







一元线性回归与梯度下降算法
继续看之前的一个例子,如下图,我们的数据中有lstat和medv这两个变量。
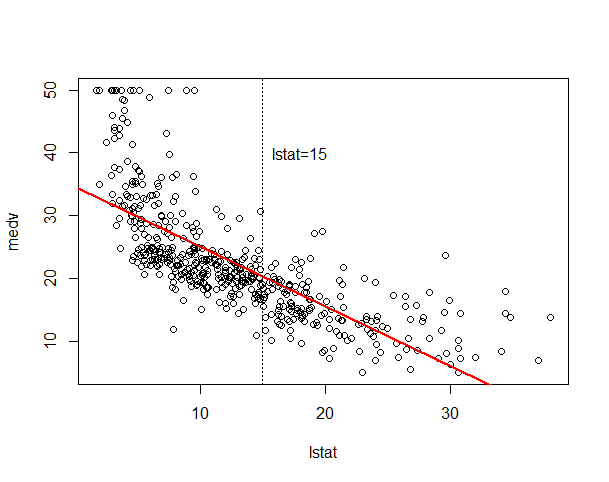
现在有一个新的数据lstat=15,这里我们想要找到一条直线,并且想要通过这条直线对medv值做出预测,这个问题可以更具体的称之为回归问题,这里所谓的回归,就是根据之前的数据预测出一个准确的输出值。
首先来定义一些符号:
n
: 样本量
y
:输出变量/目标值
这里我们可以用
现在我们想要找到一个模型
这里 β0 和 β1 为参数,不同的参数对应不同模型,如下图,三组不同的参数对应三条不同的回归直线。
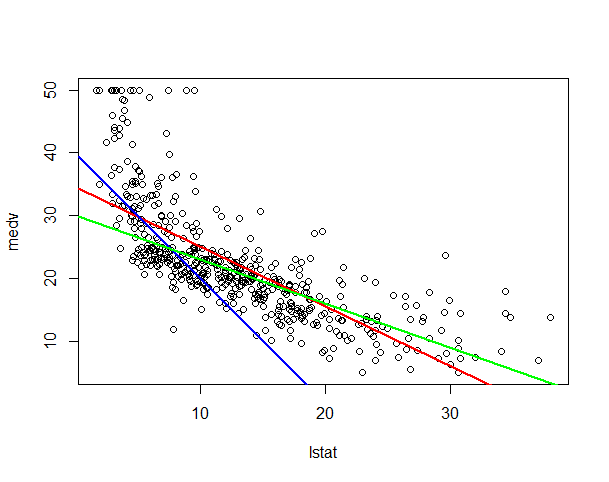
对于不同的回归模型,如何做出选择?直观的,我们想要我们的模型能够更好的拟合数据。这里,我们的目的就是选取合适的 β0 和 β1 使的对于训练数据, f(x) 能够更加靠近 y 。这是一个优化问题,下面我们给这个优化问题一个标准化的定义:
统计上称 ∑ni=1(f(xi)−yi)2 为残差平方和,记为RSS。下面我们要做的就是找到 β0 和 β1 使得残差平方和RSS最小。这里,损失函数可以写为:
这里,还可以称这个损失函数为平方损失,平方损失对于绝大多数回归问题都是一个很不错的选择;当然也有其他损失函数,比如绝对值损失,但平方损失是回归问题中最常用的手段。
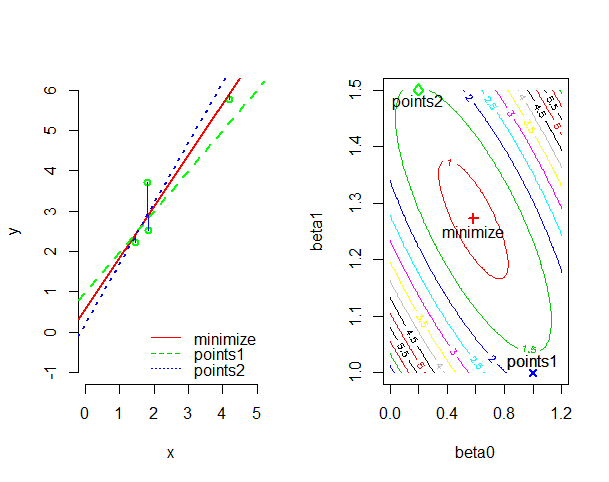
下面我们先来看一下平方损失的几何意义。首先来看一个简单的例子,如下图左图,我们的目的是拟合的直线与训练样本的差值的平方和最小;右图是平方损失函数 J(β0,β1) 等高线,不同的 β0 和 β1 值对应着不同的损失值,也对应着不同的回归直线。当 β0 和 β1 取右图中点1是,对应的回归直线为左图中的蓝色直线;取点2时对应的是左图中的红色直线。
当 β0=0.5825 , β1=1.2715 时损失函数 J(β0,β1) 最小,这时对应着的是左图中的红色直线,也就是我们的最小二乘拟合。
有了损失函数 J(β0,β1) ,我们就需要一些方法来解这个优化问题。下面介绍一种常用的算法:梯度下降算法。
损失函数: J(β0,β1)
目的: minβ0,β1J(β0,β1)
算法概述:
- 初始化 β0 , β1 ,比如初始化 β0=0 , β1=0 。
- 更新 β0 和 β1 以降低 J(β0,β1) 值,直至收敛。
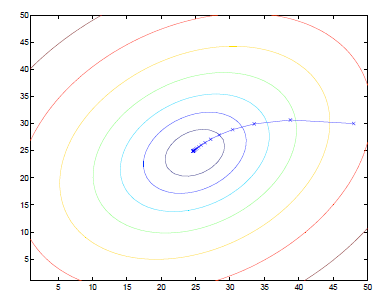
梯度下降算法能够解决很多优化问题,它的计算过程就是沿梯度下降的方向求解极值。我们在梯度下降算法中所需要做的就是不断的改变 β0 和 β1 的值,并且试图通过这种改变使得 J(β0,β1) 变小(如下图)。
梯度下降算法伪代码:
repeat until convergence{
βj:=βj−α∂∂βjJ(β0,β1), (simultaneous update j=0 and j=1)
}
这里符号
:=
表示赋值,
α
是一个常数代表学习率,它所控制的是梯度下降时每一步所迈的步长,当
α
比较小时,梯度下降算法可能运行的比较慢,当
α
比较大时,则可能会跳过最小值,以至于算法难以收敛;
