 视觉任务解析
视觉任务解析





1.分类+定位
2.物体检测
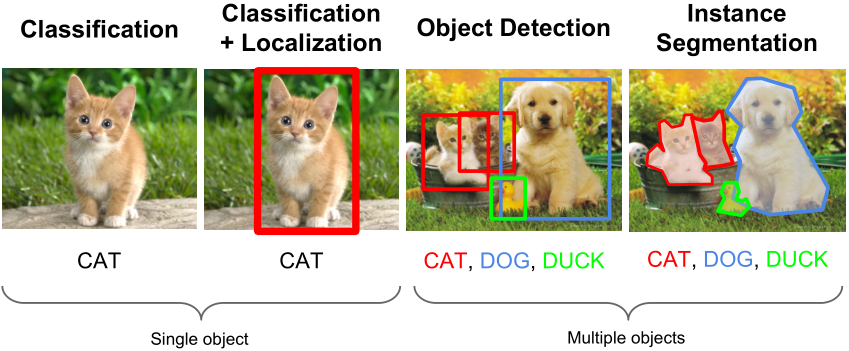
计算机视觉任务一般可分为下列四类:
— 分类
— 分类+定位
— 检测
— 实例分割
1.分类+定位
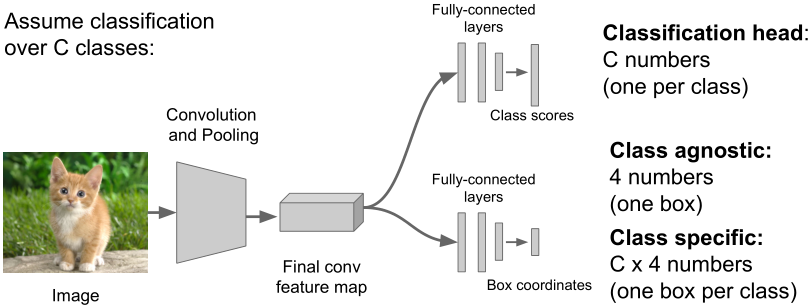
分类:C个类别
输入:图像
输出:类别标签
评价指标:准确率

定位:
输入:图像
输出:边框(x,y,w,h)
评价指标:IoU(Intersection over Union)

分类+定位即同时完成上述两个任务
ImageNet数据集的分类+定位(CLS-LOC)任务:
共1000类(同分类任务一样)
每张图像中有一类物体,并且最少有一个位置边框
每类约有800训练图像
算法每次生成5个预测,包括类别标签及位置边框,即top-5预测
预测正确的条件是,在5个预测中分类正确且位置边框>=0.5 IoU

