






Hybrid Convolutional and Attention Network for Hyperspectral Image Denoising

来源: IEEE Geoscience and Remote Sensing Letters(2024年第21卷)
作者单位:
中国海洋大学(Ocean University of China)
学院:计算机科学与技术学院
密西西比州立大学(Mississippi State University)
学院:电气与计算机工程系
核心收录:
该论文已被 SCI 和 EI 核心数据库收录
中科院分区(2023年新版):
根据中科院新版分区标准,该论文所在期刊属于地球科学与遥感方向
发表时间:2024年
总述
这篇论文提出了一种新的混合卷积和注意力网络(HCANet),用于高光谱图像(HSI)去噪。HCANet结合了卷积神经网络(CNNs)和Transformer的优势,以同时增强全局和局部特征的建模。为了捕获长距离依赖性和邻域光谱相关性,作者设计了一个卷积和注意力融合模块(CAFM)。此外,为了改善多尺度信息聚合,作者设计了一个多尺度前馈网络(MSFN),通过提取不同尺度的特征来增强去噪性能。
主要贡献包括:
- 探索了HSI去噪中全局和局部特征建模的挑战性问题,据作者所知,这是第一个将卷积和注意力机制结合起来进行HSI去噪的工作。
- 提出了 多尺度前馈网络(MSFN),它无缝提取不同尺度的特征,有效抑制多尺度噪声。
- 在两个基准数据集上进行了广泛的实验,证明了所提出的HCANet的合理性和有效性。
方法论方面,HCANet是一个U形网络,包含多个卷积注意力混合(CAMixing)块。每个CAMixing块包括CAFM和MSFN。对于噪声HSI,首先使用3×3×3卷积获得低级特征,然后使用U形网络和多个CAMixing块以及跳跃连接获得噪声残差图。最终,通过 全局梯度正则化器训练HCANet。
CAFM由局部分支和全局分支组成。局部分支使用1×1卷积和通道洗牌来提取局部特征,而全局分支使用注意力机制来建模长距离特征依赖性。MSFN将输入特征通过两条并行路径处理,结合门控机制增强非线性变换,下路径使用深度卷积提取特征,上路径采用两个 3×3 的多尺度膨胀卷积(膨胀率为 2 和 3)提取多尺度特征。
实验结果表明,HCANet在去除各种类型的复杂噪声方面非常有效。在主流HSI数据集上的实验结果显示,所提出的HCANet在去除复杂噪声方面优于其他最先进的方法。
论文还进行了消融研究,证明了HCANet中每个组件的有效性,并通过计算复杂性的比较,展示了HCANet在保持相对较少参数和计算复杂性的同时,实现了最佳的去噪性能。
总结来说,这篇论文提出了一种新的HSI去噪网络HCANet,通过结合卷积和注意力机制,有效地去除了噪声并保留了图像细节,提高了去噪性能。
混合卷积与注意力网络用于高光谱图像去噪
解释:
高光谱图像
高光谱图像(Hyperspectral Image, HSI) 是一种包含丰富光谱信息的图像类型,能够记录每个像素在多个连续光谱波段上的反射或辐射强度。与普通彩色图像(如RGB图像)只包含红、绿、蓝三个波段的光谱信息不同,高光谱图像的光谱分辨率更高,可以涵盖数百甚至上千个窄波段。这使得高光谱图像能够捕获物质的细微光谱特征,实现传统成像无法达到的精细分析。
原文:
摘要:高光谱图像(HSI)去噪对于高光谱数据的有效分析和解读至关重要。然而,在去噪过程中,同时建模全局和局部特征的研究较为稀少。在这封信中, 我们提出了一种混合卷积与注意力网络(HCANet),该网络结合了卷积神经网络(CNN)和Transformer的优势。为增强全局和局部特征的建模能力, 我们设计了一个卷积与注意力融合模块,用于捕获长程依赖和邻域光谱相关性。此外,为了改进多尺度信息聚合, 我们设计了一个多尺度前馈网络,通过在不同尺度上提取特征来提升去噪性能。
