







 本文探讨了Hinton和Jeff Dean提出的 OUTRAGEOUSLY LARGE NEURAL NETWORKS,其核心是MoE (Mixture of Experts) 层。MoE网络由多个子网络构成,每个子网络针对不同输入类型,实现参数稀疏性和大规模网络下的小计算量。然而,网络在训练过程中出现Gating Network权重分配不均等问题,为此引入额外的正则化项以优化网络性能。这种方法挑战了通用模型的局限性,提倡为特定任务设计子网络,提高预测准确率。
本文探讨了Hinton和Jeff Dean提出的 OUTRAGEOUSLY LARGE NEURAL NETWORKS,其核心是MoE (Mixture of Experts) 层。MoE网络由多个子网络构成,每个子网络针对不同输入类型,实现参数稀疏性和大规模网络下的小计算量。然而,网络在训练过程中出现Gating Network权重分配不均等问题,为此引入额外的正则化项以优化网络性能。这种方法挑战了通用模型的局限性,提倡为特定任务设计子网络,提高预测准确率。
概述
现在的CNN网络普遍都是做成通用分类网络,即一个网络要做很多种事物的分类和识别,但是仔细想想这样是不是真的合理,能不能设计一种网络,对一种输入用一种子网络去做,对另外一种输入就用另外一种子网络去做,这样做的好处就很明显,首先可以在显著增大网络规模的情况下,不会明显升高计算量;其次,我感觉这参数稀疏网络的实现方式。而在今年ICLR上,就有人提出这种网络结构OUTRAGEOUSLY LARGE NEURAL NETWORKS,这是Hinton和Jeff Dean提出的一种在语音识别上的网络结构。
核心网络结构MoE layer
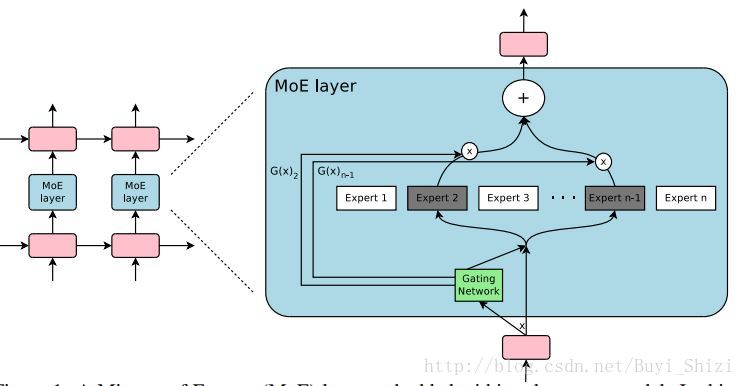
从图中我们可以看出,网络是由很多子网络组成的,每个子网络负责不同类型的输入信号,当其中几种网络做计算的时候,其他网络是完全不参与计算的,这就实现了大规模网络,小计算量的要求。
首先,Gating Network会根据输入选择不同的Export*网络,这里不只选择一种,选择的根据是由Gating Network的输出值取概率最高的前k的值,以此来选择n个Export网络中的k的网络,然后分别为每个网络分配不同的权重值,最后的输出就是:
y=∑i=0nG(x)iEi(x)
上面就是网络的核心思想。
问题
如论文所述,上述网络存在一下的问题:
Gating Network的输出网络权重值如果在不加额外限定条件的情况下,网络效果不理想。
我们希望的是对于不同的输入,Gating Network的输出权值在对应的Export网络上大,在另外一些网络上小,但是,训练的过程中发现,事实却不是这样,网络只在一些Export网络上权值较大,在另一些网络上权值较小。为了解决这个问题,就需要在loss函数中加入额外的regularization项:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1959
1959

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









