







 本文深入探讨了如何通过OpenCL优化矩阵相乘,利用局部内存(local memory)减少全局内存访问,从而提升计算效率。文章详细分析了工作项(work-item)、工作群组(work-group)的概念,以及如何设置合适的局部工作尺寸。通过引入局部内存,作者展示了如何将矩阵相乘的计算方式从行*列转换为多行和多列相乘,提高并行计算性能。然而,实验结果显示,尽管局部内存优化减少了内存访问次数,但在某些情况下,性能提升并不显著,可能受到硬件限制的影响。
本文深入探讨了如何通过OpenCL优化矩阵相乘,利用局部内存(local memory)减少全局内存访问,从而提升计算效率。文章详细分析了工作项(work-item)、工作群组(work-group)的概念,以及如何设置合适的局部工作尺寸。通过引入局部内存,作者展示了如何将矩阵相乘的计算方式从行*列转换为多行和多列相乘,提高并行计算性能。然而,实验结果显示,尽管局部内存优化减少了内存访问次数,但在某些情况下,性能提升并不显著,可能受到硬件限制的影响。
前言
上一篇文章,分析了简单的矩阵相乘在opencl里面的优化kernel代码,每个work-item只负责计算结果矩阵的一个元素。下一步准备每次计算出结果矩阵的块元素,看看计算时间是如何。
这个矩阵系列参考国外一个大神的教程:
https://cnugteren.github.io/tutorial/pages/page4.html
有每个kernel的详解工程,还有github代码工程。
具体分析
这里引入opencl内存的概念:
比较常见的有:
全局内存 __global 修饰符,通常修饰指向一个数据类型的地址,
本地内存 __local 修饰符。local 定义的变量在一个work-group中是共享的,也就是说一个work-group中的所有work-item都可以通过本地内存来进行通信,
私有内存,private 每个work-item里的内部变量
常量内存, constant
下面是opencl的内存模型:
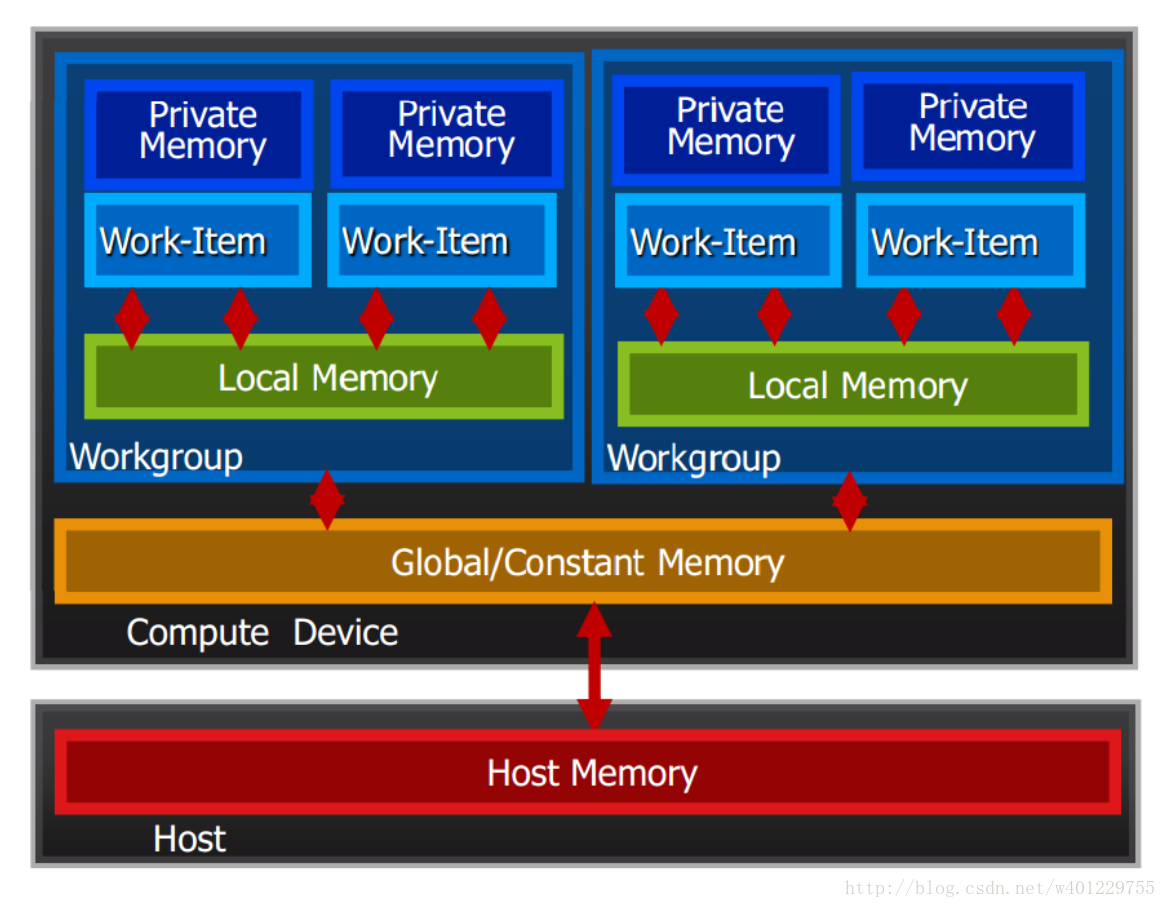
我们分析一下之前的矩阵相乘的一些性能:
__kernel void hello_kernel(__global const int *a,
__global const int *b,
__global int *result_matrix,int result_matrix_row,
int result_matrix_col,int compute_size)
{
int row = get_global_id(0);
int col = get_global_id(1);
int sum = 0;
for(int i=0;i<compute_size;i++)
{
sum += a[row*compute_size+i] * b[i*result_matrix_col+col];
}
result_matrix[row*result_matrix_col+col] = sum;
}首先在运行时总共有M*N个work-item同时执行,每个work-item中执行一个size为k(computesize)的for循环,循环里面每次分别load 数组a和b中的一个元素,所以综合起来一个kernel会有 M*N*K*2 个加载global内存的操作,乘以2是因为a,b两个数组。
