






《Understanding of Internal Clustering Validation Measures》
发表在2010IEEE International Conference on Data Mining
应该译为“内部聚类效果测量的一些理解”,我译成了大白话,也没错,这篇文章讲的就是如何评价你聚类好坏的。
原文下载:http://pan.baidu.com/s/1jHDvyq6
下面译文开始:
#----------------------------------------------------------------分割线----------------------------------------------------------------#
摘要
众所周知,聚类效果的好坏直接会影响要聚类的效果。大体上,聚类的效果的好坏会又两类指标衡量,一类是外部聚类效果,一类是内部聚类效果。在这篇论文中,我们只探讨内部聚类效果(具体什么是内部聚类效果,为什么用内部聚类效果进行评价看下一节),并给详细的给出了11中评价聚类效果好坏的评价算法,这11种算法应用在5中聚类环境中以展现出他们到底谁更适应“恶劣多变”的聚类环境。
1.介绍
聚类是一种非常重要的非监督学习技术,他的任务是将目标样本分成若干个簇(cluster),并且保证每个簇之间样本尽量的接近,并且不同簇的样本间距离尽量的远。聚类技术被广泛使用在图像处理和生物信息学。作为一个非监督学习任务,评价聚类后的效果是非常有必要的,否则聚类的结果将很难被应用。
聚类的评价方式在大方向上被分成两类,一种是分析外部信息,另一种是分析内部信息。外部信息就是能看得见的直观信息,这里指的是聚类结束后的类别号。虽然是个办法,但是这种办法没法应用(举个例子,如果要进行文本聚类,最后聚出了几个类,聚类是否正确可以肉眼分析文章内容来判断这几个样本是不是一个类,要是1w篇文章还能这么做吗?干脆人干吧,还要计算机干嘛)。还有一种分析内部信息的办法,大致意思就是聚完类后会通过一些模型生成这个类聚的怎么样的参数,诸如熵和纯度这种数学评价指标。
不想外部信息进行评价,内部信息评价是不需要肉眼识别聚类好坏的,也就是说根本就不用知道聚类后的标签是什么,只需要看个指数就行了。并且有很多时候,聚类后的标签你是看不到,这样就只能用内部信息来评价聚类的好坏了。