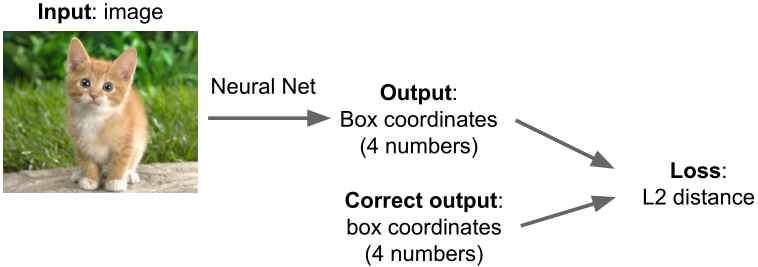
思路#1:将定位视为回归问题
图像经过神经网络后输出位置边框坐标,将其与正确坐标的L2距离作为损失函数。
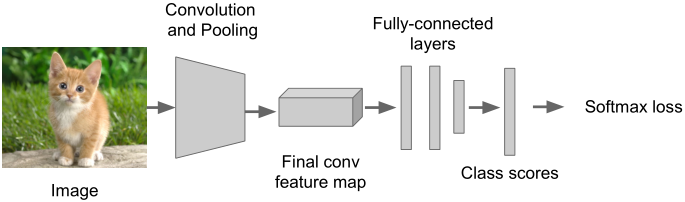
基本流程如下:
Step1:训练一个分类模型(如AlexNet, VGGNet, GoogLeNet等)
Step2:附加一个新的全连接层“regression head”到网络上
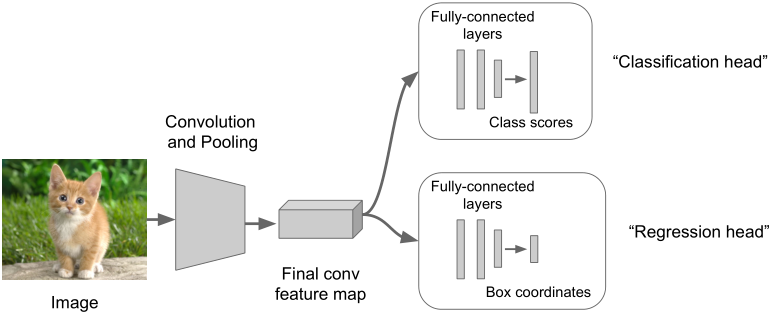
Step3:利用SGD和L2损失单独训练“regression head”
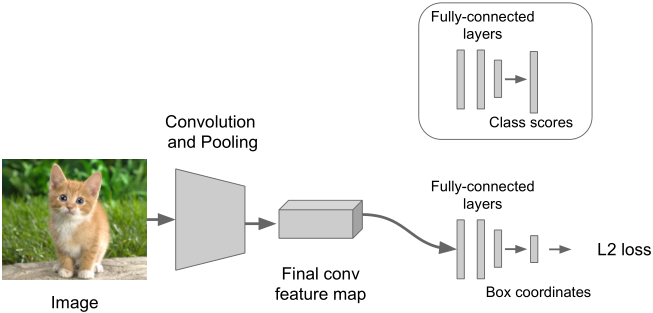
Step4:在测试时同时使用两个全连接层完成两个任务
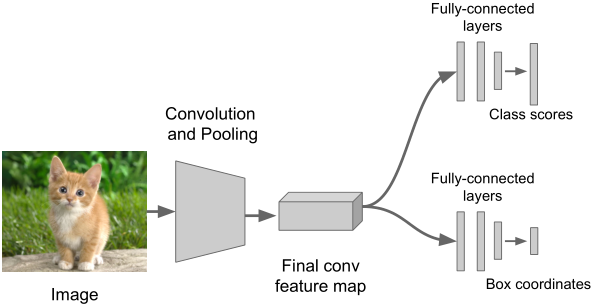
分类后定位 vs. 未分类定位
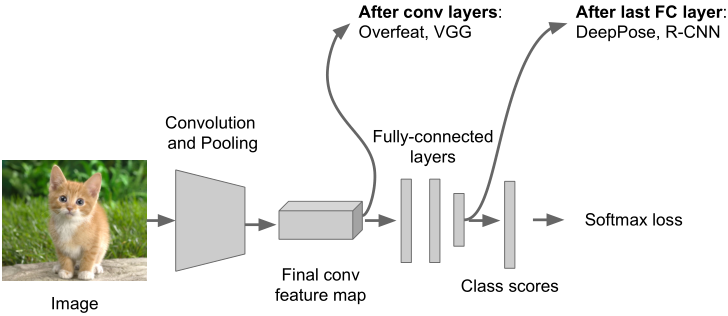
在何处附加“regression head”?
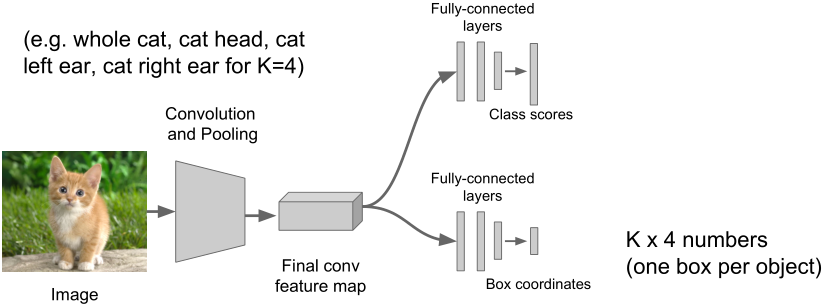
另:定位多个目标,即在每张图像
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 886
886

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









