







目录
线性回归
线性回归是利用数理统计中回归分析,来确定两种或两种以上变量间相互依赖的定量关系的一种统计分析方法,运用十分广泛。
回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。
一元线性回归
从上述定义中,我们可以知道,回归分析中,只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归称为一元线性回归分析,一元线性回归回归是的一种,评估的自变量X与因变量Y之间是一种线性关系。当只有一个自变量时,称为一元线性回归。
我们要知道理解什么是线性?,通俗的来讲就是我们求出来的图像是一条直线,自变量的最高次项为1,
拟合是指构建一种算法,使得该算法能够符合真实的数据。
从机器学拟合习角度讲,线性回归就是要构建一个线性函数,使得该函数与目标值之间的相符性最好。从空间的角度来看,就是要让函数的直线(面),尽可能靠近空间中所有的数据点(点到直线的平行于y轴的距离之和最短)。
线性回归模型:
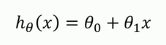
例如我们有了一些房子面积和对应价格的数据,我们可以拟合一条直线,使其尽可能符合房子面积与价格的关系,(也就是是样本点都尽可能落在我们拟合的直线附近)
那么我们应该怎么拟合这条直线呢?我们首先要知道损失函数。
损失函数
损失函数也称目标函数或代价函数,简单来说就是关于误差的一个函数。损失函数用来衡量模型预测值与真实值之间的差异。机器学习的目标,就是要建立一个损失函数,使得该函数的值最小。
也就是说,损失函数是一个关于模型参数的函数,自变量可能的取值组合通常是无限的,我们的目标,就是要在众多可能的组合中,找到一组最合适的自变量组合,使得损失函数的值最小。
损失函数用来评价模型的预测值和真实值不一样的程度,损失函数越小,通常模型的性能越好。不同的模型用的损失函数一般也不一样
通俗来讲就是,用数据的真实值去减去采用函数模型得到的预测值,计算的是一个样本的误差。它是用来估量你模型的预测值 f(x)与真实值 Y的不一致程度。
公式为 LOSS=真实值-预测值
对于一元线性回归而言。我们通常用均方差损失函数:

我们有了损失函数我们又应该怎么求出它的最小值呢?这里1我们就要用到梯度下降法了。
梯度下降
梯度下降(gradient descent)在机器学习中应用十分的广泛,不论是在线性回归还是Logistic回归中,它的主要目的是通过迭代找到目标函数的最小值,或者收敛到最小值。
偏导:
在一元函数中,导数就是函数的变化率。对于二元函数的“变化率”,由于自变量多了一个,情况就要复杂的多。
在 xOy 平面内,当动点由 P(x0,y0) 沿不同方向变化时,函数 f(x,y) 的变化快慢一般来说是不同的,因此就需要研究 f(x,y) 在 (x0,y0) 点处沿不同方向的变化率。
在这里我们只学习函数 f(x,y) 沿着平行于 x 轴和平行于 y 轴两个特殊方位变动时, f(x,y) 的变化率。
偏导数的表示符号为:∂。偏导数反映的是函数沿各个坐标轴正方向的变化率。梯度的最大方向就是方向导数方向也就是数值变化最快的方向。
梯度下降;
我们可以用下山作为例子:(这里引用别人所举出的例子)
假设这样一个场景:一个人被困在山上,需要从山上下来(找到山的最低点,也就是山谷)。但此时山上的浓雾很大,导致可视度很低;因此,下山的路径就无法确定,必须利用自己周围的信息一步一步地找到下山的路。这个时候,便可利用梯度下降算法来帮助自己下山。怎么做呢,首先以他当前的所处的位置为基准,寻找这个位
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1270
1270











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