其次每个work-item计算出结果矩阵的一个元素并保存,所以有M*N个对global内存的 store 的操作。
由上图的内存模型可知这种访问并不是最优的,再同一个work-group中我们可以定义local内存,来减少这种操作。
下面摘自国外博客的配图说明一下这次优化的原理:
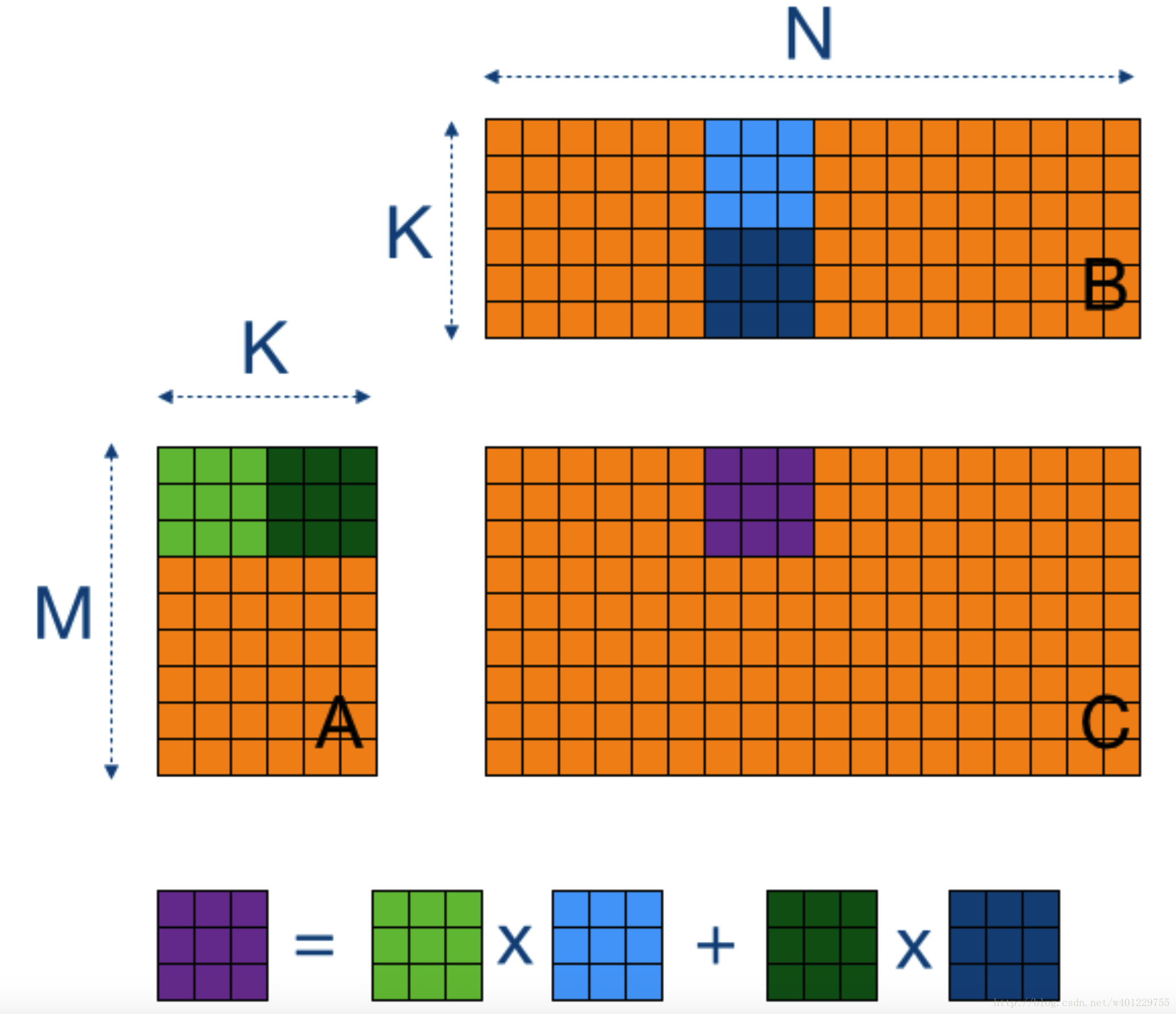
其实就是把之前row*col的方式变成了 多个row和col相乘,究其本质还是对应元素相乘再相加。
这边的中心思想是引入work-group分块计算再相加,work-item的大小还是没变为M*N,不同的是在同一个work-group中把global数组A和B的对应值保存在local内存中,之后每个work-item在这个group中访问这个local变量速度会相对访问global较快,后面的大小为k的循环访问的也是local内存,所以在这个点上是被优化了。先看一下代码实现:
__kernel void hello_kernel(const __global int* A,
const __global int* B,
__global int* C, int M, int N, int K) {
// Thread identifiers
const int row = get_local_id(0); // Local row ID (max: TS)
const int col = get_local_id(1); // Local col ID (max: TS)
const int globalRow = TS*get_group_id(0) + row; // Row ID of C (0..M)
const int globalCol = TS*get_group_id(1) + col; // Col ID of C (0..N)
// Local memory to fit a tile of TS*TS elements of A and B
__local int Asub[TS][TS];
__local int Bsub[TS][TS];
// Initialise the accumulation register
int acc = 0;
// Loop over all tiles
const int numTiles = K/TS;
for (int t=0; t<numTiles; t++) {
// Load one tile of A and B into local memory
const int tiledRow = TS*t + row;
const int tiledCol = TS*t + col;
Asub[col][row] = A[tiledCol*M + globalRow];
Bsub[col][row] = B[globalCol*K + tiledRow];
printf("Asub[%d][%d]=A[%d]=%d\t",col,row,tiledCol*M + globalRow,A[tiledCol*M + globalRow]);
// Synchronise to make sure the tile is loaded
barrier(CLK_LOCAL_MEM_FENCE);