实验结果表明,在主流高光谱图像数据集上的测试验证了所提出HCANet的合理性和有效性。该模型在去除多种复杂噪声方面表现出色。我们的代码已公开,访问地址为 https://github.com/summitgao/HCANet。
关键词:高光谱图像,图像去噪,Transformer,注意力机制,深度学习
1.介绍
高光谱成像是一种强大的技术,可以从目标或场景中获取丰富的光谱信息。与RGB数据相比,高光谱图像(HSI)能够捕获细粒度的光谱信息,因此被广泛应用于诸多实际场景中,例如光谱解混[1]和地物分类[2]。然而,HSI在成像过程中往往受到不可避免的混合噪声影响,这些噪声通常由传感器成像过程中的曝光时间不足和反射能量不足引起。这些噪声会降低图像质量并阻碍后续分析和应用的性能。
尽管现有方法在一定程度上取得了显著的去噪效果,但它们通常依赖于手工设计的先验与真实噪声模型的相似程度。在近年来,卷积神经网络(CNN)[7]为高光谱图像去噪提供了新的思路,并展现了显著的性能提升。例如,Maffei等[8]提出了一种基于CNN的HSI去噪模型,通过将噪声水平图作为输入来训练网络;Wang等[9]提出了一种基于联合八度卷积和注意力机制的网络;Pan等[10]设计了一种逐步多尺度信息聚合网络以去除HSI中的噪声。这些基于CNN的方法通过卷积核实现局部特征建模。
最近,随着视觉Transformer(ViT)[11]的兴起,基于Transformer的方法在各种计算机视觉任务中取得了显著成功。现有的Transformer去噪方法通过学习全局上下文信息,取得了优异的去噪效果。然而,如果能有效地考虑和利用局部特征,则HSI的去噪性能可能会进一步提升。因此,结合CNN和Transformer以同时建模局部和全局信息,是提升去噪性能的重要方向。
构建一种有效的Transformer和CNN混合模型用于HSI去噪并不容易,主要存在以下两个挑战:
- 最佳的本地和全局特征建模的混合架构仍然是一个未解的问题。卷积核能够捕捉局部特征,但意味着丢失了远距离的信息交互。卷积和注意力的组合可能提供了一个可行的解决方案。
- Transformer 中前馈网络(FFN)的单尺度特征聚合有限。一些方法使用深度卷积来提高 FFN 中的局部特征聚合。然而,由于隐藏层中的通道数量较多,单尺度令牌聚合难以利用丰富的通道表示。
为了解决上述两个问题,我们提出了一种混合卷积与注意力网络(HCANet),用于高光谱图像去噪,该网络同时利用全局上下文信息和局部特征,如图1所示。
具体而言:
- 我们设计了一个 卷积与注意力融合模块(CAFM),用于增强全局和局部特征建模能力,捕获长程依赖和邻域光谱相关性。
- 此外,为改进FFN中的多尺度信息聚合,我们设计了一个 多尺度前馈网络(MSFN),通过在不同尺度上提取特征来增强去噪性能。
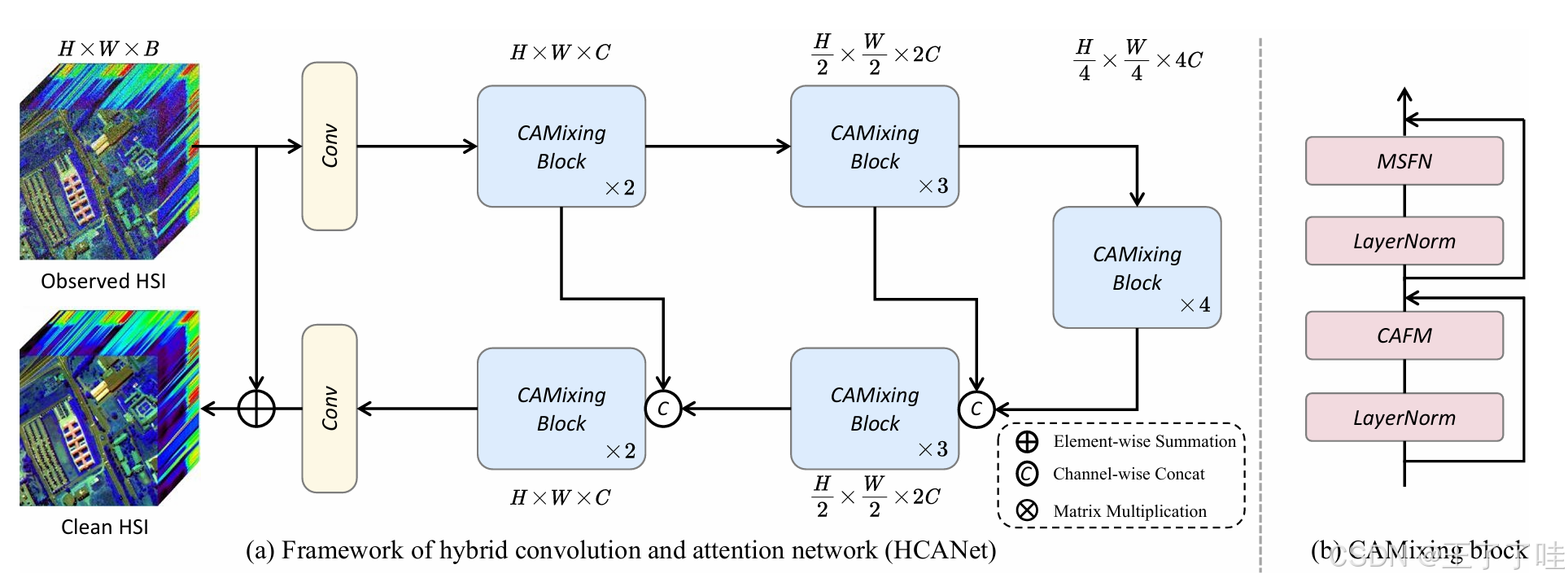
图1. 我们提出的用于高光谱图像(HSI)去噪的混合卷积与注意力网络(HCANet)的示意图。(a) HCANet的框架。(b) CAMixing模块的内部结构。
通过消除噪声,HCANet能够提升地物检测和分类的准确性。因此,HSI去噪是一种许多遥感应用中不可或缺的关键预处理技术。
在MSFN中使用了三个具有不同步幅的平行扩张卷积。通过在两个真实数据集上进行实验,我们验证了所提出的HCANet优于其他最新的对比方法。本文的主要贡献总结如下:
- 探索了高光谱图像去噪中全局与局部特征建模这一具有前景但充满挑战性的问题。据我们所知,这是首次将卷积和注意力机制相结合用于高光谱图像去噪任务的研究。
- 提出了多尺度前馈网络,能够无缝地在不同尺度上提取特征,并有效地抑制多尺度噪声。