∂∂βjJ(β0,β1)
是导数项。
在梯度下降算法中需要注意的是,
β0
和
β1
的值需要同时更新,而且梯度下降算法可能会陷入一个局部最小值;在线性回归中,优化问题是凸的,算法总是会收敛到全局最小值。
下面我们看如何用梯度下降算法解决线性回归问题。
对于线性回归模型,我们有:
线性假设: f(x)=β0+β1x
损失函数: J(β0,β1)=12n∑ni=1(f(xi)−yi)2
使用梯度下降算法最关键的就是对要求
J(β0,β1)
对
β0
和
β1
的偏导数。通过简单的运算,可以得出:
有了这个公式,重新写一下梯度下降算法伪代码。
repeat until convergence{
β0:=β0−α1n∑ni=1(f(xi)−yi)
β1:=β1−α1n∑ni=1(f(xi)−yi)xi
}
下面就是梯度下降算法的R语言实现,这个算法比较简单。
#linear regression by gradient decent algorithm
#auther: JiZhG
#
#gradient decent algorithm for linear regression
#x: input
#y: output
#alpha: learning rate default alpha=0.05
#iter: max iterations default alpha=1e+5
#tol default 1e-10
LinearRegression=function(x,y,alpha=0.05,iter=1e+5, tol=1e-10){
n=length(y)
x=cbind(rep(1,n),x)
p=dim(x)[2]
beta=rep(0,p)
temp=rep(0,p)
i=1
while(i<iter){
beta_old=beta
for(j in 1:p){
temp[j]=1/n*sum((x%*%beta-y)*x[,j])
}
beta=beta-alpha*temp
#conv
if(sum(abs(beta-beta_old))<tol) break
i=i+1
}
beta
}模拟数据并应用该算法:
#Simulation y=2x+epsilon
set.seed(1)
x=rnorm(100,3,1)
set.seed(10)
y=2*x+rnorm(100,0,1)
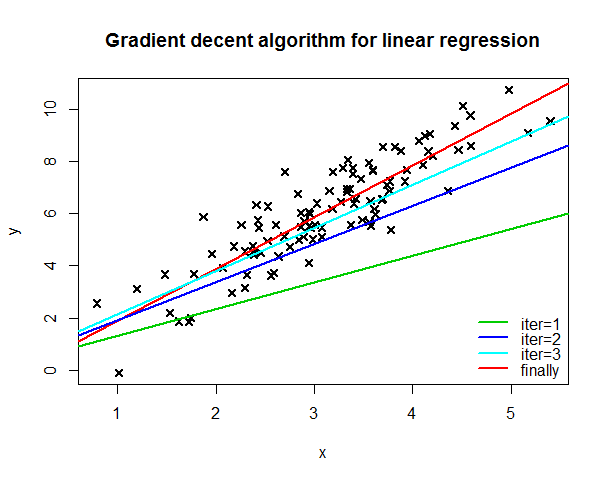
plot(x,y,pch=4,lwd=2,main="Gradient decent algorithm for linear regression")
#
beta=LinearRegression(x,y)
#beta
#[1] -0.1032774 1.9893028
abline(a=beta[1],b=beta[2],col=2,lwd=2)迭代解决这个优化问题,下图分别是第一、二、三次迭代得到的回归直线和最终得到的回归直线,最优解为
β0=−0.1032774
和
β1=1.9893028
。















 524
524

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









