







大名鼎鼎的word2vec,相关原理就不讲了,已经有很多篇优秀的博客分析这个了. 如果要看背后的数学原理的话,可以看看这个:
https://wenku.baidu.com/view/042a0019767f5acfa1c7cd96.html
一个话总结下word2vec就是使用一个一层的神经网络去学习分布式词向量的方式,相关链接:
[Google原版word2vec主页] https://code.google.com/archive/p/word2vec/ (需翻墙)
[gensim中的word2vec] https://radimrehurek.com/gensim/models/word2vec.html
这篇博客来自于黄文坚的”Tensorflow实战”一书,我重新组织了下,如有侵权,联系我删除!
数据集
数据集使用的是text8 corpus, 详细地址: http://mattmahoney.net/dc/textdata,官方介绍:

数据集的下载地址是: http://mattmahoney.net/dc/text8.zip
知道地址了,直接下载就可以了,直接wget或者urlretrieve都可以,约31MB
'''Step1: download dataset'''
url = 'http://mattmahoney.net/dc/'
def may_download(filename, expected_bytes):
if not os.path.exists(filename):
filename, _ = urllib.request.urlretrieve(url + filename, filename)
statinfo = os.stat(filename)
if statinfo.st_size == expected_bytes:
print('Found and verified', filename)
else:
print(statinfo.st_size)
raise Exception('Failed to verify ' + filename)
return filename
filename = may_download('text8.zip', 31344016)简单明了,下载然后校验下载的文件大小
读取数据
下载下来的是zip file,里面包含一个名为”text8”的二进制文件,可以直接使用zipfile进行文件的读取,然后使用tf自带的as_str_any方法将其还原成字符串表示
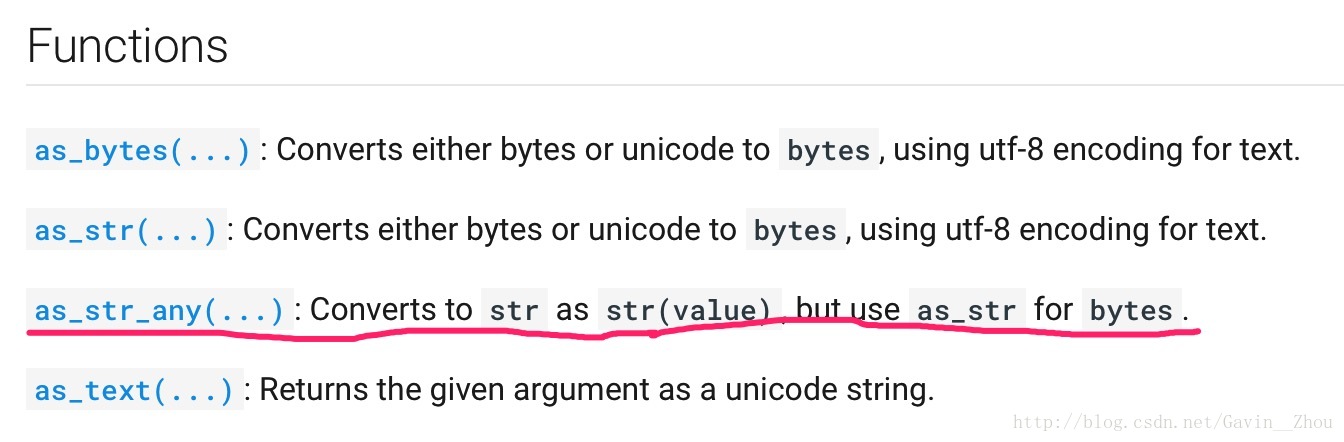
代码如下:
'''Step2: read dataset'''
def read_data(filename):
with zipfile.ZipFile(filename) as f:
data = tf.compat.as_str_any(f.read(f.namelist()[0])).split()
return data
words = read_data(filename)
print('Datas size', len(words))words中包含17005207个word
然而我们需要的不止是包含单词的列表,还需要将其编号
我们选择词频前5000个单词作为单词列表,其它的不在列表里面的作为unknown
vocabulary_size = 50000
def build_dataset(words):
count = [['UNK', -1]]
count.extend(collections.Counter(words).most_common(vocabulary_size-1))
dictionary = dict()
for word, _ in count:
dictionary[word] = len(dictionary)
data = list()
unk_count = 0
for word in words:
if word in dictionary:
index = dictionary[word]
else:
index = 0
unk_count += 1
data.append(index)
count[0][1] = unk_count
reverse_dictionary = dict(zip(dictionary.values(), dictionary.keys()))
return data, count, dictionary, reverse_dictionary
data, count, dictionary, reverse_dictionary = build_dataset(words)
del wordsdata是单词的index,dictionary是正向的word–>index的字典,reverse_dictionary是反向的index–>word的字典.