- 在两个基准数据集上进行了大量实验,验证了所提出HCANet的合理性和有效性。 作为额外贡献,我们公开了代码,以惠及其他研究者。
2.方法论
在本节中,我们介绍了用于高光谱图像去噪的混合卷积与注意力网络(HCANet)。如图1所示, 模型的主要结构是一个U形网络,包含多个卷积注意力混合(CAMixing)模块。每个CAMixing模块包括两个部分:卷积-注意力融合模块(CAFM)和多尺度前馈网络(MSFN)。对于高光谱图像(HSI),3D卷积可以全面捕捉空间和光谱特征,但会增加参数量。为了管理复杂性,我们使用2D卷积进行通道调整,有效地利用HSI特征。
对于一个噪声高光谱图像 I ∈ R H × W × B I \in \mathbb{R}^{H \times W \times B} I∈RH×W×B,其中 H × W H \times W H×W 表示空间分辨率, B B B 表示通道维度,我们的HCANet首先使用 3 × 3 × 3 3 \times 3 \times 3 3×3×3 卷积来获取低层次特征。然后,我们使用一个U形网络,包含多个CAMixing模块和跳跃连接,来获得噪声残差图 I N ∈ R H × W × B I_N \in \mathbb{R}^{H \times W \times B} IN∈RH×W×B,其形状与输入的噪声图像相同。重建的干净高光谱图像可以表示为: I ^ = I + I N \hat{I} = I + I_N I^=I+IN。最后,使用带有全局梯度正则化器的重建损失来训练HCANet。
高光谱图像去噪的目标是从噪声高光谱图像重建对应的干净高光谱图像。在高光谱图像中融合全局和局部特征对于增强去噪任务非常重要。因此,CAFM被设计在CAMixing模块中。为了进一步利用前馈网络中的上下文信息来进行高光谱图像去噪,MSFN被设计在CAMixing模块中。接下来,我们将介绍CAFM和MSFN的详细信息。

图 2. 所提议的卷积和注意力融合模块 (CAFM) 的示意图。 它由局部分支和全局分支组成。在局部分支中,使用卷积和通道重排进行局部特征提取。在全局分支中,使用注意力机制来建模远程特征依赖关系。
A. 卷积与注意力融合模块
卷积操作由于其局部特性和有限的感受野,难以有效建模全局特征。而 Transformer 借助注意力机制,在提取全局特征和捕获长距离依赖关系方面表现出色。卷积与注意力机制可以相互补充,协同建模全局和局部特征。受此启发,我们设计了一个卷积与注意力融合模块(CAFM),如图 2 所示。我们在全局分支中采用自注意力机制,用以捕获更广泛的高光谱数据信息,同时局部分支专注于提取局部特征,从而实现全面的去噪效果。
提出的 CAFM 包括局部分支和全局分支。 在局部分支中,为了增强跨通道的交互并促进信息整合,我们首先使用 1×1 卷积调整通道维度。随后执行 通道混洗操作,以进一步混合和融合通道信息。通道混洗将输入张量沿通道维度划分为多个组,并在每个组内采用深度可分离卷积来实现通道混洗。随后,将每组的输出张量沿通道维度连接起来,生成一个新的输出张量。 接着,我们利用 3 × 3 × 3 卷积提取特征。局部分支可以表示为:
局部分支的公式可以表示为:
F
conv
=
W
3
×
3
×
3
(
CS
(
W
1
×
1
(
Y
)
)
)
F_{\text{conv}} = W_{3 \times 3 \times 3}(\text{CS}(W_{1 \times 1}(Y)))
Fconv=W3×3×3(CS(W1×1(Y)))
其中,
F
conv
F_{\text{conv}}
Fconv 是局部分支的输出,
W
1
×
1
W_{1 \times 1}
W1×1 表示 1×1 卷积,
W
3
×
3
×
3
W_{3 \times 3 \times 3}
W3×3×3表示 3×3×3 卷积,
CS
\text{CS}
CS表示通道混洗操作,