在文章中,有很多已经被提出的聚类算法好坏评价算法,诸如CH,I,DB,SD,S_Dbw等等,然而这些算法可能会受数据的“异常”而产生对结果的影响,诸如数据中的噪声等。我们提出了五类可能会预测精度的数据异常情况:单调性、噪声、密度、subcluster(没翻译过来,大致意思是有几个簇离的很近,有几个簇离得很远)、倾斜分散(有些样本少密度大,有些样本多密度小)。每种情况都会用这11种评价算法测试一下,最终发现,S_Dbw算法完爆其他算法。
2.簇的内部信息评价
在这一节我会介绍有关簇的内部信息的基本概念以及11中评价聚类好坏的算法。
我们为了能让簇内样本距离尽量的近,簇与簇之间的样本尽量的远,我们需要用以下两种指标来评价。
2.1紧凑度
紧凑度是衡量一个簇内样本点之间的是否足够紧凑的,比如到簇中心的平均距离啊,方差啊什么的。
2.2分离度
分离度是衡量该样本是否到其他簇的距离是否足够的远,这里边讲个很多,那11种算法的精髓也是在计算分离度,这里我就不赘述了,原本也只是将个大致意思而已,毕竟那些算法并不是作者写的。这里说说最NB的S_Dbw算法:这种算法是通过一种密度衡量公式来评价分离的好坏的。大致思路是,从所有的簇中心中至少有一个密度值要大于midpoint的密度值(这个没太懂),然后通过SD算法的紧凑度算法搞出一个权重值判断聚类的好坏(具体也没时间深究了,好用就行啊)