生成batch数据
使用Skip-Gram,生成batch generator:
假设现在有一句”in addition to the function below”,就是将其变为(addition, in),(addition, to),(to, addition),(to, the),(the, to),(the, function)等,假设现在我们只能相邻的两个单词生成样本,也就是说每次是3个单词来生成样本对,假设是”addition to the”,我们需要生成”(to, addition)、(to the)”样本对,将其转换为单词的index,那么可能是(3, 55)、(3, 89)这样;然后向后滑动,此时3个单词变成”to the function”,然后重复上面的步骤
'''Step3: batch generator'''
data_index = 0
def generate_batch(batch_size, num_skips, skip_window):
global data_index
assert batch_size % num_skips == 0
assert num_skips <= (2 *skip_window) //对每个单词生成多少样本对
batch = np.ndarray(shape=(batch_size), dtype=np.int32)
labels = np.ndarray(shape=(batch_size, 1), dtype=np.int32)
span = 2 * skip_window + 1
buffer = collections.deque(maxlen=span)
for _ in range(span):
buffer.append(data[data_index])
data_index = (data_index + 1) % len(data)
for i in range(batch_size // num_skips):
target = skip_window //单词之间联系的距离
targets_to_avoid = [skip_window]
for j in range(num_skips):
while target in targets_to_avoid:
target = random.randint(0, span -1)
targets_to_avoid.append(target)
batch[i * num_skips + j] = buffer[skip_window]
labels[i * num_skips + j, 0] = buffer[target]
buffer.append(data[data_index])
data_index = ( data_index + 1) % len(data)
return batch, labels
训练
随机生成所有单词的词向量,因为有负样本的存在,所以最终其实是变为一个分类问题,loss使用NCE(noise-contrastive estimation) loss.
TF中对于word2vec,有两种loss:
1. sampled softmax
2. NCE
当然这两种也可用于任意的分类问题.
那么为什么不直接上softmax呢?
主要是对于word2vec来说,需要分类的类别太多,sampled softmax和NCE都是一种简化版的softmax.
- The basic idea is to convert a multinomial classification problem (as it is the problem of predicting the next word) to a binary classification problem. That is, instead of using softmax to estimate a true probability distribution of the output word, a binary logistic regression (binary classification) is used instead.
- For each training sample, the enhanced (optimized) classifier is fed a true pair (a center word and another word that appears in its context) and a number of kk randomly corrupted pairs (consisting of the center word and a randomly chosen word from the vocabulary). By learning to distinguish the true pairs from corrupted ones, the classifier will ultimately learn the word vectors.
- This is important: instead of predicting the next word (the “standard” training technique), the optimized classifier simply predicts whether a pair of words is good or bad.
