







 本文详细介绍了Python中re模块的match、search、findall和split函数的使用,结合实例讲解了正则表达式的匹配、查找与替换操作,包括起始锚点、字符集等概念。
本文详细介绍了Python中re模块的match、search、findall和split函数的使用,结合实例讲解了正则表达式的匹配、查找与替换操作,包括起始锚点、字符集等概念。
这个章节以前没细看,现在接着看吧。
与之相关的功能都位于标准库模块re 中,因此首先需要引用它。你需要定义一个用于匹配的模式
(pattern)字符串以及一个匹配的对象:源(source)字符串
re.match函数
re.match(pattern,string, flags=0)
| pattern | 匹配的正则表达式 |
| string | 要匹配的字符串。 |
| flags | 标志位,用于控制正则表达式的匹配方式,如:是否区分大小写,多行匹配等等。 |
re.match 尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。
result = re.match('You', 'Young Frankenstein')
这里,'You' 是模式,'Young Frankenstein' 是源——你想要检查的字符串。match() 函数用于查看源是否以模式开头。
使用match()进行准确匹配
字符串'Young Frankenstein' 是以单词'You' 开头的吗?以下是一些带注释的代码:
>>> import re
>>> source = 'Young Frankenstein'
>>> m = re.match('You', source) # 从源字符串的开头开始匹配
>>> if m: # 匹配成功返回了对象,将它输出看看匹配得到的是什么
... print(m.group())
...
You
>>> m = re.match('^You', source) # 起始锚点也能起到同样作用
>>> if m:
... print(m.group())
...
You
尝试匹配'Frank' 又会如何?
>>> m = re.match('Frank', source)
>>> if m:
... print(m.group())
...
这一次,match() 什么也没有返回,if 也没有执行内部的print 语句。如前所述,match()
只能检测以模式串作为开头的源字符串。但是search() 可以检测任何位置的匹配:
>>> m = re.search('Frank', source)
>>> if m:
... print(m.group())
...
Frank
改变一下匹配的模式:
>>> m = re.match('.*Frank', source)
>>> if m: # match返回对象
... print(m.group())
...
Young Frank
以下是对新模式能够匹配成功的简单解释:
• . 代表任何单一字符;
• * 代表任意一个它之前的字符,.* 代表任意多个字符(包括0 个);
• Frank 是我们想要在源字符串中某处进行匹配的短语。
match() 返回了匹配.*Frank 的字符串:'Young Frank'。
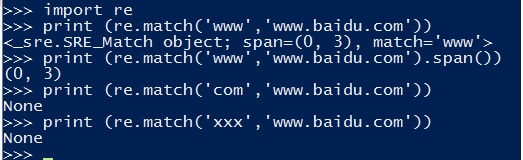
上面这个案子,如果后面不加span()这个参数,就无法返回(0,3)这个元组,这个元组代表着匹配到的索引位置是从0开始,3(但不包含3)结束.
实际上span()的意思就是 m.span() 返回一个tuple表示(m.start(), m.end(
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 519
519

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









