









这里先再次提出我们利用aggregation获取更好性能的Hypothesis G所涉及的方法:blending,就是在得到g_set之后进行融合;learning呢?就是在线online的获取g并融合。下面就是关于整个aggregation所涉及到的方法总结:

其中Bagging、AdaBoost我们都已经探讨,它们分别是基于uniform(voting / average)和non-uniform(linear)的aggregation type,那么下面就开始介绍一个基于conditional的learning model:decision tree(决策树)。
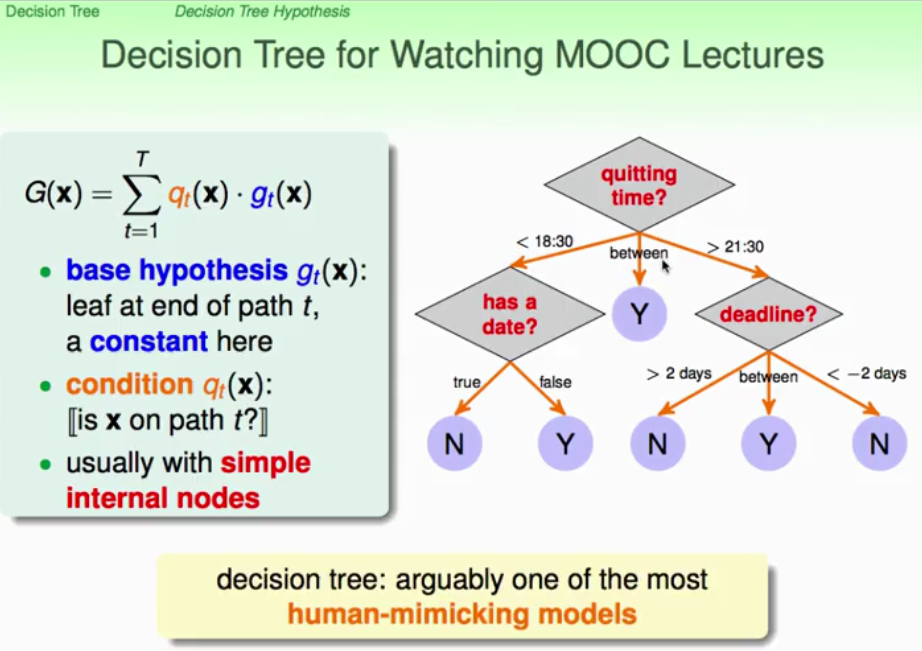
它实际上是模仿人类的决策过程,在C语言中很常见的if...else...语句就可以看作是非常简单的decision tree。看我们如何利用aggregation进行演进,如下图,我们希望internal nodes(内部的决策过程)都要非常简单。从入口处将状况进行分开为不同的branch,Gc(x)作为一个独立的Sub-Tree。就是把一颗大Tree,配合上分支条件,分拆为小点的树,实际上就是一个递归结构的定义。tree = (root, sub-trees),root根部告诉我们如何做branch。

 订阅专栏 解锁全文
订阅专栏 解锁全文















 6807
6807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











