







 超级会员免费看
超级会员免费看
我们在之前文章《K-means算法原理与R语言实例 》中介绍过著名的k-means聚类算法。通常,利用k-means算法进行聚类时需要事先知道cluster的个数,也就是k值。本文要介绍的基于密度聚类的算法却可以在无需事先获知聚类个数的情况下找出不规则(oddly-shaped)的cluster。
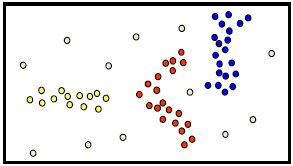
密度聚类的基本思想是:
- Clusters are dense regions in the data space, separated by regions of lower object density
- A cluster is defined as a maximal set of density connected

 订阅专栏 解锁全文
订阅专栏 解锁全文
















 144
144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











