







一、 案例简述
本案例讲述使用OpenCL计算矩阵乘法:C = A * B 。
设A、B、C分别是大小为N*P、P*M和N*M的矩阵,那么顺序实现的C代码可以如下所示:
// C Function
void mat_mul(
int Ndim, int Mdim, int Pdim,
float* A, float* B, float* C)
{
int i, j, k;
float tmp;
for (i = 0; i < Ndim; i++) {
for (j = 0; j < Mdim; j++) {
tmp = 0.0;
for (k = 0; k < Pdim; k++)
tmp += A[i*Pdim + k] * B[k*Mdim + j];
C[i*Mdim + j] = tmp;
}
}
}二、 OpenCL实现矩阵乘法
1. 内核函数实现
// OpenCL Kernel Function
__kernel void HelloOpenCL(
const int Ndim,
const int Mdim,
const int Pdim,
__global const float* A,
__global const float* B,
__global float* C)
{
int i = get_global_id(0);
int j = get_global_id(1);
int k;
float tmp;
if ((i < Ndim) && (j < Mdim)) {
tmp = 0.0;
for (k = 0; k < Pdim; k++)
tmp += A[i*Pdim + k] * B[k*Mdim + j];
C[i*Mdim + j] = tmp;
}
}2. 宿主机代码实现
下面是在《基于CUDA的OpenCL开发环境搭建与入门程序示例》中main.cpp宿主机代码为基础的补丁文件。测量运行时间的部分:首先,在clCreateCommandQueue()函数中设置CL_QUEUE_PROFILING_ENABLE标志;然后,在clEnqueueNDRangeKernel()函数中设置事件对象;最后,通过clGetEventProfilingInfo()函数获取命令入队时间和命令执行结束时间。注意:时间的单位是纳秒,在最后打印时转换为秒显示。
--- /root/Desktop/main.cpp
+++ /root/Desktop/main_new.cpp
@@ -143,8 +143,10 @@
}
// 4. Choose the first device
- commandQueue = clCreateCommandQueue(context,
- devices[0], 0, NULL);
+ commandQueue = clCreateCommandQueue(context,
+ devices[0],
+ CL_QUEUE_PROFILING_ENABLE,
+ NULL);
if (commandQueue == NULL) {
perror("Failed to create commandQueue for device 0.");
exit(1);
@@ -183,14 +185,33 @@
/******** 第四部分 创建内核和内存对象 ********/
- #define ARRAY_SIZE 10
+ const int Ndim = 3;
+ const int Mdim = 4;
+ const int Pdim = 5;
+
+ int szA = Ndim * Pdim;
+ int szB = Pdim * Mdim;
+ int szC = Ndim * Mdim;
cl_kernel kernel = 0;
cl_mem memObjects[3] = {0, 0, 0};
- float a[ARRAY_SIZE];
- float b[ARRAY_SIZE];
- float result[ARRAY_SIZE];
+ float *A;
+ float *B;
+ float *C;
+
+ A = (float *)malloc(szA * sizeof(float));
+ B = (float *)malloc(szB * sizeof(float));
+ C = (float *)malloc(szC * sizeof(float));
+
+ int i, j;
+
+ for (i = 0; i < szA; i++)
+ A[i] = i + 1;
+
+ for (i = 0; i < szB; i++)
+ B[i] = i + 1;
+
// 8. Create the kernel
kernel = clCreateKernel(program, "HelloOpenCL", NULL);
@@ -200,23 +221,18 @@
}
// 9. Create memory objects
- for (int i = 0; i < ARRAY_SIZE; i++) {
- a[i] = (float)i + 1;
- b[i] = (float)i + 1;
- }
-
memObjects[0] = clCreateBuffer(context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR,
- sizeof(float) * ARRAY_SIZE,
- a, NULL);
+ sizeof(float) * szA,
+ A, NULL);
memObjects[1] = clCreateBuffer(context, CL_MEM_READ_ONLY |
CL_MEM_COPY_HOST_PTR,
- sizeof(float) * ARRAY_SIZE,
- b, NULL);
+ sizeof(float) * szB,
+ B, NULL);
memObjects[2] = clCreateBuffer(context, CL_MEM_READ_WRITE |
CL_MEM_COPY_HOST_PTR,
- sizeof(float) * ARRAY_SIZE,
- result, NULL);
+ sizeof(float) * szC,
+ C, NULL);
if (memObjects[0] == NULL || memObjects[1] == NULL ||
memObjects[2] == NULL) {
perror("Error in clCreateBuffer.\n");
