







原理
论文地址:https://arxiv.org/pdf/1607.01759.pdf
简介
fastText是facebook在2016年提出的一个文本分类算法,是一个有监督模型,其简单高效,速度快,在工业界被广泛的使用。在学术界,可以作为baseline的一个文本分类模型。
模型结构
模型结构如下图所示,每个单词通过嵌入层可以得到词向量,然后将所有词向量平均可以得到文本的向量表达,在输入分类器,使用softmax计算各个类别的概率。
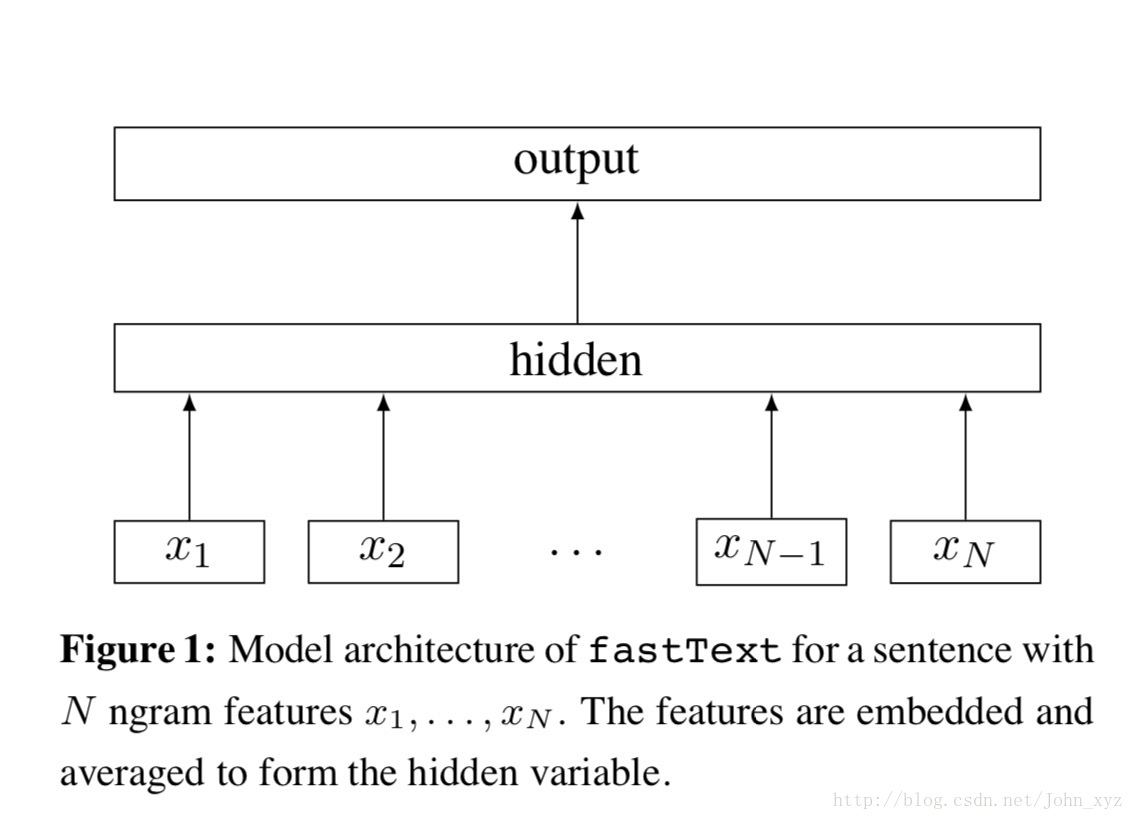
需要注意以下几个问题,:
- fastText没有使用预先训练好的词嵌入层
- 当类别很多时,fastText使用hierarchicla softmax加快计算速度
- fastText采用n-gram额外特征来得到关于局部词顺序的部分信息,用hashing来减少N-gram的存储
关于如何使用n-gram来获取额外特征,这里可以用一个例子来说明:
对于句子:“我 想 喝水”, 如果不考虑顺序,那么就是每个词,“我”,“想”,“喝水”这三个单词的word embedding求平均。如果考虑2-gram, 那么除了以上三个词,还有“我想”,“想喝水”等词。对于N-gram也是类似。但为了提高效率,实际中会过滤掉低频的 N-gram。否则将会严重影响速度
实践
利用fasttext训练分类器
# coding:utf-8
import fasttext
def train_ft(train_file):
# fasttext模型的前缀名称,训练的的模型是 前缀+'.bin'
ft_model_prefix = 'ft_model'
ft_model = fasttext.supverised(train_file, ft_model_prefix,
label_prefix='__label__')
return ft_model
def test_ft(ft_model, texts):
"""
testing fasttext models
:param texts: list of str
:return: list of labels
"""
res= ft_model.predict(texts)
pred_labels = [item[0] for item in res]
res_prob = ft_model.predict(texts)
# 取出概率最大的标签概率二元组
pred_labels_probs = [item[0] for item in res_prob]
return pred_labels训练模型:
训练模型过程中,输入的文件train_file,每一行是一个样本,其中前缀是’__label__’, 之后是文本的分词结果。标签和文本用空格分开。示例train_file如下
__label__beauty 身高 170 + 女星 , 唐嫣 王鸥 古力娜扎 , 谁 街拍 最 有 范 郭碧婷 170 cm 王鸥 170 cm 古力娜扎 172 cm 胡杏儿 172 cm 唐嫣 170 cm 毛晓彤 171 cm
__label__beauty 这样 的 足球宝贝 , 我 觉得 美女明星 都 要 自愧不如 了 , 美 的 怀疑 人生 这样 的 足球宝贝 , 我 觉得 美女明星 都 要 自愧不如 了 , 美 的 怀疑 人生
__label__beauty 美女 摄影 : 白兔 美女主播 半仙 制服诱惑 被 封 宅男 杀手
__label__beauty 美腿 蛮腰 的 性感美女 诱人 私房 照 美腿 蛮腰 的 性感美女 诱人 私房 照
__label__beauty 这 性感 的 黑色 吊带 高跟鞋 , 美 的 不 像话 ! 这 性感 的 黑色 吊带 高跟鞋 , 美 的 不 像话 !
__label__beauty 微风 下 的 清纯 小 女生 随风 飘逸 动感 微风 下 的 清纯 小 女生 随风 飘逸 动感
__label__beauty 街拍 : 白色 碎花 短裙 长腿美女 往下 一看 我 发现 点 东西 ! 街拍 : 白色 碎花 短裙 长腿美女 往下 一看 我 发现 点 东西 ! 测试模型:
测试fasttext模型时,输入的是texts是列表类型,列表里的每个元素是切词好的文本,示例如下:
['美腿 蛮腰 的 性感美女 诱人 私房 照 美腿 蛮腰 的 性感美女 诱人 私房 照', '微风 下 的 清纯 小 女生 随风 飘逸 动感 微风 下 的 清纯 小 女生 随风 飘逸 动感', '街拍 : 白色 碎花 短裙 长腿美女 往下 一看 我 发现 点 东西 ! 街拍 : 白色 碎花 短裙 长腿美女 往下 一看 我 发现 点 东西 !']关于fasttext的更多用法参考
https://pypi.python.org/pypi/fasttext














 604
604











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









