







参数化方法主要有两部分:
评分函数(score function):将原始数据(如图像数据)映射为类别分数向量;
损失函数(loss function):量化预测分数与真实标签值之间的差距。
整个过程可以视为一个最优化问题,通过持续更新评分函数中的参数值来使得损失函数最小化。
上一节介绍了一种简单的参数化方法——线性分类器,给出了它的评分函数,这一节主要介绍两种常用的损失函数及最优化的思想。
1.多分类支持向量机损失函数
2.Softmax分类器
3.优化
假设以CIFAR-10为训练集,训练一个线性分类器,在训练过程中某时刻评分函数的若干结果如下图所示:

第一幅图像是猫,而类别为猫的标签得分并不是最高的,分类错误,有三个类别的得分比它高;第二幅图像是汽车,类别为汽车的标签得分最高,分类正确;第三幅图像是青蛙,而类别为青蛙的标签得分极低,排倒数第二,分类错误。
那么,我们应该如何评价评分函数在整个训练数据集上的表现呢?答案就是定义一个损失函数,用来量化评分函数的预测得分与真实值间的差距。
1.多分类支持向量机损失函数(Multiclass SVM loss)
假设有样本
(xi,yi)
,其中
xi
是图像数据,
yi
是所属类别标签值,利用线性分类器分类,评分为
s=f(xi,W)
。
现在定义SVM损失函数如下:
Li=∑j≠yimax(0,sj−syi+1)
其中
i
表示样本索引,
那么,什么时候损失函数的值最小呢?当
sj−syi+1
项小于0时,即
sj>syi+1
或
sj−syi>1
。
可以看出,为了使得SVM损失函数最小化,不仅要求所属类别标签得分高于其他类别,还要高出一定的安全间隔(safety margin),也就是式中的1。
整个训练集损失定义为所有训练样本损失的均值,即所有样本损失总和除以样本数量:
L=1N∑Ni=1Li
举例说明SVM损失函数是如何工作的,假设训练集中三幅图像,分别在三个类别标签上的得分如下:

第一幅图像的SVM损失:
L1=max(0,5.1−3.2+1)+max(0,−1.7−3.2+1)=2.9
第一幅图像是猫,类别为猫的得分3.2,如果其他类别得分低于2.2(3.2-1)时SVM损失函数取最小值0。类别为车的得分5.9,比2.2高出2.9,类别为青蛙的得分-1.7,低于2.2,所以SVM损失为2.9+0=2.9
第二幅图像的SVM损失:
L2=max(0,1.3−4.9+1)+max(0,2.0−4.9+1)=0
第二幅图像是车,类别为车得得分4.9,如果其他类别得分低于3.9(4.9-1)时SVM损失函数取最小值0。另两个类别得分均低于3.9,所以SVM损失为0。
第三幅图像的SVM损失:
L3=max(0,2.2−(−3.1)+1)+max(0,2.5−(−3.1)+1)=12.9
第三幅图像是青蛙,类别为青蛙的得分-3.1,如果其他类别得分低于-4.1(-3.1-1)时SVM损失函数取最小值0。另两个类别得分均高于-4.1,分别高出6.3、6.6,所以SVM损失为6.3+6.6=12.9。(课件中计算为10.9,应该是忘了计算安全间隔+1)
那么整个训练集的SVM损失为:
L=(2.9+0+12.9)/3=5.267
经过SVM损失函数,就可以量化评分函数在训练样本上的表现。
课堂问答①:求取SVM损失时,如果是计算所有类别上的损失,即去掉SVM损失函数定义中求和不包括图像所属类别
(j≠yi)
的限制会有什么影响?
计算在所属类别上的SVM损失为
max(0,syi−syi+1)=1
,只是增加了一个常数项,不会影响最优化问题的求解,没有意义。
课堂问答②:SVM损失的定义是求和,如果用均值来代替会有什么影响?
均值就是求和除以类别数量,而类别数量是固定的,所以用均值来代替求和的话只是增加了一个常量系数,相当于对SVM损失函数值大小进行缩放,这和第一个问题中增加一个常数项一样,并不会影响到最优化问题的求解,没有意义。
课堂问答③:如果SVM损失函数定义改写为
Li=∑j≠yimax(0,sj−syi+1)2
,会有什么影响?
不再像之前两问中,仅仅是增加常数项或常量系数,这样改写会使得每个样本所遵循的间隔(margin)发生不同的变化,不再是遵循统一的间隔限制。
原SVM定义中的称为合页损失(hinge loss),本问中的称为平方合页损失(squared hinge loss),第一个比较常用,但是第二个在某些情况下比第一个要表现的更好,所以这也算是一个超参数,需要根据实际情况来选择。
课堂问答④:SVM损失函数的最小值和最大值分别是多少?
最小值无疑就是0;最大值会达到无穷大,如果正确分类得分极低,每个样本的SVM损失会很大,总和会趋向无穷大。
课堂问答⑤:一般情况下我们会将可训练参数值初始化为很小的数值,所有评分基本上约等于0,那么此时的损失是多少?
答案就是类别数减一(#classes-1),所有评分约等于0,那么每个样本的SVM损失为类别数量减一,减一是因为不计算图像在所属类别的损失,整个训练集上的SVM损失也是类别数量减一。这并不是重点,重点是我们可以利用这个结论在训练开始时进行安全检查。训练刚开始时,所有可训练参数初始化为很小的数值,那么SVM损失应该约等于类别数量减一,如果实际计算结果符合该结论,那么损失函数的实现部分应该没有问题。
总结
对于线性分类器
f(x,W)=Wx
,在整个训练集上的多分类支持向量机损失函数为:
L=1N∑Ni=1∑j≠yimax(0,f(xi,W)j−f(xi,W)yi+1)
【注意】上面公式存在bug,假设发现一组参数
W
使得
显然不是,可以通过缩放获取无数组参数,举例如下:

为了解决这个问题,引入正则项(Regularization),那么最终损失函数定义如下:
其中,
λ
为正则项权重,是一个重要的超参数,
R(W)
为正则项,常用的形式有:
L2 regularization:
R(W)=∑k∑lW2k,l
L1 regularization:
R(W)=∑k∑l|Wk,l|
Elastic net (L1 + L2):
R(W)=∑k∑lβW2k,l+|Wk,l|
Max norm regularization
Dropout
其中L2正则项最为常用。
浅显解释为何使用正则项,以L2正则项为例,假设样本
x=[1,1,1,1]
,一组参数为
w1=[1,0,0,0]
,另一组为
w2=[0.25,0.25,0.25,0.25]
,那么有
wT1x=wT2=1
,不引入正则项时损失函数相同,但考虑正则项后,
w2
要优于
w1
,因为
w2
的L2正则项更小,则整体的损失函数更小。
w2
中的参数相比较
w1
来说更加分散,使得更多的输入维度参与决策,而不是有少量几个维度决定,提高了模型的泛化能力。
2.Softmax分类器(多分类逻辑回归)
将预测评分视作未标准化的对数概率,那么标准化的概率为
P(Y=k|X=xi)=esk∑jesj
其中评分为
s=f(xi,W)
,
esk∑jesj
被称为Softmax函数。
最优化问题即转化为最大化这个概率的对数似然估计,但一般对于损失函数来说是进行最小化,那么就是最小化正确分类概率的负值对数似然估计,即
Li=−logP(Y=yi|X=xi)
综合得出损失函数为:
Li=−log(esyi∑jesj)
举例如下:

课堂问答⑥:该损失函数的最大最小值是多少?
概率取值范围为0~1,那么损失值即
−log()
函数在[0,1]上的取值,所以损失函数最小值为0,最大值为无穷大。
课堂问答⑦:一般情况下我们会将可训练参数值初始化为很小的数值,所有评分基本上约等于0,那么此时的损失是多少?
评分
s
约等于0,则
其中N为类别总数(#classes),可以利用这个结论在训练开始时进行安全检查。
对比
之前介绍的两种损失函数分别应用于多分类支持向量机和Softmax分类器,分别称为合页损失(hinge loss)和交叉熵损失(cross-entropy loss),形式如下:
hinge loss:
Li=∑j≠yimax(0,sj−syi+1)
cross-entropy loss:
Li=−log(esyi∑jesj)
举例说明两个损失函数的计算过程:
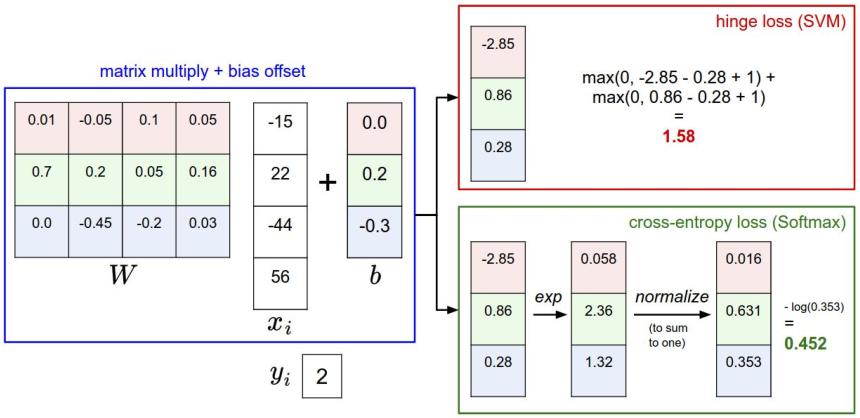
课堂问答⑧:假设有若干组评分如下
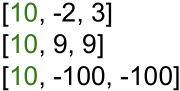
其中第一个类别(绿色)为正确类别,以第三组数据为例,如果稍微改变评分值的话,对于两种损失函数会有什么影响?
第三组中正确类别和其他类别的评分间隔远大于安全间隔,那么稍微改变评分值对于合页损失没有任何影响,损失值不变,但是对于交叉熵损失会有影响,不论评分多么微小的变化,损失值都会改变。
由此可见,合页损失主要涉及类别边界附近的样本,对于评分远低于正确类别评分的样本不予考虑;而交叉熵损失会考虑到所有的样本点。
网页Demo:http://vision.stanford.edu/teaching/cs231n/linear-classify-demo/
3.优化
对于一个数据集,先通过评分函数(score function)计算样本在每个类别上的得分,然后利用损失函数(loss function)来衡量评分的优劣,另外还要考虑加入正则项,优化的任务就是最小化损失函数(+正则项)的值。
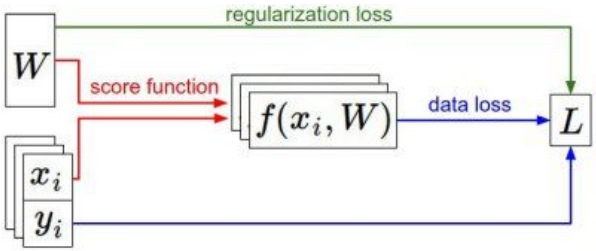
主要介绍三种优化策略:
(1)随机搜索 :-)
(2)计算数值梯度,沿着梯度相反方向进行优化
例,一维时的数值梯度
df(x)dx=limh→0f(x+h)−f(h)h
优点:容易实现。
缺点:求取的是近似值,计算耗时。
(3)利用微积分求取梯度(解析梯度),沿着梯度相反方向进行优化。
优点:求取的是精确值,计算速度快。
缺点:容易出错。
在实际应用中,基本都是使用解析梯度,但是会用数值梯度检查解析梯度的正确性,即梯度检查(gradient check)。
优化的过程可以视作梯度下降(Gradient Descent),即沿着梯度相反方向调节权值参数,伪代码如下
# Vanilla Gradient Descent
while True:
weights_grad = evaluate_gradient(loss_fun, data, weights)
weights += -step_size * weights_grad # parameter update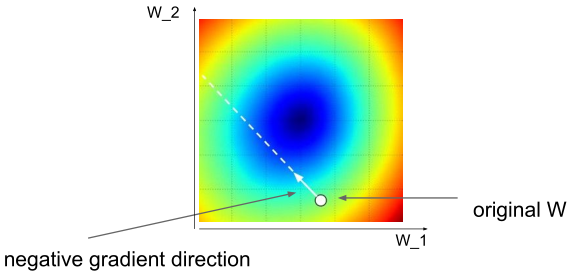
一般不会计算整个数据集中样本的梯度后再进行权值更新,而是选用一组样本,用这组样本的梯度近似整个数据集的梯度对权值进行更新,成为批量梯度下降(Mini-batch Gradient Descent),伪代码如下
# Vanilla Mini-batch Gradient Descent
while True:
data_batch = simple_training_data(data, 256) # sample 256 examples
weights_grad = evaluate_gradient(loss_fun, data_batch, weights)
weights += -step_size * weights_grad # parameter update通常选用的batch size有32、64、128、256等,要考虑到所用GPU的显存情况。
下图展示了利用批量梯度下降进行优化时损失函数的变化过程
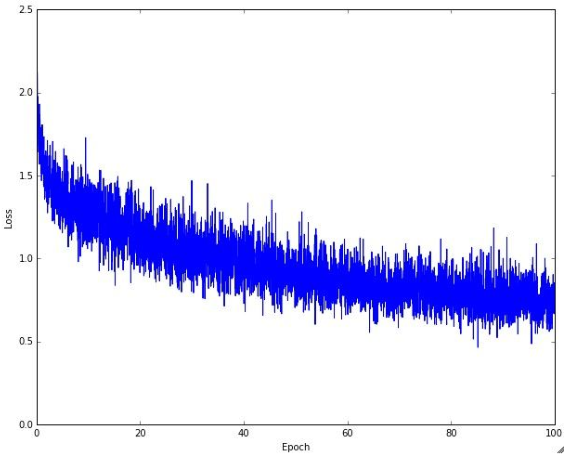
注意,并不是所有的优化过程都是如上图一样的变化趋势。
上述伪代码中的step_size也被称作学习速率(learning rate),是一个很重要的超参数,学习速率的设定对训练过程影响很大,甚至关系到模型是否能收敛。下图展示不同大小的学习速率对损失函数变化趋势的影响。

