







今天跟大家解读一下XGboost模型,华为杯研赛相关的思路参考
首先要明确一点,xgboost 是基于提升树的。
什么是提升树,简单说,就是一个模型表现不好,我继续按照原来模型表现不好的那部分训练第二个模型,依次类推。
来几个形象的比喻就是:
做题的时候,第一个人做一遍得到一个分数,第二个人去做第一个人做错的题目,第三个人去做第二个人做错的题目,以此类推,不停的去拟合从而可以使整张试卷分数可以得到100分(极端情况)。
把这个比喻替换到模型来说,就是真实值为100,第一个模型预测为90,差10分,第二个模型以10为目标值去训练并预测,预测值为7,差三分,第三个模型以3为目标值去训练并预测,以此类推。
目录
原理解读
1.0 学习路径:
我们xgboost的学习路径可以按照下面四个步骤来:
-
构造原始目标函数问题:
-
xgboost目标函数包含损失函数和基于树的复杂度的正则项;
-
-
泰勒展开问题:
-
原始目标函数直接优化比较难,如何使用泰勒二阶展开进行近似;
-
-
树参数化问题:
-
假设弱学习器为树模型,如何将树参数化,并入到目标函数中;这一步的核心就是要明白我们模型优化的核心就是优化参数,没有参数怎么训练样本,怎么对新样本进行预测呢?
-
-
如何优化化简之后的目标函数问题,优化泰勒展开并模型参数化之后的的目标函数,主要包含两个部分:
-
如何求得叶子节点权重
-
如何进行树模型特征分割
-
1.1 目标函数
1.1.0 原始目标函数
目标函数,可以分为两个部分,一部分是损失函数,一部分是正则(用于控制模型的复杂度)。
xgboost属于一种前向迭代的模型,会训练多棵树。
对于第t颗树,第i个样本的,模型的预测值是这样的:

进一步,我们可以得到我们的原始目标函数,如下:

从这个目标函数我们需要掌握的细节是,前后部分是两个维度的问题
两个累加的变量是不同的:
-
一个是
i,i这边代表的是样本数量,也就是对每个样本我们都会做一个损失的计算,这个损失是第t个树的预测值和真实值之间的差值计算(具体如何度量损失视情况而定)。 -
另一个是累加变量是
j,代表的是树的数量,也就是我们每个树的复杂度进行累加。
需要注意的是我们这里具体的损失函数是没有给出定义的,所以它可以是树模型,也可以是线性模型。
1.1.1 简单化简损失函数
正如上面所说,Xgboost是前向迭代,我们的重点在于第t个树,所以涉及到前t-1个树变量或者说参数我们是可以看做常数的。
所以我们的损失函数进一步可以化为如下,其中一个变化是我们对正则项进行了拆分,变成可前t-1项,和第t项:
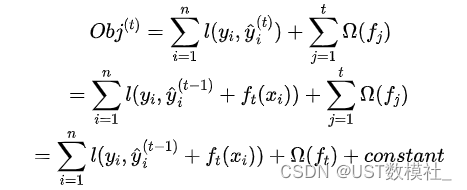
基于此,在不改变目标函数精读的情况下,我们已经做了最大的简化,最核心的点就是我们认为前t-1个树已经训练好了,所以涉及到的参数和变量我们当成了常数。
接下来,我们使用泰勒级数,对目标函数近似展开.
1.2 泰勒公式对目标函数近似展开
使用泰勒公式进行近似展开的核心目标是就是对目标函数进行化简,将常数项抽离出来。
基本泰勒公式展开如下:

还是那句话,我们可以使用任意一个损失函数,这里没有定式。
上述中树的表达我们都是使用函数f(x)来表示,本质上模型的优化求解是在求参数,所以我们需要对树模型参数化才可以进行进一步的优化
1.3 树的参数化
树的参数化有两个,一个是对树模型参数化,一个是对树的复杂度参数化。
1.3.0 树模型参数化-如何定义一个树
主要是定义两个部分:
-
每棵树每个叶子节点的值(或者说每个叶子节点的权重)
w:这是一个向量,因为每个树有很多叶子节点 -
样本到叶子节节点的映射关系
q:(大白话就是告诉每个样本落在当前这个树的哪一个叶子节点上) -
叶子节点样本归属集合
I:就是告诉每个叶子节点包含哪些样本
1.3.1 树复杂度的参数化-如何定义树的复杂度
定义树的复杂度主要是从两个部分出发:
-
每个树的叶子节点的个数(叶子节点个数越少模型越简单)
-
叶子节点的权重值
w(值越小模型越简单)
对于第二点,我们可以想一下L正则不就是想稀疏化权重,从而使模型变得简单吗,其实本质是一样的。
我们树的复杂度如下:
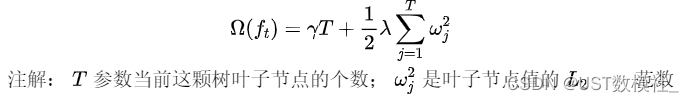
进而我们可以对树进行了参数化,带入到目标函数我们可以得到如下:
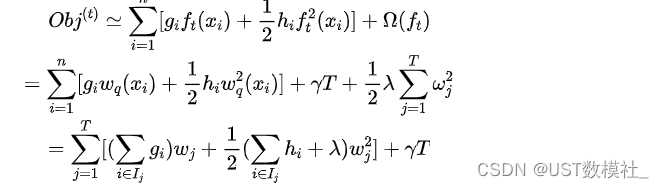
注解:最后一步的转化思路是从在这个树中,每个样本落在哪个节点转为了每个节点上有哪些样本
随后我们做如下定义:

还有一个就是如何做到特征的分裂,接下来我们详细聊一下如何去做
1.4寻找树的形状-特征分裂
首先明确一点,我们增益使用的是基于当前特征分裂点前后,目标函数的差值。
我们当然是希望,使用这个分裂点,目标函数降低的越多越好。
1.4.0 贪心算法
本质上是做两次循环,第一个是是针对每个特征的每个分割点做一次循环,计算收益,从而选择此特征的最佳分割点。分裂收益使用的是分裂之后的目标函数的变化差值。
第二个循环是对样本所有特征的循环,从中挑选出收益最大的特征。
简单说就是首先找到基于每个特征找到收益最大的分割点,然后基于所有特征找到收益最大的特征。
然后在这所有的循环中,挑出增益最大的那个分割点
1.4.1 近似算法-分位数候选点
对于每个特征,不去暴力搜索每个值,而是使用分位点
-
根据样本数量选择三分位点或者四分位点等等;
-
或者根据二阶导数(也就是梯度)作为权重进行划分
也就是说原来是某个特征的所有取值是候选点,现在是某个特征的分位点作为候选点。
目标实现
2.0 特征分裂并行寻找
寻找特征分隔点需要对特征值进行排序,这个很耗时间。我们可以在训练之前先按照特征对样本数据进行排序,并分别保存在不同的块结构中。每个块都有一个按照某个特征排好序的特征加对应的一阶二阶导数。
对于不同的特征的特征划分点,XGBoost分别在不同的线程中并行选择分裂的最大增益
2.1 缓存访问
特征是排好序,但是通过索引获取一阶二阶导数值是不连续的,造成cpu缓存命中率低;xgboost解决办法:为每个线程分配一个连续的缓存区,将需要的梯度信息存放在缓冲区中,这样就连续了;
同时通过设置合理的分块的大小,充分利用了CPU缓存进行读取加速(cache-aware access)。使得数据读取的速度更快。另外,通过将分块进行压缩(block compressoin)并存储到硬盘上,并且通过将分块分区到多个硬盘上实现了更大的IO。
2.2 xgboost特征的重要性是如何评估的
-
weight :该特征在所有树中被用作分割样本的特征的总次数。
-
gain :该特征在其出现过的所有树中产生的平均增益(我自己的理解就是目标函数减少值总和的平均值,这里也可以使用增益之和)。
-
cover :该特征在其出现过的所有树中的平均覆盖范围。
这里有一个细节需要注意,就是节点分割的时候,之前用过的特征在当前节点也是可以使用的,所以weight才是有意义的。
代码汇总
3.0 xgboost 如何筛选特征重要程度
xgboost 模型训练完毕之后,可以查一下每个特征在模型中的重要程度;
进一步的,我们可以暴力搜索一下,通过这个相关性筛选一下模型,看能不能在特征数量减少的情况下,模型表现能力不变甚至提升或者有我们可以接受的降低幅度。
核心代码如下(完整运行去github吧)
## 如何获取特征重要程度
print(model.feature_importances_)
plot_importance(model)
pyplot.show()
## 如何筛选特征
selection = SelectFromModel(model, threshold=thresh, prefit=True)完整代篇幅太大,不展示在这里
XGboost代码调参
框架参数:
-
booster:弱学习器类型
-
objective:分类还是回归问题以及对应的损失函数
-
n_estimators:弱学习器的个数
弱学习器参数:
-
max_depth:树的深度
-
min_child_weight:最小节点的权重阈值,小于这个值,节点不会再分裂;
-
gamma:节点分裂带来损失最小阈值,我们使用目标函数之差计算增益,小于这个阈值的时候,不再分裂
-
learning_rate:控制每个弱学习器的权重缩减系;这个系数会乘以叶子节点的权重值,它的作用在于削弱每个树的影响力,如果学习率小,对应的弱学习器的个数就应该增加。















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









