







本文提出了一种基于CNN特征,通过分析场景中的元目标(meta objects)进而进行场景分析的流程。这里的假设就是一个场景的类别通常与场景中包含的物体有关,场景的物体就对应所说的meta object。要分析图片中的物体就要进行分割,然后选择有效的分割区域,再将这些区域构造整个图的特征用于分类。这个流程可以分为五个部分:在整个图片上构造region proposal选取patch、对patch进行选取保留对应图片中有效的meta object的patch、对保留的patch进行聚类分析、构造整个图片的特征、分类。文章用下图表示:
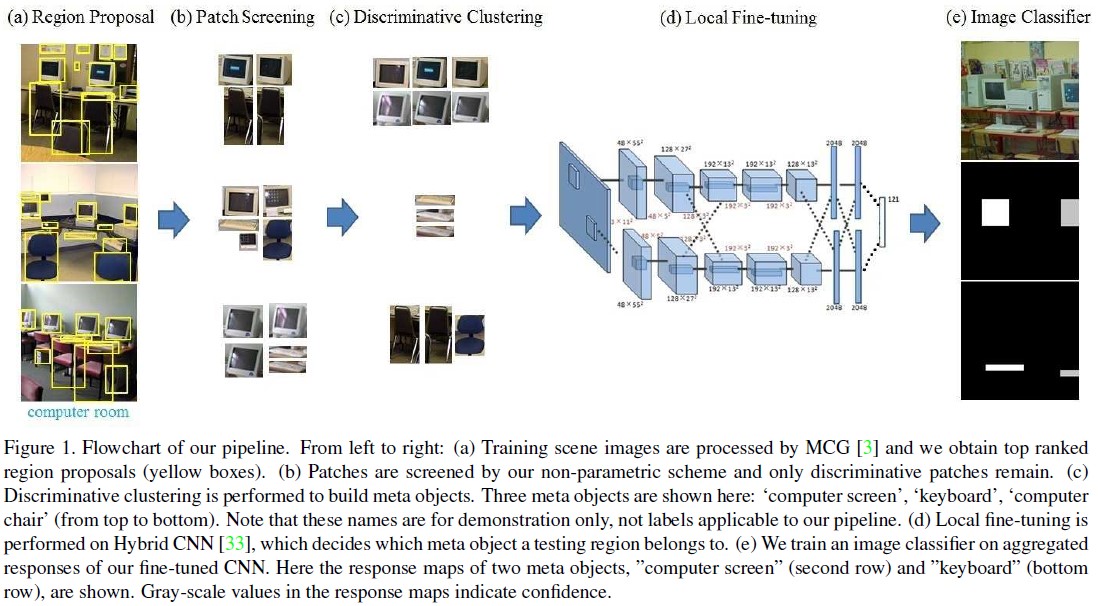
下面分别分析这五个部分。
1)region proposal generation
由于本文要分析scene image中的object,首先要提取恰当的proposal。
提取场景图片中的region proposal,本文采用的是2014cvpr文章Arbeláez P, Pont-Tuset J, Barron J, et al. Multiscale combinatorial grouping[C]中提出的MCG方法。文章提到也可以用edge box和selective search 来生成proposal的方法。提取到proposal之后,用在Places数据集上预训练的CNN模型来提取特征。使用FC7层的特征作为patches的特征。
2)patch screening
为每类选择具有代表性的patches,同时根据每个patch对scene image判别的帮助信息(转化为后验概率)来给出一个权重,具体分为两个部分:
(一)首先对每个类中所有图像提取的patches进行一
 本文提出了一种利用CNN特征分析场景中的元目标进行场景分类的方法。通过region proposal生成、patch筛选、meta object创建与分类、图像表示及图像分类等步骤,实现了对场景图像的有效分析。实验表明,聚类和分类器的优化对于提升分类精度至关重要。
本文提出了一种利用CNN特征分析场景中的元目标进行场景分类的方法。通过region proposal生成、patch筛选、meta object创建与分类、图像表示及图像分类等步骤,实现了对场景图像的有效分析。实验表明,聚类和分类器的优化对于提升分类精度至关重要。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1753
1753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









