







决策树很有用,但是他们并不是最好的分类器.在本节和下节,我们讲述两种计数:boosting和随机森林.它们在内部使用了决策树,所以继承了树的很多有用的性能(能够处理混合数据类型、没有归一化的数据、特征缺失)。这些技术能够获得相当好的性能,因此它们通常是ML库中最好的监督学习的算法。
在监督学习领域,有一个叫统计提升(meta-Learning)的学习算法.Keans想知道可不可能从很多弱分类器中学习到一个强分类器.第一个boosting算法,叫AdaBossting,由Freund和Schapire提出.OpenCV包含了4种类型的boosting:
1.CvBoost::DISCRETE(discrete AdaBoost)
2.CvBoost::REAL(real AdaBoost)
3.CvBoost::LOGIT(LogitBoost)
4.CvBoost::GENTLE(gentle AdaBoost)
它们都是由原始AdaBoost变换而来的.我们发现real AdaBoost和gentle AdaBoost的效果最好.Real AdaBoost利用置信区间预测,在标签数据上有很好的性能.Gentle AdaBoost对外围数据(outlier data)赋较小的值,所以在回归问题上效果很好.LogitBoost也可以很好的处理回归问题.只需要设置以下标志参数,就可以使用不同的AdaBoost算法,所以在处理实际问题的时候,可以尝试所有的算法,然后挑选最好的那个.下面我们讨论原始的AdaBoost算法.注意,OpenCV执行的boosting算法,是一个两类分类器(不像决策树和随机森林).还有LogitBoost和GentleBoost不仅可以用来解决两类分类,还可以用于回归问题.
AdaBoost
boosting算法训练了T个弱分类器ht,t∈{1,....,T}.这些弱分类器很简单.大多说情况下,它们只是包含一次分裂(称为决策stumps)或仅有几次分裂(可能到3次)的决策树.最后做决定的时候将复制权重αt给每个分类器.AdaBoost训练时输入的特征向量是xi,向量的类别标签是yi(这儿i=1,...,M,M是样本总数),且yi∈{1,-1}.首先,我们初始化数据样本的权值Di(i)来告诉分类器
将一个数据点分类错误的代价是多少.boosting算法的主要特征是,在训练过程之中,这个代价将会更新,使得后来的弱分类器更加关注与前面的分类器没有分对的数据点.算法如下.
1.D1(i) = 1/m , i=1,...,m
2.针对t=1,..,T:


注意,在2b步,如果找不到小于20%错误率的分类器,则停止,表明可能需要更好的特征.
当前面讲的训练算法结束之后,最后的强分类器接受输入向量x,使用所有弱分类器的加权和来进行分类.
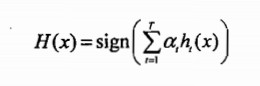
这里,符号函数把所有正数变为1,把所有的负数变为-1(0仍然为0).
boosting代码
.../opencv/samples/c/letter_recog.cpp展示了怎么使用boosting,随机森林和反向传播网络(即多层传感网络,MLP).boosting的代码与决策树的代码相似,但是除了决策树的参数,它还拥有自己的控制参数.

在CvBoostParams中,boost_type从前面列出的四个算法中作出选择.
split_ctrteria为下面的值之一:
CvBoost::DEFAULT(默认配置)
CvBoost::GINI(real AdaBoost的默认配置)
CvBoost::MISCLASS(discrete AdaBoost的默认配置)
CvBoost::MISCLASS(discrete AdaBoost的默认配置)
CvBoost::SQERR(最小平方误差:只能在LogitBoost和gentle AdaBoost时使用)
最后一个参数weight_trim_rate用于保存计算结果.当训练进行时,很多数据点变得不重要.也就是说,第i个点的权值Dt(i)变得很小.weight_trim_rate是一个0到1(包含)的阈值,在给定的boosting迭代中暗中丢弃一些数据点.例如:weight_trim_rate是0.95.这意味这样本总权值小于1.0-0.95 = 0.05的点将不参加训练的下一次迭代.这些点兵不是永久删除.当下一个弱分类器训练结束,所有的点的权值将被重新计算,有些前面被丢弃的样本可能进入下一个训练集合.关闭这个功能,只需要将weight_trim_rate置为0即可.
我们观察到CvBoostPrams{}是继承于CvDTreeParams{}是继承于CvDTreeParams{},所以可以设置其他与决策树有关的参数.实际情况下,如果处理的特征有丢失,可以设置CvDTreeParams::use_surrogates,它可以保证每次分裂选取的特征将被存储在相应的节点中.另一个重要的参数是使用proirs来设置将非物体任务是物体的代价.再说一次,如果我们训练有毒和五毒的蘑菇,我们可以设置prior是为float priors = {1.0,10.0};如此一来,把有毒蘑菇标记为无毒的错误代价则比把无毒蘑菇标记为有毒的代价大10倍.
CvBoost类包含成员变量weak,他是一个CvSeq*类型的指针,指向继承于CvDtree决策树的弱分类器.LogitBoost和GentleBoost中,决策树是回归树,其他的boosting算法中决策树则只判断类别0和类别1.CvBooatTree的声明如下:

boosting算法的训练和决策树的训练几乎一样.不同的是多了一个外部参数update,它的默认值为0.这样,我们重新训练所有的弱分类器.如果update设置为1,我们就把新训练出的弱分类器加到已经存在的弱分类器集合中.训练boost分类器的函数原型如下:

../opencv/samples/c/letter_recog.cpp中有一个训练boosting分类器的例子.训练部分的代码片段如下.


在预测中,我们传入一个特征向量sample,predict()函数返回一个预测值.
当然,有一些可选参数.第一个参数是missing,与决策树相同,他包含一个与sample向量维度相同的字节类型向量,非0标志着特征的丢失.(注意这个标识只有在训练分类器时使用了CvDTreeParams::use_surrogates的前提下才有效)
如果想得到每个弱分类器的输出,可以传出一个浮点型的CvMat向量weak_response,它的长度和弱分类器的个数一样.如果向量weak_response被传入,预测函数将根据每个分类器的输出填充这个向量
CvMat* weak_responses = cvCreateMat(
1,
boostedClassifier.get_weak_predictors()->total,
CV_32F
);
预测函数的下一个参数slice指定使用弱分类器的哪个相邻子集,它可以这样设置:
inline CvSlice cvSlice(int start , int end);
但是我们通常使用默认值,把slice设置为"所有弱分类器"(CvSlice slice = CV_WHOLE_SEQ).最后,我们看raw_mose,它的默认值为False,但是可以设置为true.这个参数的用法与决策树完全一样,标志着数据是否已经归一化.正常情况下,我们不实用这个参数.调用boost预测的例子如下:boost.predict(temp_sample,0,weak_response);
最后,一些辅助函数可以使用.我们可以使用void CvBoost::prune(CvSlice slice)来从模型中去除一个弱分类器.
我们也可以使用 CvSeq* CvBoost::Get_weak_predictor()来获取所有的弱分类器.这个函数返回一个类型为CvSeq* 的指针序列,序列中元素为CvBoostTree类型.














 1357
1357











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