Y
Y
Y 是输入特征。
在全局分支中,我们首先通过 1×1 卷积和 3×3 深度卷积生成查询
(
Q
)
(Q)
(Q)、键
(
K
)
(K)
(K) 和值
(
V
)
(V)
(V),得到三个形状为
H
^
×
W
^
×
C
^
\hat{H} \times \hat{W} \times \hat{C}
H^×W^×C^的张量。接下来,将
Q
Q
Q重塑为
Q
^
∈
R
H
^
W
^
×
C
^
\hat{Q} \in \mathbb{R}^{\hat{H} \hat{W} \times \hat{C}}
Q^∈RH^W^×C^,并将
K
K
K 重塑为
K
^
∈
R
C
^
×
H
^
W
^
\hat{K} \in \mathbb{R}^{\hat{C} \times \hat{H} \hat{W}}
K^∈RC^×H^W^。然后,通过
Q
^
\hat{Q}
Q^ 和
K
^
\hat{K}
K^ 的交互计算注意力图
A
∈
R
C
^
×
C
^
A \in \mathbb{R}^{\hat{C} \times \hat{C}}
A∈RC^×C^。
这样减少了计算负担,相比于计算大小为
R
H
^
W
^
×
H
^
W
^
\mathbb{R}^{\hat{H} \hat{W} \times \hat{H} \hat{W}}
RH^W^×H^W^ 的巨大常规注意力图。全局分支的输出
F
att
F_{\text{att}}
Fatt 定义为:
F
att
=
W
1
×
1
Attention
(
Q
^
,
K
^
,
V
^
)
+
Y
F_{\text{att}} = W_{1 \times 1}\text{Attention}(\hat{Q}, \hat{K}, \hat{V}) + Y
Fatt=W1×1Attention(Q^,K^,V^)+Y
其中:
Attention
(
Q
^
,
K
^
,
V
^
)
=
V
^
Softmax
¸
(
K
^
Q
^
/
α
)
\text{Attention}(\hat{Q}, \hat{K}, \hat{V}) = \hat{V} \c\text{Softmax}(\hat{K} \hat{Q} / \alpha)
Attention(Q^,K^,V^)=V^Softmax¸(K^Q^/α)
α
\alpha
α 是一个可学习的缩放参数,用于在应用 softmax 函数之前控制
K
^
\hat{K}
K^ 和
Q
^
\hat{Q}
Q^矩阵乘积的幅值。
最终,CAFM 模块的输出计算公式为:
F
out
=
F
att
+
F
conv
F_{\text{out}} = F_{\text{att}} + F_{\text{conv}}
Fout=Fatt+Fconv
B. 多尺度前馈网络
原始的 ViT 中的前馈网络(FFN)由两个线性层组成,用于单尺度特征聚合。然而,FFN 的单尺度特征聚合所包含的信息是有限的。 为了增强非线性特征转换,我们提出了多尺度前馈网络(MSFN)。在每个 CAMixing 块之后,CAFM 的输出被输入到 MSFN 中,以聚合多尺度特征并增强非线性信息的转换。以往的研究表明,在图像去噪任务中引入多尺度信息是有效的 [10]。

图 3. 多尺度前馈网络 (MSFN) 的示意图。
MSFN 的具体细节如图 3 所示。首先,两个 1×1 卷积被用于扩展特征通道,扩展比例为 γ = 2 \gamma = 2 γ=2。输入特征通过两个并行路径进行处理,并引入了门控机制,通过两条路径的特征逐元素相乘来增强非线性变换。 在下路径中,使用深度卷积进行特征提取;在上路径中,采用多尺度膨胀卷积进行多尺度特征提取。使用了两个 3×3 的膨胀卷积,膨胀率分别为 2 和 3。
对于输入张量
X
∈
R
H
^
×
W
^
×
C
^