@@ -225,48 +241,98 @@
/******** 第五部分 执行内核 ********/
- size_t globalWorkSize[1] = { ARRAY_SIZE };
- size_t localWorkSize[1] = { 1 };
// 10. Set the kernel arguments
- errNum = clSetKernelArg(kernel, 0, sizeof(cl_mem), &memObjects[0]);
- errNum |= clSetKernelArg(kernel, 1, sizeof(cl_mem), &memObjects[1]);
- errNum |= clSetKernelArg(kernel, 2, sizeof(cl_mem), &memObjects[2]);
+ errNum = clSetKernelArg(kernel, 0, sizeof(int), &Ndim);
+ errNum |= clSetKernelArg(kernel, 1, sizeof(int), &Mdim);
+ errNum |= clSetKernelArg(kernel, 2, sizeof(int), &Pdim);
+ errNum |= clSetKernelArg(kernel, 3, sizeof(cl_mem), &memObjects[0]);
+ errNum |= clSetKernelArg(kernel, 4, sizeof(cl_mem), &memObjects[1]);
+ errNum |= clSetKernelArg(kernel, 5, sizeof(cl_mem), &memObjects[2]);
if (errNum != CL_SUCCESS) {
perror("Error in clSetKernelArg.\n");
exit(1);
}
// 11. Queue the kernel up for execution across the array
- errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL,
- globalWorkSize, localWorkSize,
- 0, NULL, NULL);
+ size_t global[2];
+ cl_event prof_event;
+ cl_ulong ev_start_time = (cl_ulong)0;
+ cl_ulong ev_end_time = (cl_ulong)0;
+ double rum_time;
+
+ global[0] = (size_t)Ndim;
+ global[1] = (size_t)Mdim;
+
+ errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
+ global, NULL, 0, NULL, &prof_event);
if (errNum != CL_SUCCESS) {
perror("Error in clEnqueueNDRangeKernel.\n");
exit(1);
}
+ clFinish(commandQueue);
+ errNum = clWaitForEvents(1, &prof_event);
+ if (errNum != CL_SUCCESS) {
+ perror("Error in clWaitForEvents.\n");
+ exit(1);
+ }
+
+ errNum = clGetEventProfilingInfo(prof_event,
+ CL_PROFILING_COMMAND_QUEUED,
+ sizeof(cl_ulong),
+ &ev_start_time,
+ NULL);
+
+ errNum |= clGetEventProfilingInfo(prof_event,
+ CL_PROFILING_COMMAND_END,
+ sizeof(cl_ulong),
+ &ev_end_time,
+ NULL);
+
+ if (errNum != CL_SUCCESS) {
+ perror("Error in clGetEventProfilingInfo.\n");
+ while(1);
+ exit(1);
+ }
+
// 12. Read the output buffer back to the Host
errNum = clEnqueueReadBuffer(commandQueue, memObjects[2],
CL_TRUE, 0,
- ARRAY_SIZE * sizeof(float), result,
+ sizeof(float) * szC, C,
0, NULL, NULL);
if (errNum != CL_SUCCESS) {
perror("Error in clEnqueueReadBuffer.\n");
exit(1);
}
+ rum_time = (double)(ev_end_time - ev_start_time);
+
/******** 第六部分 测试结果 ********/
- printf("\nTest: a * b = c\n\n");
-
- printf("Input numbers:\n");
- for (int i = 0; i < ARRAY_SIZE; i++)
- printf("a[%d] = %f, b[%d] = %f\n", i, a[i], i, b[i]);
-
- printf("\nOutput numbers:\n");
- for (int i = 0; i < ARRAY_SIZE; i++)
- printf("a[%d] * b[%d] = %f\n", i, i, result[i]);
+
+ printf("\nArray A:\n");
+ for (i = 0; i < Ndim; i++) {
+ for (j = 0; j < Pdim; j++)
+ printf("%.3f\t", A[i*Pdim + j]);
+ printf("\n");
+ }
+
+ printf("\nArray B:\n");
+ for (i = 0; i < Pdim; i++) {
+ for (j = 0; j < Mdim; j++)
+ printf("%.3f\t", B[i*Mdim + j]);
+ printf("\n");
+ }
+
