







在之前呢我们已经把portaudio平台搭好了,可以采集声音信号并播放了。那么接下来呢我们就来做一些实质性的东西——自适应端点检测。那么什么是自适应端点检测呢?也就是采集声音信号的时候,开始说话到说话结束,我们把这一段声音信号采集下来进行处理。不然那么多信号都去处理,没有声音也处理那就浪费了很多的空间以及浪费了CPU去做后续的操作。后面的功夫是省了,但是前面的工作就多了。天下可没有白费的午餐!接下来我就大概说一下我的做法吧。
1、基础
采样频率的设置:我们人耳一般可以听到的频率最高就是16000HZ。根据采样定理,一般采样频率要是这个的两倍才不会发生混叠。所以我们在通话的时候采样频率一般是8Khz,带宽就需要16Khz。这样就基本可以使得通话的体验非常到位,还原度非常高!不是说采样频率越高声音的效果就越好,这是一个trade-off。这一次我们采样就用16Khz,这样其实已经可以把基本的声音采下来。因为人耳对于低频还是更加敏感!现在的高保真就是44.1Khz的采样率。在经过量化(均匀量化和非均匀量化)就可以进行保存。怎么把采集到的信号进行数字化变成非均匀量化比如Mu律。请参考:
http://www.speech.cs.cmu.edu/comp.speech/Section2/Q2.7.html
声音采集时遇到的问题:在进行声音采集的时候有噪声,我们得小减小噪声的影响;以及还有回声。
声音采集的方式:直接对已有的声音(已经录制好的)进行处理;以及现场录制。这样的工具有:Windows recorder,Adobe audition,Linux的arecord。
声音保存的方式:如下图。一般是PCM之后才好做进一步的处理。

声音采集时序考虑的参数:采样频率,量化方式,通道,存储。
声音采集时的两种模式:阻塞(自己设定时间,不管有没有数据都要回来)和回调(有有效的数据的时候才会调用这个函数返回数据),这两种在Portaudio里面都有对应的代码。在这里你大概也想到了我们应该使用的就是回调才能实现我们的功能。
语言处理的模式:Push和Pull。在这里的话,这两个东西正好和阻塞和回调差不多对应。
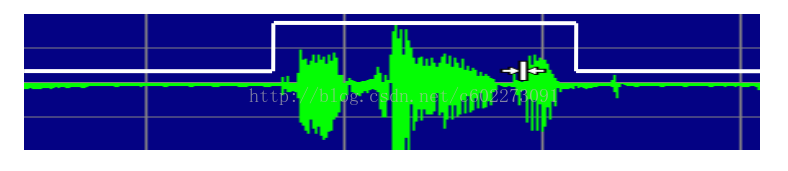
端点检测:实现效果如下图:一般来说人说话是突然说的,然后我们还要判断什么时候结束。
2、算法
具体实现的步骤如下图:
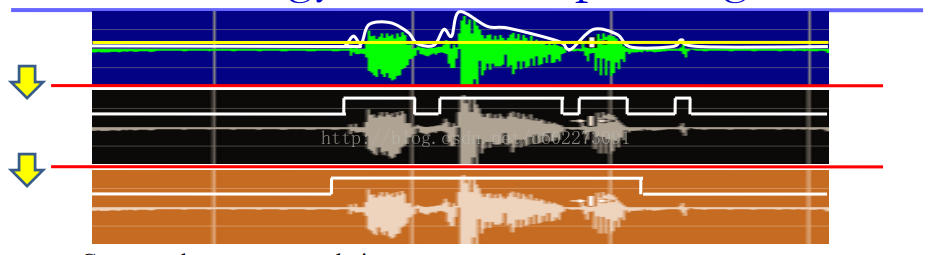
- 判别:计算每个时刻的能量,设定一个阈值k,如果大于它,我们认为是1(1表示该点是语言),否则就是0。能量计算的公式就是:
- 平滑:小于100ms的silien我们认为是语音的部分,大于250ms的语言我们才认为是语言。在截取的语音信号前后多截出250ms。这个的前提是比较安静,如果不安静的话那么就得另当别论,看外界影响有多大。
- 算法一:先来一个比较简单的算法
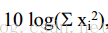

- 算法二:更复杂一些的算法
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章















 188
188











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