X \in \mathbb{R}^{\hat{H} \times \hat{W} \times \hat{C}}
X∈RH^×W^×C^,MSFN 的公式定义为:
Gating
(
X
)
=
ϕ
(
W
3
×
3
×
3
W
1
×
1
(
X
)
)
⊙
(
W
3
×
3
2
W
1
×
1
(
X
)
+
W
3
×
3
3
W
1
×
1
(
X
)
)
\text{Gating}(X) = \phi(W_{3 \times 3 \times 3} W_{1 \times 1}(X)) \odot (W_{3 \times 3}^2 W_{1 \times 1}(X) + W_{3 \times 3}^3 W_{1 \times 1}(X))
Gating(X)=ϕ(W3×3×3W1×1(X))⊙(W3×32W1×1(X)+W3×33W1×1(X))
X
out
=
W
1
×
1
Gating
(
X
)
X_{\text{out}} = W_{1 \times 1} \text{Gating}(X)
Xout=W1×1Gating(X)
其中:
⊙
\odot
⊙ 表示逐元素相乘,
ϕ
\phi
ϕ 表示 GELU 非线性激活函数,
W
3
×
3
2
W_{3 \times 3 }^2
W3×32 表示膨胀率为 2 的 3×3 膨胀卷积,
W
3
×
3
3
W_{3 \times 3}^3
W3×33表示膨胀率为 3 的 3×3 膨胀卷积。
MSFN 相较于 CAFM 扮演了不同的角色,主要侧重于通过上下文信息丰富特征表示。
解释:
门控机制(Gating Mechanism)
门控机制是一种用于控制信息流的机制,常见于深度学习模型中,尤其是循环神经网络(RNN)和注意力机制中。它的主要作用是决定哪些信息应该被保留,哪些应该被丢弃,或是如何调整不同信息源的权重。通过门控机制,模型能够在处理数据时对信息流进行更灵活的控制,从而提高性能。
具体来说,门控机制通常包括以下几部分:
输入门(Input Gate):决定当前时刻输入的信息应该在多大程度上影响当前的状态。
遗忘门(Forget Gate):决定上一时刻的状态有多少信息应该被忘记,通常在处理序列数据时用于控制历史信息的遗忘。
输出门(Output Gate):控制模型输出时的选择性信息,通过对隐藏状态或记忆单元的加权来生成最终输出。
深度卷积(Depthwise Convolution)
深度卷积是一种特殊形式的卷积操作,通常用于减少网络的计算量和参数量。与标准卷积(通常是 逐点卷积 + 卷积核)不同,深度卷积的卷积核是对每个输入通道单独进行卷积的,来提高计算效率。
- 在传统卷积中,输入特征图的每个通道都会与每个卷积核进行卷积(即所有通道共享卷积核)。
- 在深度卷积中,每个输入通道有一个独立的卷积核,只对该通道进行卷积。
- 这样,深度卷积会显著减少参数数量,因为它只在每个通道上执行卷积操作,而不再对所有通道进行交叉操作。
多尺度膨胀卷积(Multi-scale Dilated Convolution)
多尺度膨胀卷积是一种扩展传统卷积的技术,能够在不同的尺度下提取特征,同时避免增加计算量。膨胀卷积(Dilated Convolution)通过在卷积核的元素之间插入空洞(或称为膨胀),扩大卷积核的感受野来增强网络的上下文感知能力。
- 在传统卷积中,卷积核在相邻的像素之间滑动。
- 在膨胀卷积中,卷积核的元素之间插入空洞(即在卷积核元素之间插入一定数量的间隔),从而在不增加计算量的情况下扩大感受野。
- 多尺度膨胀卷积则是通过使用不同膨胀率(dilation rate)来结合不同的感受野,从而获取不同尺度的信息。
膨胀卷积的公式:
- 假设输入图像的尺寸为 H × W H \times W H×W,卷积核的尺寸为 K × K K \times K K×K,膨胀率为 r r r,那么膨胀卷积会将卷积核的元素按照膨胀率 r r r插入空洞,实际感受野将是 K × r K \times r K×r。