可以看看下面的两个资料:
[通俗的解释NCE loss] https://www.zhihu.com/question/50043438/answer/254300443
[understand NCE in word2vec] https://stats.stackexchange.com/questions/244616/how-sampling-works-in-word2vec-can-someone-please-make-me-understand-nce-and-ne/245452#245452
'''Step 4: training'''
batch_size = 128
embedding_size = 128
skip_window = 128
num_skips = 2
valid_size = 16
valid_window = 100 //进行validation的单词数量
valid_examples = np.random.choice(valid_window, valid_size, replace=False)
num_sampled = 64 //负样本的单词数量
graph = tf.Graph()
with graph.as_default():
train_inputs = tf.placeholder(tf.int32, shape=[batch_size])
train_labels = tf.placeholder(tf.int32, shape=[batch_size, 1])
valid_dataset = tf.constant(valid_examples, dtype=tf.int32)
with tf.device('/cpu:0'):
embeddings = tf.Variable(tf.random_uniform([vocabulary_size, embedding_size], -1.0, 1.0)) //随机生成词向量
embed = tf.nn.embedding_lookup(embeddings, train_inputs)
nce_weights = tf.Variable(tf.truncated_normal([vocabulary_size, embedding_size], stddev=1.0/math.sqrt(embedding_size)))
nce_biases = tf.Variable(tf.zeros([vocabulary_size]))
loss = tf.reduce_mean(tf.nn.nce_loss(weights=nce_weights,
biases=nce_biases, labels=train_labels,
inputs=embed, num_sampled=num_sampled,
num_classes=vocabulary_size)) //使用NCE loss
optimizer = tf.train.GradientDescentOptimizer(0.1).minimize(loss)
norm = tf.sqrt(tf.reduce_sum(tf.square(embeddings), 1, keep_dims=True))
normalized_embeddings = embeddings / norm
valid_embeddings = tf.nn.embedding_lookup(normalized_embeddings, valid_dataset)
similarity = tf.matmul(valid_embeddings, normalized_embeddings, transpose_b=True)
init = tf.global_variables_initializer()
num_steps = 1000000
with tf.Session(graph=graph) as session:
init.run()
print('Initialized')
average_loss = 0
for step in range(num_steps+1):
batch_inputs, batch_labels = generate_batch(batch_size, num_skips, skip_window)
feed_dict = {train_inputs: batch_inputs, train_labels: batch_labels}
_, loss_val = session.run([optimizer, loss], feed_dict=feed_dict)
average_loss += loss_val
if step % 2000 == 0:
if step > 0:
average_loss /= 2000
print('Average loss at step %d : %.4f' % (step, average_loss))
average_loss = 0
if step % 10000 == 0:
sim = similarity.eval()
for i in range(valid_size):
valid_word = reverse_dictionary[valid_examples[i]]
top_k = 5
nearst = (-sim[i, :]).argsort()[1:top_k+1]
log_str = 'Nearst to %s:' % valid_word
for k in range(top_k):
close_word = reverse_dictionary[nearst[k]]
log_str = '%s %s,' % (log_str, close_word)
print(log_str)
final_embeddings = normalized_embeddings.eval()这里原书设置的是learning rate=1.0, steps=100000,跑这个例子发现就会发现loss的值在波动,出现过拟合,所以我把迭代次数增加,lr降低为0.1
我的结果:
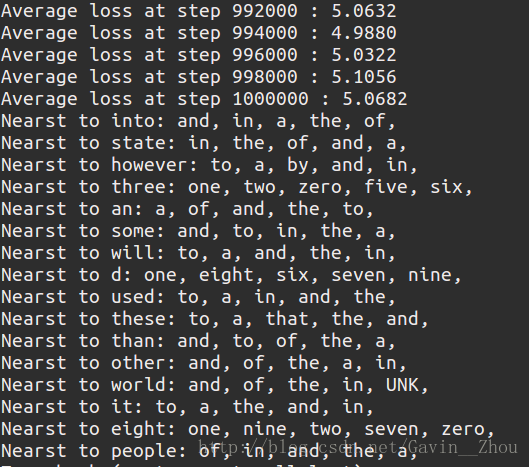
我的结果跟原作者的不一样,loss降不到作者那么低,可能再跑几个step loss还会降低点,谁知道原因的请告诉我!
可视化
先把单词的维度降成2维,然后画个散点图,理论上来说相同词性的词之间距离比较近.
