






Spark流处理(WordCount)
1. Spark环境
1) 4台CentOs 6.4
2) Hadoop 2.2.0
3) Jdk 1.7
4) Scala 2.10.3
5) Spark 0.9.0
2. 前期准备
由于Spark支持Socket流输入,准备NetCat作为TCP服务器不断对Spark进行word输入。
2.1 NetCat安装
1) yum install -y nc
2.2 启动监听服务
1) nc -l 9999 9999是端口号
3 启动Spark
输入:
/usr/local/spark/bin/run-exampleorg.apache.spark.streaming.exampl.NetworkWordCount local[2] 192.168.178.1829999
解释:192.168.178.182是netcat服务器的IP地址,9999是netcat服务器的端口号。
4 结果
4.1 netcat端输入

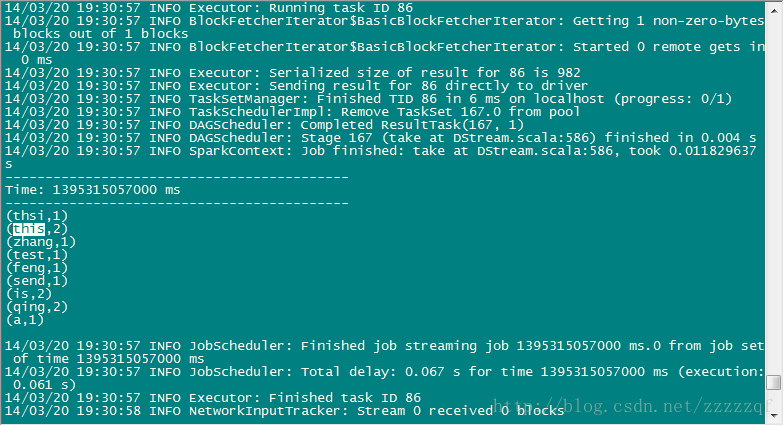
4.2 Spark中输出















 1014
1014











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