2.3对簇内部信息评价的理解
作者自己搞了点二维数据集,并用K-means做聚类来评价聚类的好坏,其中K-means算法用的是CLUTO的库(作者也是挺懒啊,谁知道这库里用了啥优化算法,反正sklearn里的kmeans用的是kmeans++还有多线程啥子的,实测nb的很啊)
2.3.1单调性的影响
没太明白这个“单调性”是啥意思,反正样本是这个样子的(我猜是一种近乎于完美的样本):

实验结果如下图:
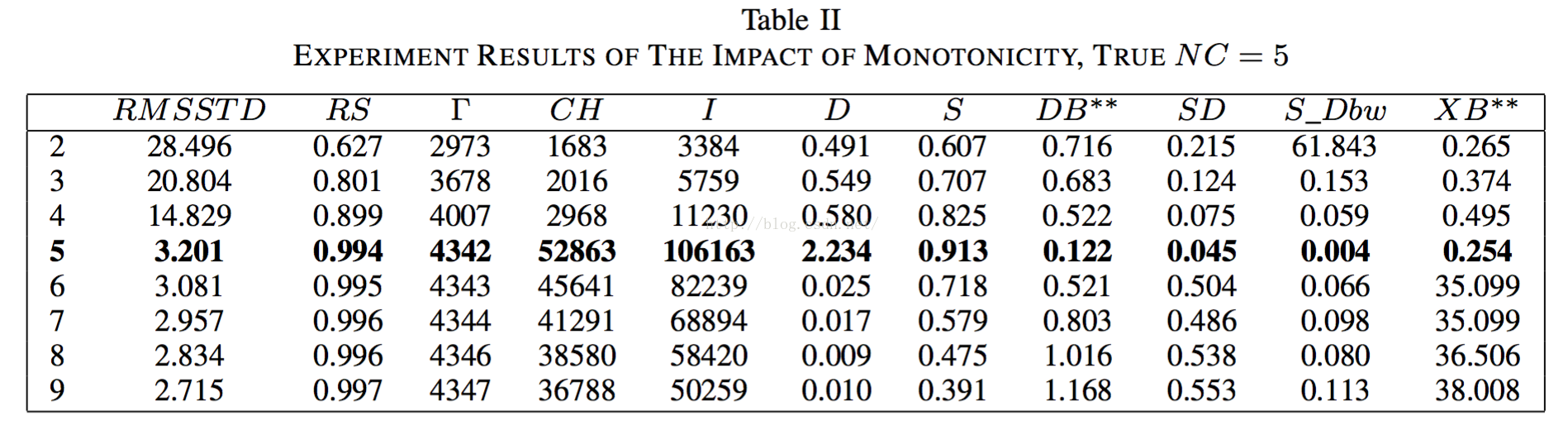
可以看到大家的结果都不错,这是最理想的情况,所以分不出谁好谁坏。
2.3.2噪声的影响
不多说了直接上数据图和结果图:
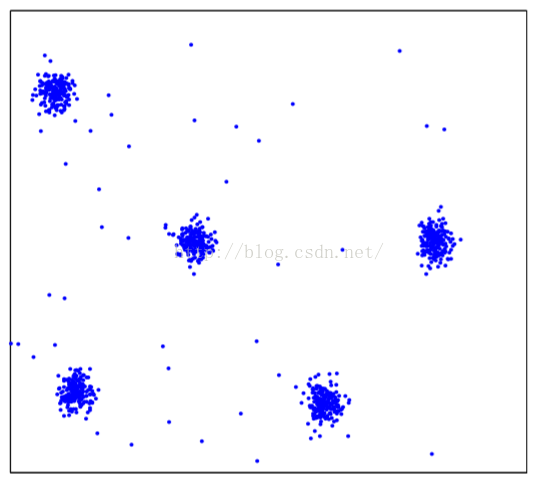
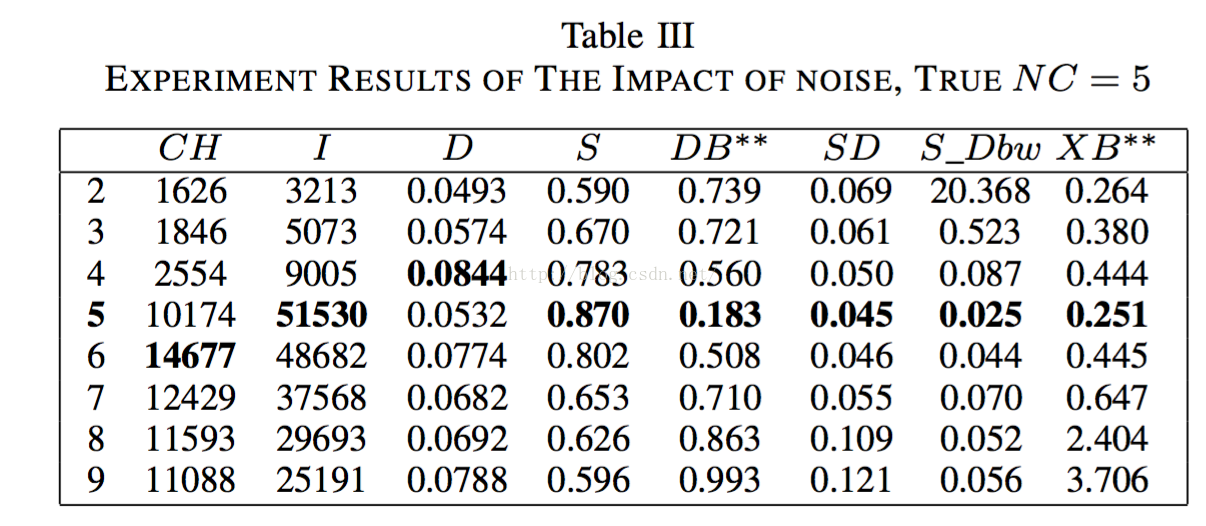
有几个算法已经遭不住了
2.3.3样本密度差异的影响
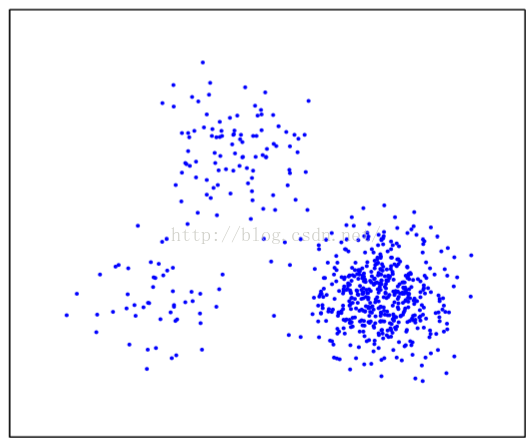
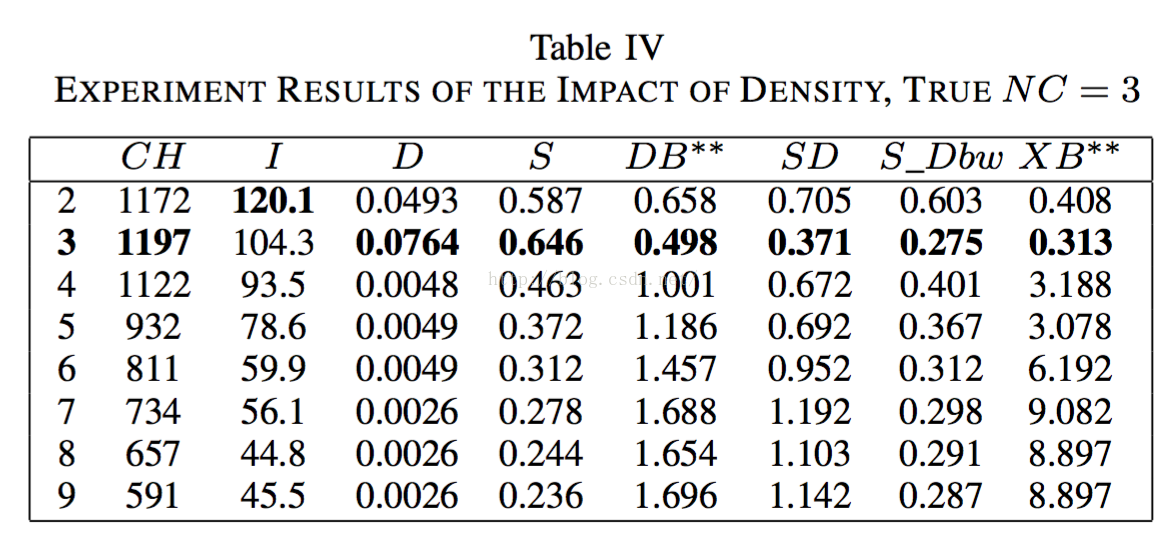