+ printf("\nArray C:\n");
+ for (i = 0; i < Ndim; i++) {
+ for (j = 0; j < Mdim; j++)
+ printf("%.3f\t", C[i*Mdim + j]);
+ printf("\n");
+ }
+
+ printf("\n\nRunning Time: %f s\n", rum_time*1.0e-9);
while(1);
3. 运行结果
(1). N = 3,M = 4,P = 5。
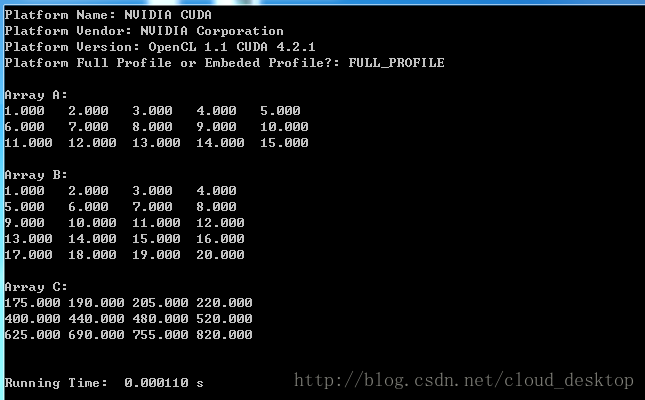
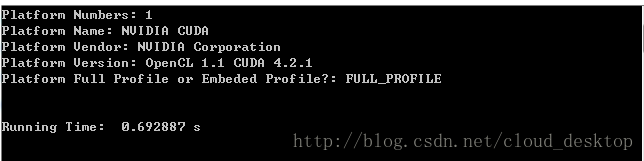
(2). N = 1000,M = 1000,P = 1000。
三、 代码优化 <工作项分组和减少数据移动>
矩阵乘法的核心是一个乘加计算。大多数处理器中的ALU都有足够的带宽,可以保证这个计算可以接近峰值性能运行,不过只有隐藏数据移动时的开销时才能做到这一点。因此,优化矩阵运算的根本就是尽量减少数据移动。上面的代码中的矩阵乘法内核,三个矩阵都保留在全局内存中。这意味着每次乘法都要通过内存层次结构反复地传递行和列(全局内存到私有内存)。
1. 第一次优化
在此优化版本中,每个工作项计算矩阵中的一行。NDRange从一个2D range(分区)集(匹配矩阵C的维度)变为一个1D range(分区)集(匹配矩阵C的行数)。如下内核代码中,每个工作项管理C中一整行的更新,不过在完成这个更新之前,要把矩阵A中相关的行从全局内存复制到私有内存。注:优化代码以(N = 1000,M = 1000,P = 1000)为例。
// OpenCL Kernel Function
__kernel void HelloOpenCL(
const int Ndim,
const int Mdim,
const int Pdim,
__global const float* A,
__global const float* B,
__global float* C)
{
int i = get_global_id(0);
//int j = get_global_id(1);
int j, k;
float tmp;
float Awrk[1000];
if (i < Ndim) {
for (k = 0; k < Pdim; k++)
Awrk[k] = A[i*Pdim + k];
for (j = 0; j < Mdim; j++) {
tmp = 0.0;
for (k = 0; k < Pdim; k++)
tmp += Awrk[k] * B[k*Mdim + j];
C[i*Mdim + j] = tmp;
}
}
}errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL,
global, NULL, 0, NULL, &prof_event);最终运行结果: 0.295128 秒,是上面代码中0.692887秒的42.6% !
本次优化通过增加内核工作量,减少数据移动来提高运行速度。其实如果是在GPU中而不是CPU中,单独使用上述方式增加内核工作量,运行时间反而变为原来几倍。
2. 第二次优化
首先获取平台上的设备数及其最大计算单元数,使用以下代码。
//OpenCL设备信息
cl_uint numDevices;
cl_device_id deviceIds[1];
size_t maxComputeUnits;
errNum = clGetDeviceIDs (platformIds[0],
CL_DEVICE_TYPE_GPU,
0, NULL, &numDevices);
if ((errNum != CL_SUCCESS) || (numDevices < 1)) {
perror("Error in clGetDeviceIDs or no GPU deivce.");
exit(1);
}
errNum = clGetDeviceIDs (platformIds[0],
CL_DEVICE_TYPE_GPU,
1, &deviceIds[0], NULL);
if ((errNum != CL_SUCCESS) || (numDevices < 1)) {
perror("Error in clGetDeviceIDs.");
exit(1);
}
errNum = clGetDeviceInfo(deviceIds[0],
CL_DEVICE_MAX_COMPUTE_UNITS,
sizeof(cl_uint),
&maxComputeUnits,
NULL);
printf("numDevices = %d, maxComputeUnits = %d\n", numDevices, maxComputeUnits);size_t global[1];
size_t local[1];
global[0] = (size_t)Ndim;
local[0] = (size_t)250;
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL,
global, local, 0, NULL, &prof_event);
4. 附录:关于二维数据的工作组分组
在宿主机代码中,根据clGetDeviceInfo()函数查找CL_DEVICE_MAX_WORK_GROUP_SIZE标志所对应工作组内最多元素个数,在我的电脑上,为1024。工作组的大小通常是64的倍数,最好不超过256。localx,localy也有要求,根据我的试验,必须是4的倍数。
size_t local[2];
local[0] = 8;
local[1] = 128;
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL, global, local, 0, NULL, &prof_event); global[0] = (nWidth + local[0] - 1) / local[0];
global[1] = (nHeight + local[1] - 1) / local[1];
global[0] *= local[0];
global[1] *= local[1]; if((x < nWidth) && (y < nHeight))
{
...
}














 1999
1999











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









