







 本文介绍了BBPE(Byte-Level BPE),一种用于解决罕见词表示问题的字节级子词方法。相较于传统的BPE,BBPE在不增加词典大小的情况下能更好地处理字符丰富的语言,且在表示多种语言方面具有跨语言共享的优势。实验表明,尽管BBPE可能导致更长的序列长度,但相比基于字符的方法,训练和推断的时间仍然有所减少。
本文介绍了BBPE(Byte-Level BPE),一种用于解决罕见词表示问题的字节级子词方法。相较于传统的BPE,BBPE在不增加词典大小的情况下能更好地处理字符丰富的语言,且在表示多种语言方面具有跨语言共享的优势。实验表明,尽管BBPE可能导致更长的序列长度,但相比基于字符的方法,训练和推断的时间仍然有所减少。
文章简介:
基于字符,子词,词的机器翻译几乎都是以词频top-k数量建立的词典;但是针对字符相对杂乱的日文和字符较丰富的中文,往往他们的罕见词难以表示;
本文提出采用字节级别的字词BBPE(byte-level BPE),不会出现oov的词;比纯用字节表示更方便,比只用字符表示又效果更好;当BBPE和BPE性能接近时,词典size只是BPE的1/8;
主要方法:
整体思想是,把文本表示生字节级别的n-gram,而不是常用的字符级别n-gram;
把文本用UTF-8编码,每个字符最多用4字节;
首先把句子变成UTF-8字节序列,再分割字节序列到 byte-level “subwords”;(4X)
Encoder:作者是采用基于transformer的实验,也可以使用深度CNN和双向GRU;
Decoder:作者提出字符可以用有效的字节表示,但是字节字串不一定能表示有效的字符;
解决半训练模型经常出现的错误模式:出现随机重复字节,作者提出的算法:
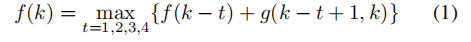
f(k)是一串字节能表示的最长字符;如果子字节和有效字符相关,则g(i,j)=1,否则为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3505
3505

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