例如:
- 膨胀率为1时,膨胀卷积等同于普通卷积。
- 膨胀率为2时,卷积核的每个元素之间会插入一个像素的间隔,能够感知更大区域的信息。
C. 损失函数
我们使用 L1 损失函数作为网络训练的优化目标,重建损失函数定义为:
L
rec
=
∥
I
^
−
I
∥
1
L_{\text{rec}} = \| \hat{I} - I \|_1
Lrec=∥I^−I∥1
其中,
I
^
\hat{I}
I^ 表示预测的无噪声高光谱图像 (HSI),而
I
I
I 表示含噪声的 HSI。
为了提升去噪质量并减少冗余,我们引入了全局梯度正则化器来约束
I
^
\hat{I}
I^:
L
grad
=
∥
∇
h
I
^
−
∇
h
I
∥
2
2
+
∥
∇
v
I
^
−
∇
v
I
∥
2
2
+
∥
∇
s
I
^
−
∇
s
I
∥
2
2
L_{\text{grad}} = \| \nabla_h \hat{I} - \nabla_h I \|_2^2 + \| \nabla_v \hat{I} - \nabla_v I \|_2^2 + \| \nabla_s \hat{I} - \nabla_s I \|_2^2
Lgrad=∥∇hI^−∇hI∥22+∥∇vI^−∇vI∥22+∥∇sI^−∇sI∥22
其中,
∇
h
\nabla_h
∇h、
∇
v
\nabla_v
∇v 和
∇
s
\nabla_s
∇s 分别表示在水平、垂直和光谱轴上应用的梯度算子。
最终,总损失函数定义为:
L
=
L
rec
+
λ
L
grad
L = L_{\text{rec}} + \lambda L_{\text{grad}}
L=Lrec+λLgrad
其中,
λ
\lambda
λ 是权重参数,用于控制
L
grad
L_{\text{grad}}
Lgrad。 根据经验数据,我们将
λ
\lambda
λ 设置为 0.01,以平衡各损失项之间的权重。
3.实验结果与分析
A. 实验设置
基准数据集。为了验证我们模型在高光谱图像去噪上的表现,我们在ICVL数据集上训练了模型,并在Pavia数据集上进行了评估。在ICVL数据集中,利用了31个光谱波段,收集了分辨率为1392 × 1300的图像。为了便于训练,我们将数据随机裁剪,并转换为形状为128×128×31的立方体数据。 我们通过旋转和缩放技术增强了训练数据集,以提高模型的鲁棒性,最终得到了包含20,000个新样本的数据集。为了测试我们模型在真实遥感图像上的去噪效果,我们还在Pavia数据集上进行了实验。
噪声设置。在测试阶段,我们在两个设置下进行了实验,以展示我们提出的模型的有效性和泛化能力。在第一个设置中,我们使用从σ = 30到σ = 70的不同幅度的高斯噪声以及盲高斯噪声(随机噪声幅度)对模型进行了测试。在第二个设置中,我们评估了模型在真实卫星传感器获得的高光谱数据中常见的复杂噪声类型下的鲁棒性,例如高斯噪声、脉冲噪声和截止噪声。我们定义了五种复杂噪声情况:
- 情况1:在所有光谱通道中加入不同幅度的高斯噪声,标准差从30到70随机选择。
- 情况2:高斯噪声 + 条纹噪声。在高斯噪声的基础上,随机在光谱波段中加入条纹噪声,通过污染5%~15%的列来增加条纹噪声。
- 情况3:高斯噪声 + 截止噪声。在情况1的基础上,我们在三分之一的光谱波段中加入截止噪声。每个波段中的5%到15%列会发生截止现象。
- 情况4:高斯噪声 + 脉冲噪声。在情况1的基础上,随机选择约三分之一的光谱波段,通过增加脉冲噪声的强度(范围为30%到70%)来增加噪声。
- 情况5:混合噪声。与上述情况类似,每个光谱波段受到情况1中的非独立同分布(non-i.i.d)高斯噪声影响。此外,每个波段还会随机受到另外三种噪声类型的组合影响。
