






 本文深入探讨了相异性搜索的概念及其在数据分析中的应用,通过实例展示了如何利用相异性搜索寻找与现有环境最相似或最不相似的对象。文章强调了相异性搜索在目标设定、比较分析及决策制定过程中的作用,提供了实用的工具和方法,旨在帮助读者在复杂数据中发现有价值的信息。
本文深入探讨了相异性搜索的概念及其在数据分析中的应用,通过实例展示了如何利用相异性搜索寻找与现有环境最相似或最不相似的对象。文章强调了相异性搜索在目标设定、比较分析及决策制定过程中的作用,提供了实用的工具和方法,旨在帮助读者在复杂数据中发现有价值的信息。

莎老爷子著名的四大悲剧之一的哈雷王子。。。里面这句话一直是文艺小青年们zhuangbility的金牌用语……实际上说出了这样一句大实话:千古艰难惟一死。
人为什么怕死,无非就是没有死过而已。如果想一个人没事一天就死个十回八回的,那么有何可怕?这就是一切生物最原始的一种恐惧:对于未知的恐惧。
所以呢,我们都习惯找一个熟悉的地方,和一群熟悉的人,聊一些熟悉的话题……当然,不可能永远都在熟悉的圈子里面打转,人总是要走出去的。
所以退一万步,我们就需要找到一个与我们熟知内容所相似的情况。
比如租房,如果现在这个地方住的很舒服,但是因为黑心房东而不得已要搬走的话,我们就很希望找一个与当前环境条件租金啥的,都很相似的地方。
找工作的话,当然也是一样。
这样,就引出今天的题目:相似性搜索。
通俗意义上来说,就是给出条件,然后从所有数据中,找到与给出数据最相似的那些数据。注意的是:相似不是相同,相似更接近于客观世界规律。自然界中不可能有两片完全相同的叶子。
相似性搜索的功能描述如下:
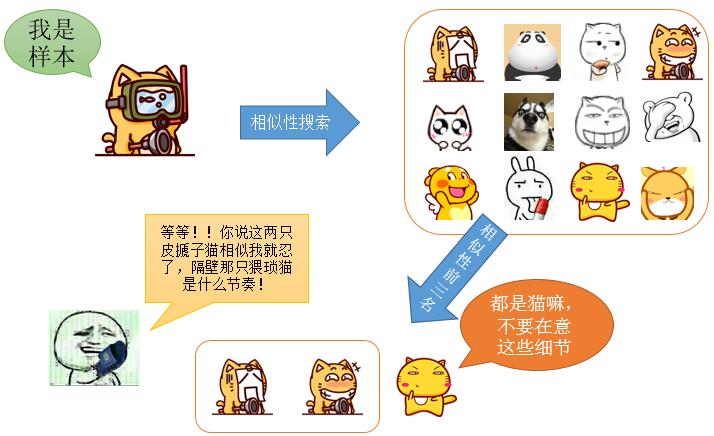
从上面可以看出,相似性搜索,给你的是最相似(或者取反就是相异)的数据,而不是去搜索完全一样的数据。
传统的数据库搜索匹配理论,是所谓的二分论,即“非黑即白”,比如我们敲入一个SQL命令,那么数据库一般都会给你两种结果:yes or no,这种就是所谓的确定性搜索,给你的都是完全满足你条件的记录,而相似性搜索,会给出你一些基于概率值的结果,而概率论,正式统计学的根基,不管是空间统计还是经典统计。
相似性搜索的原理,更接近客观世界的认知,所以我们会花比较多的篇幅来进行描述。实际上今年虾神我也准备写很多有关聚类的内容,而聚类所谓的相似的归为一类,这个相似,很多时候就是用相似性搜索的算法来实现的。
