






摘要
本文主要通过向量和计算,讲述GPU并行计算。就任务为简单的相关性弱的计算而言,GPU的并行计算速度远远快于CPU。下面我们就以向量和的GPU并行为例进行展开。
1. 并行计算经典代码
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <iostream>
#define N 100
__global__ void add(int *a, int *b, int *c) {
int tid = blockIdx.x;
if (tid<N) {
c[tid]=a[tid]+b[tid];
}
}
int main(void) {
int a[N], b[N], c[N];
int *dev_a, *dev_b, *dev_c;
// 分配CPU中的dev_abc指针空间
cudaMalloc((void**)&dev_a, N*sizeof(int));
cudaMalloc((void**)&dev_b, N*sizeof(int));
cudaMalloc((void**)&dev_c, N*sizeof(int));
// 设置CPU中的a,b,c数组的初始值
for (int i=0; i<N; i++) {
a[i]=-i;
b[i]=i*i;
}
// 复制CPU计算结果到GPU
cudaMemcpy(dev_a, a, N*sizeof(int), cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, N*sizeof(int), cudaMemcpyHostToDevice);
// GPU并行计算
add<<<N,1>>>(dev_a, dev_b, dev_c);
// 复制GPU计算结果到CPU
cudaMemcpy(c, dev_c, N*sizeof(int), cudaMemcpyDeviceToHost);
// 输出结果
for (int i=0; i<N; i++) {
printf("%d + %d = %d \n", a[i], b[i], c[i]);
}
// 释放内存
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
2. 关于add()函数
__global__ void add(int *a, int *b, int *c) {
int tid = blockIdx.x;
if (tid<N) {
c[tid]=a[tid]+b[tid];
}
}之所以是blockId.x,顾名思义,当然有blockId.y和blockId.z,其目的在于方便GPU处理数学或者三维图像等问题。
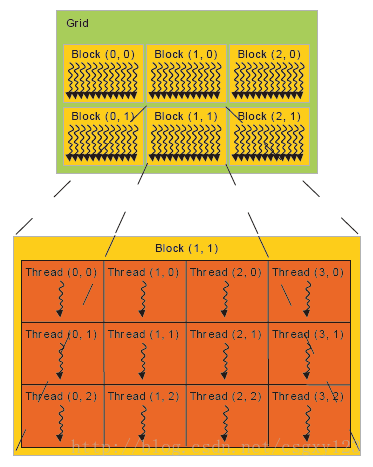
3. 关于核函数<<<>>>参数
核函数的一般参数形式为Kernel<<<Dg, Db>>>(param list); 其中,Dg的单位为(1/blocks),Db的单位为(threads/block)。因此,注意,线程Thread数目=Dg乘以Db.















 3926
3926

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