从图中可以看出,如果学习率选取较大(绿色)损失函数前期快速收敛但过早进入平稳期;选取太大(橙色)损失函数不会收敛甚至爆炸;选取太小(蓝色)则收敛速度过慢;只有选取合适的学习率(红色)则兼顾损失函数下降速度和效果(更小值)。
一般的做法是,在训练初期选取较大的学习率,等收敛至平稳期时减小学习率继续训练,通常减小学习率两次,即经过三个阶段的训练。
除了批量梯度下降,还有其他一些梯度更新算法,如momentum,Adagrad,RMSProp,Adam等。
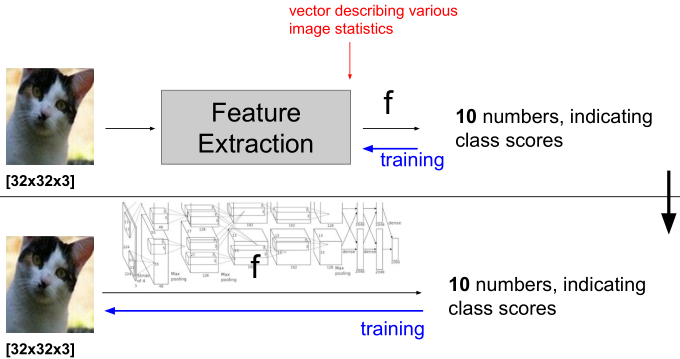
【另】图像特征
之前处理图像问题时,一般是先提取图像特征(人为设计),然后将特征输入到分类器中进行训练,常用的图像特征有:颜色直方图、HoG、SIFT、BoW等。
而利用深度学习处理图像问题时,特征提取的工作交由机器在大规模数据中学习得到。














 574
574











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