基线方法和实现细节。我们将HCANet与五种最先进的方法进行了比较,包括基于模型的方法和基于深度学习的方法。 对于基于模型的方法,我们考虑了BM4D [12],以及低秩方法如LRMR [13]和LRTV [14]。在深度学习方法方面,我们选择了著名的方法Restormer [15]和MAFNet [10]进行比较。我们使用了三种评估指标,包括峰值信噪比(PSNR)、结构相似性(SSIM)和光谱角度映射(SAM)来量化去噪性能。 较大的PSNR和SSIM值表示更好的去噪结果,而较小的SAM值表示更好的去噪性能。我们以10-4的初始学习率训练模型,并且随着训练的进行学习率逐渐下降。HCANet使用Adam优化器进行优化,并且在高斯噪声上训练了100个epoch,在复杂噪声上训练了150个epoch。我们在PyTorch框架下使用配备NVIDIA GTX 2080Ti GPU、Intel Xeon E5 CPU和32GB RAM的机器进行所有实验。
B. 实验分析
我们提出的HCANet与其他基准方法的全面定量比较结果如表I和表II所示。 在这两张表格中,红色高亮值表示最佳性能,而蓝色高亮值表示第二最佳性能。
表I展示了在不同强度的高斯噪声下所有方法的结果。从表中可以看出,当数据包含单一类型的噪声时,HCANet在所有评估指标上都优于其他方法。此外, 表II展示了复杂噪声的结果。我们可以看到,HCANet在所有噪声情况下都取得了最佳性能。 除了定量分析,我们还进行了定性比较,如图4和图5所示。伪彩色去噪结果来自三个波段(17、20、30)。可以明显看出,传统的去噪方法在复杂噪声下表现不佳。虽然MAFNet去除了大部分噪声,但它倾向于过度平滑,丧失了一些图像细节。Restormer在复杂噪声下表现较差。相比之下,HCANet能够有效去除大部分噪声,同时保留局部细节,成功恢复原始图像特征。
为了验证HCANet中各个组件的有效性,我们在ICVL数据集上进行了消融实验。如图III所示,HCANet(包含所有组件)在与其他所有变种的比较中表现最好。 此外,我们发现随着添加局部分支、3D卷积和MSFN,性能不断提升。这表明我们提出的HCANet中的每个组件都是必要的。
表 I :在四种噪声幅度(σ = 30、50、70 和盲噪声)下,提出的 HCANet 与其他比较方法在高光谱图像去噪任务中的定量评估。

表 II :在五种复杂噪声情况下,提出的 HCANet 与其他比较方法在高光谱图像去噪任务中的定量评估。

表 III :在噪声水平 σ = 30 和 EPOCH = 50 下,ICVL 数据集的消融研究


图 4. 在噪声水平 σ = 50 下,ICVL 数据集的高斯噪声去除结果,使用波段 (17, 20, 30)。

图 5. 在 Pavia 数据集上,使用波段 (17, 20, 30) 的真实噪声去除结果。
表 IV :在盲高斯噪声下,模型的计算复杂度比较分析,EPOCH = 50

我们还比较了各模型的计算复杂度,结果如表 IV 所示。HCANet 在保持相对适中的参数数量和计算复杂度的同时,实现了最佳的去噪性能。
4.结论
在本论文中,我们提出了 HCANet,一种用于高光谱图像(HSI)去噪的新型网络。特别地,我们提出了卷积与注意力融合模块(CAFM),用于融合全局和局部特征。此外,我们还提出了多尺度前馈网络(MSFN),以从多个尺度提取特征并增强去噪性能。对挑战性 HSI 数据集的实验结果表明,与现有的最先进的 HSI 去噪方法相比,我们提出的模型在定量指标和重建图像的视觉质量方面均表现出了显著的去噪效果。

















 4569
4569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