'''Step 5: visualization'''
from sklearn.manifold import TSNE
import matplotlib.pyplot as plt
def plot_with_label(low_dim_embs, labels, filename='tsne.png'):
assert low_dim_embs.shape[0] >= len(labels), 'More labels than embeddings'
plt.figure(figsize=(18,18))
for i , label in enumerate(labels):
x, y= low_dim_embs[i, :]
plt.scatter(x, y)
plt.annotate(label,
xy=(x,y),
xytext=(5,2),
textcoords='offset points',
ha='right',
va='bottom')
plt.savefig(filename)
tsne = TSNE(perplexity=30, n_components=2, init='pca', n_iter=5000)
plot_only = 3000
low_dim_embs = tsne.fit_transform(final_embeddings[:plot_only, :])
labels = [reverse_dictionary[i] for i in range(plot_only)]
plot_with_label(low_dim_embs, labels)结果:
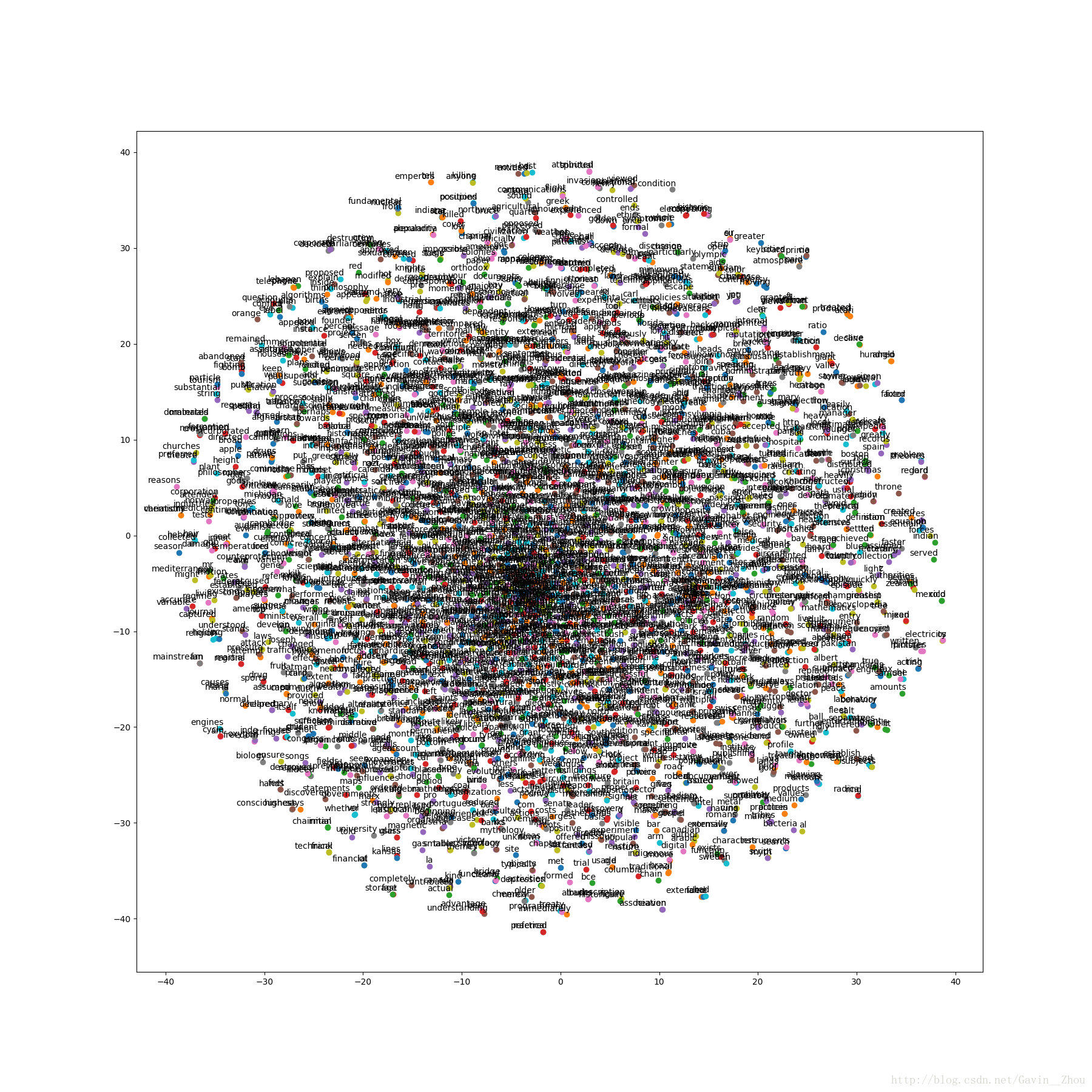
代码我也传上来吧,跟原书几乎一致,有需要的可以下载, http://download.csdn.net/download/gavin__zhou/10149281
我的博客即将同步至腾讯云+社区,邀请大家一同入驻。














 773
773











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