在分析软件中(不管是ArcGIS还是其实的啥神器),分析都是基于数值属性来实现的(统计只与数值有关,所有的非数值型的变量,都会变变化为数值型之后才能进行统计),那么这里的相似性搜索,也是只能基于数值型属性来进行分析。
那么有同学问,我如果对好多个指标都要分析呢……那么ArcGIS采取了一个简单粗暴的方法——基于平均值来进行计算。好吧,如果要深入的话,可以自己重新实现一下这个算法,引入权重系数的模式,这个东东作为进阶内容,在这里暂时不做详细叙述。
在详细说各种算法之前,首先讲讲这个神器的一般在什么地方使用。
首先,确定目标的时候,很有用。这个目标可以是对比的目标,或者追赶的目标。正如网络上经常流行的一个段子:
突然觉得中国真是真心不容易:
国力要和美国比;
福利要和北欧比;
环境要和加拿大比;
机械制造要和德国&日本比;
人均GDP要和卢森堡比(卢森堡2013年全国人口约为54万人,仅为北京天通苑小区的三分之二)
……
一个国家要vs全世界的高端。
这就一种盲目的确定目标了。
所以,要学会选择目标。比如老夫也想和思聪比生活品位;或者和三胖比霸气……好吧,我也就想想而已。
所以,我们在比较之前,可以以中国为样本,然后在全世界范围内,搜索最相似的内容,作为中国的目标即可。如下:
首先用人口、国土面积、GDP总量以及人均GDP均衡计算后,进行相似度搜索,直接不考虑空间关系,采用属性匹配法,获得10个有代表性的国家,得到的结果如下:
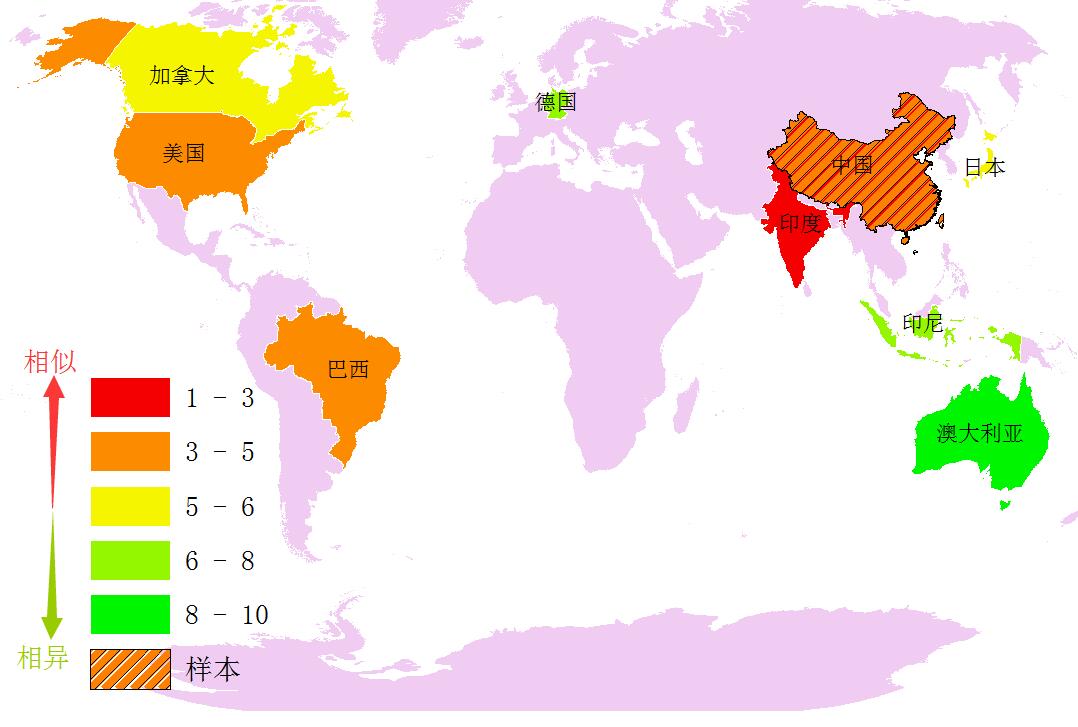
与中国最相似的:印度(此次应有掌声,三哥天天以中国为假想敌是有道理的)。

与中国有点相似的:美国(中国的国土面积和GDP总量与美国太相像了)、巴西(we are 五星球队)有点相似。

最后,多说一句,这里的排名,是以这10个有代表性的国家里面进行排名的,假定他们10个代表全世界,所以我们这里看见的澳大利亚的相似度排名第9,并不代表他是前10名,而是代表他位于与中国非常不相似(相异)的区间段了。
当然,数据项太少,并没有太大的说服力,还是那句话,这里科普工具嘛,不要在意这些细节了。
下一篇我们来详细说说这个工具如何使用。


















 3260
3260

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