2.3.4subcluster的影响
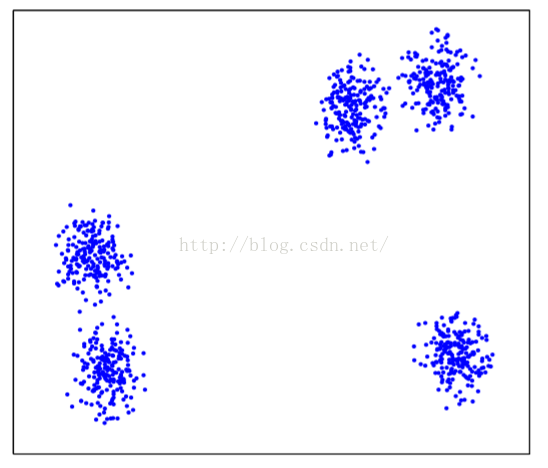
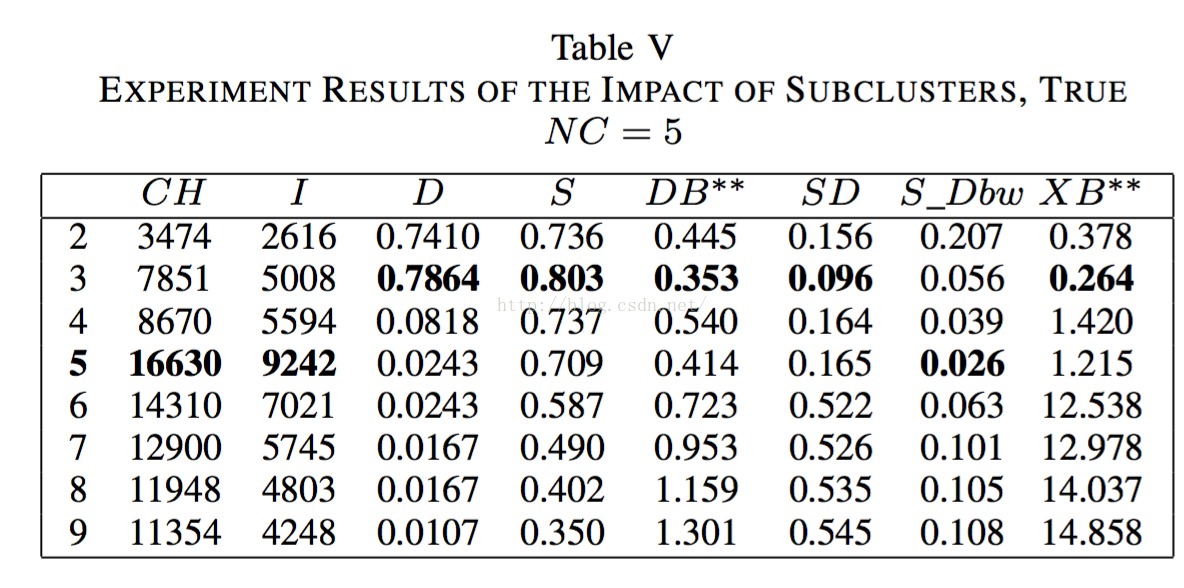
2.3.5倾斜分散的影响
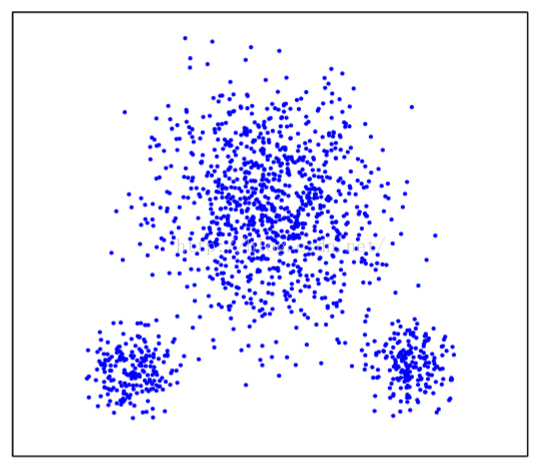
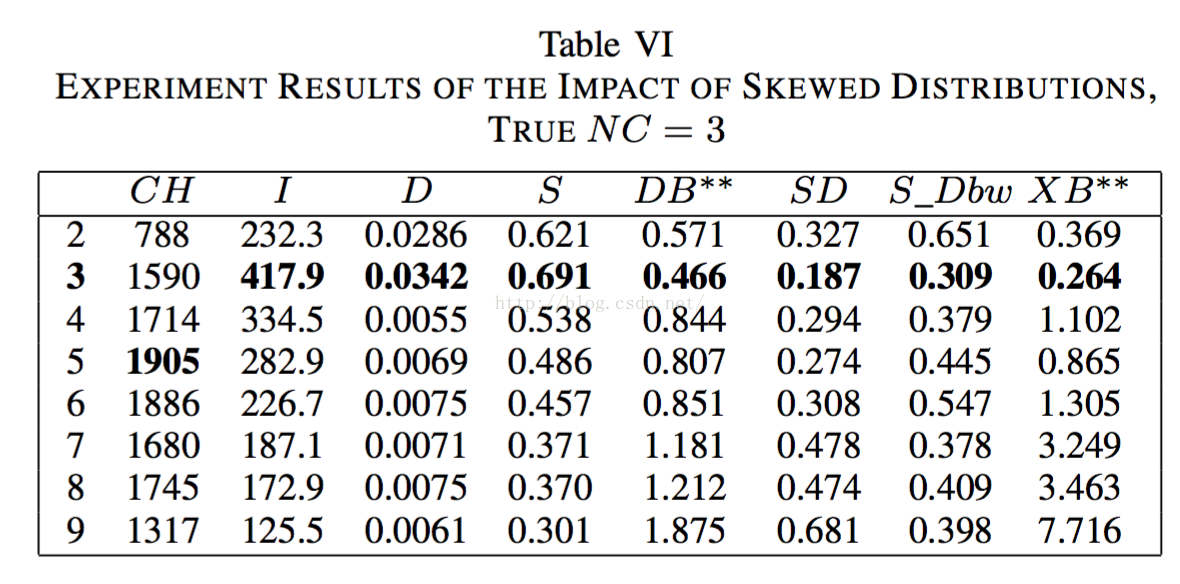
看了这些结果图不用多说,S_Dbw算法实在太nb了,都不会有失误,但是这是个二维的聚类,所文本聚类怎么也得上百维起,实际效果咋样不得而知。
另外!聚类算法也会有影响,但是这篇文章要比较评价聚类效果算法好坏的讨论,因此制作了简单的对比,如下图:
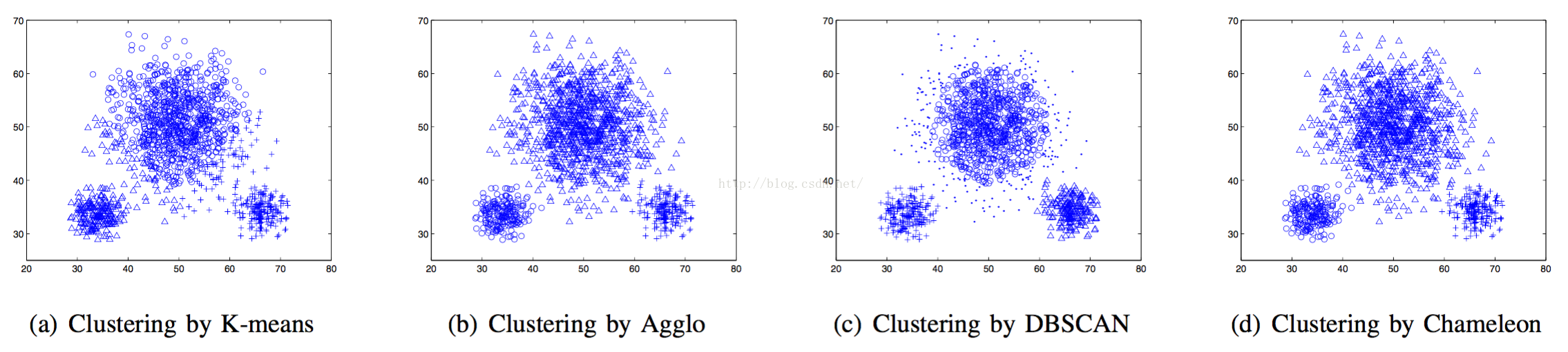
学校学的kmeans和dbscan效果实在不咋地。。。
剩下俩是何方神圣,我得好好搞搞














 4144
4144











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









