









文章提出一个pipeline从场景训练集中挖掘代表性的元素(meta object),将一幅图像用这些meta object表示,得到了state-of-the-art的分类效果。
论文来自ICCV2015
1 Motivation
假设:场景的类别与场景中的目标有关。
本文借鉴BOW思想,用整个训练集提取出representative and discriminative meta object,用category-specific的object表示图像。
2 Method
文章提出的pipeline分5步,图示如下:
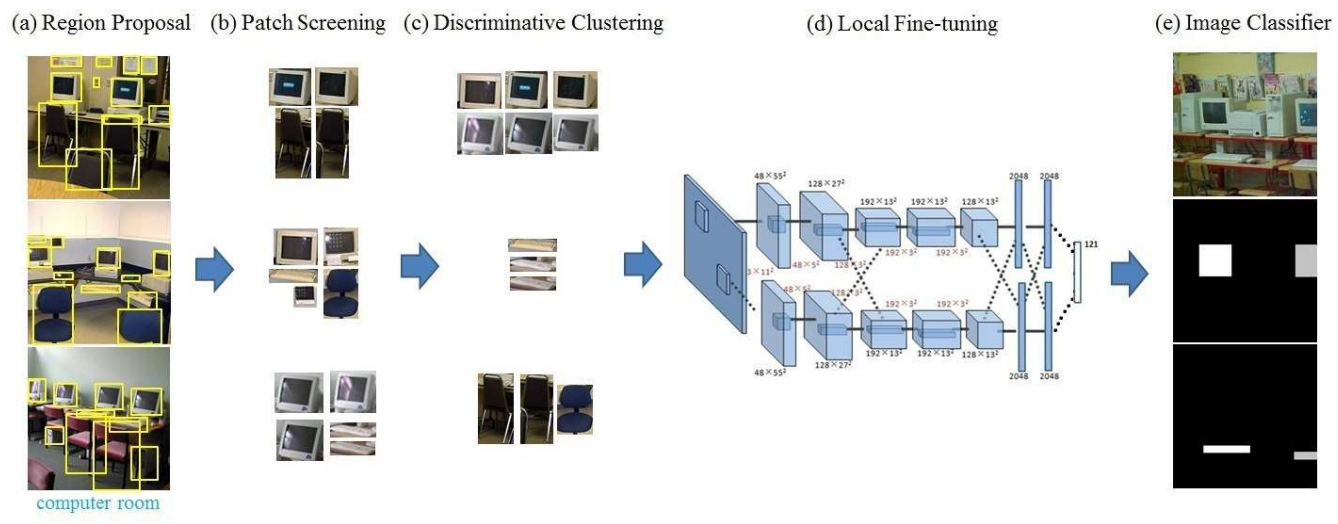
Step 1:得到object candidates
- 用MCG1 (Multiscale combinational grouping)得到region proposals
MCG是基于图片的空间金字塔分割,将多尺度的分割结果合并后得到candidates,能够更好地捕获细节,得到更精确的proposal。
- 对得到的patch用Hybrid-CNN2提取特征,使用fc7层输出作为patch的特征。
Hybrid-CNN是用Places数据集(场景图片数据集)和ImageNet的图片数据集一起训练得的网络,更适用于场景图片。
Step 2:筛选object
- 通过one-class SVM3去除outliers,也就是在特征空间中和其他patch都不靠近的点。
目标函数:
min12∥w∥2+1vl∑lξi−ρ
(w⋅Φ(xi))≥ρ−ξi,xii≥0,i=1,2,…,l
决策函数:
f(x)=sign(w⋅Φ(xi)−ρ)
其中, l 是样本个数,
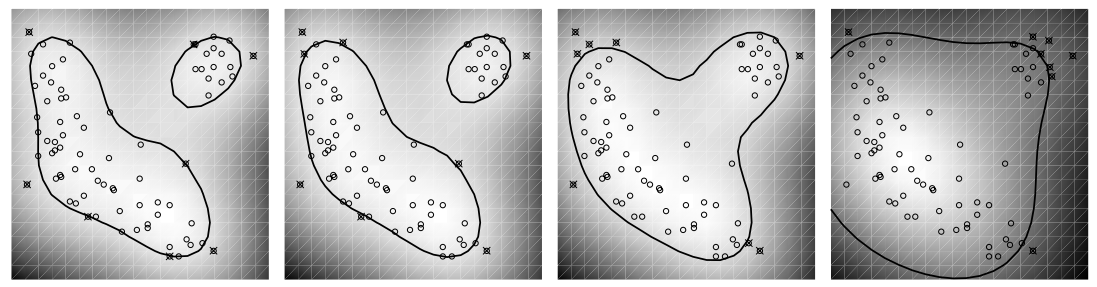
下图是v={0.1, 0.2, 0.4}时
ρ
的变化,可以看到为了去掉更多outlier,分类面在收缩。
- 通过weakly supercised soft screen得到判别性强的patch
为图片
i
中的patch
wij=P(yi∣pij)=P(pij,yi)P(pij)≈Ky/K.
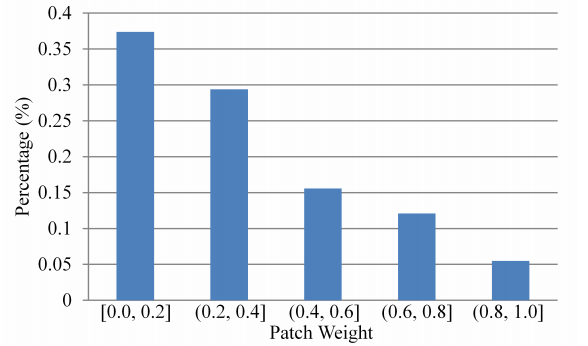
从下图可以看出,代表性patch其实是不多的。
Step 3:得到meta object
- 用RIM4(Regularized Information Maximization)对所有patch聚类,聚类中心就是meta object,目的是分析整合representative patch中的语义信息。
聚类结果示例:

Step 4:编码图像特征
- 用所有patch来fine tune一个CNN,输出结点是meta object,这个CNN用来做patch分类。
- 用meta object作为codebook表示图像,用SPM5或VLAD6做pooling。
- 得到的图像特征,再和整幅图的CNN串联,作为最终的图像特征表示。
Step 5:分类
- 用有2层隐含层的神经网络,共4层;
- 每个隐含层200个节点,输入层是图像特征,输出层是图像label;
- 用Relu作为激励函数;
3 Experiment
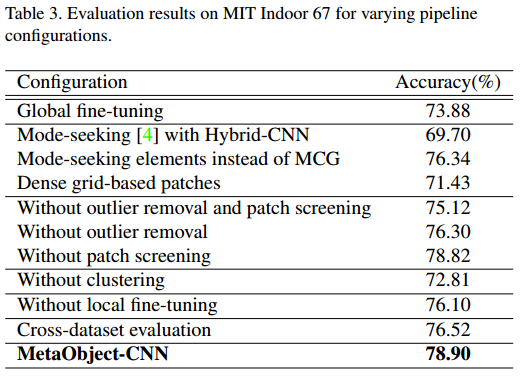
实验中对pipeline的每一个环节都做了验证。
4 Summary
- meta object实际上是proposal的聚类结果,而proposal本身只是object候选框,在后面的meta object挖掘过程中并没有调整这些proposal的内容,所以要依赖于高质量的proposal。
- 挖掘discriminant patch时没有用准确的标号信息,限制了挖掘能力。
- Multiscale combinatorial grouping. CVPR 2014 ↩
- Learning deep features for scene recognition using places database. NIPS 2014 ↩
- Estimating the support of a high-dimentional distribution. Neural Comput. 2011 ↩
- Discriminative clustering by regularized information maximization. NIPS 2010 ↩
- Linear spatial pyramid matching using sparse coding for image classification. CVPR 2009 ↩
- Aggregating local descriptors into a compact image representation. CVPR 2010 ↩















 1537
1537

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









