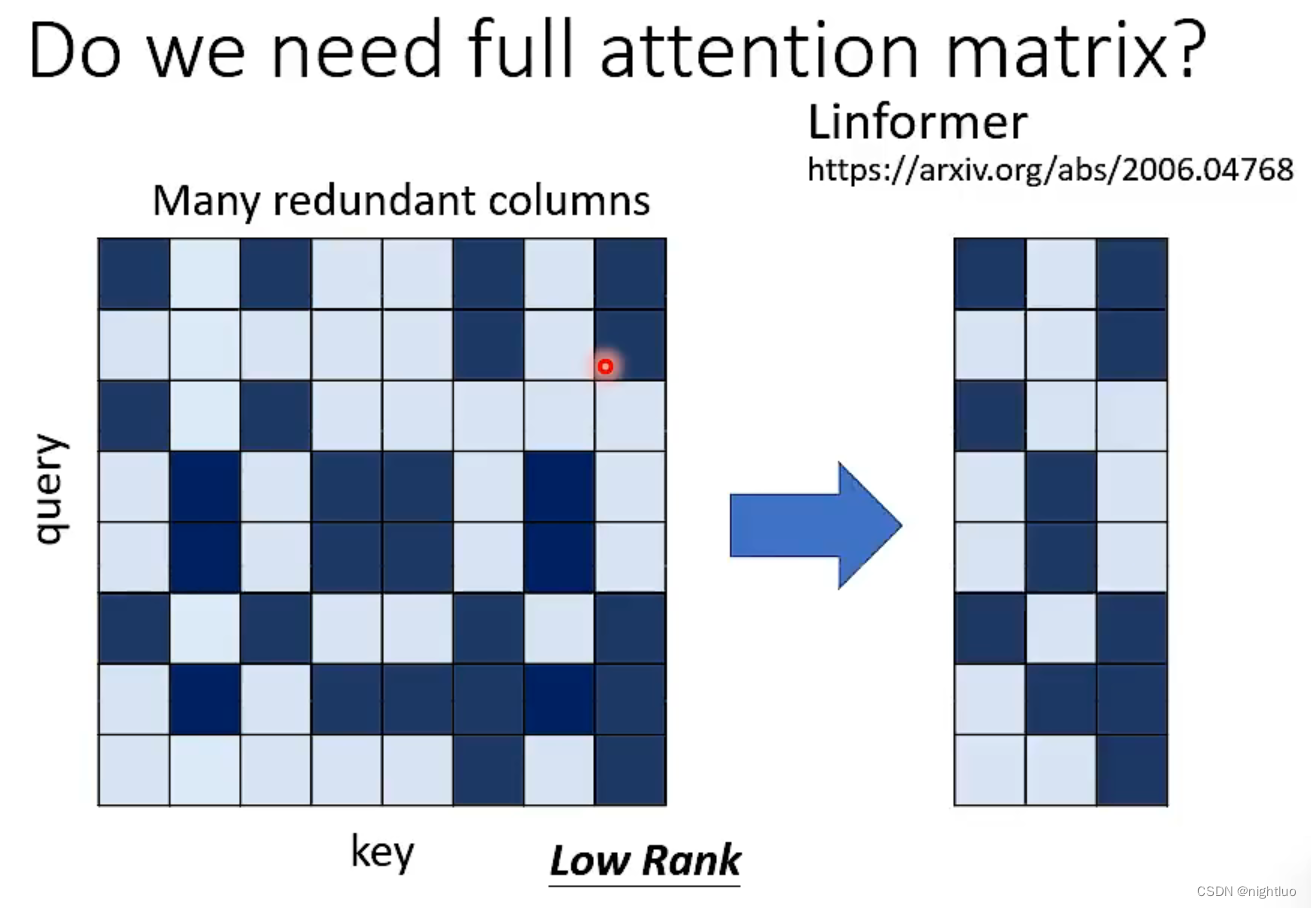
去除重复的column















 966
966











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