// Perform the computation for a single tile
for (int k=0; k<TS; k++) {
acc += Asub[k][row] * Bsub[col][k];
//printf("acc[%d][%d]=%d\n",k,row,Asub[k][row]);
}
printf("acc = %d\n",acc);
// Synchronise before loading the next tile
barrier(CLK_LOCAL_MEM_FENCE);
}
// Store the final result in C
C[globalCol*M + globalRow] = acc;
}
下面具体分析一下这个kernel在运行时的的运行情况:
线看一下cpu端的配置:
#define TS 16
size_t globalWorkSize[2];
globalWorkSize[0]= heightA;
globalWorkSize[1]=widthB;
size_t localWorkSize[2] ;
localWorkSize[0]= TS;
localWorkSize[1]= TS;
errNum = clEnqueueNDRangeKernel(commandQueue, kernel, 2, NULL,
globalWorkSize, localWorkSize,
0, NULL, NULL);
这边新加了localworksize的参数,并且设置大小为16,这里设置大小是有讲究的:
首先TS 必须为2的幂次方
也就是
localWorkSize[0]*localWorkSize[1] <= CL_DEVICE_MAX_WORK_GROUP_SIZE 要怎么知道自己机器的这个size呢?可以通过
size_t maxWorkItemPerGroup;
clGetDeviceInfo(device, CL_DEVICE_MAX_WORK_GROUP_SIZE,sizeof(maxWorkItemPerGroup), &maxWorkItemPerGroup, NULL);
printf("maxWorkItemPerGroup: %zd\n", maxWorkItemPerGroup);
我这边打印的结果是256,也就是说我这边group的size最大只能设置到16.(16*16=256)
接下来看kernel的实现细节:
const int row = get_local_id(0); // Local row ID (max: TS)
const int col = get_local_id(1); // Local col ID (max: TS)get_local_id 这一组操作主要是获取work-group中当前work-item所在的2d索引。
const int globalRow = TS*get_group_id(0) + row; // Row ID of C (0..M)
const int globalCol = TS*get_group_id(1) + col; // Col ID of C (0..N)这个是通过当前work-item所在的group-id和自己在此group中的索引计算出,当前work-item在全局的索引。get_group_id是获取当前work-item所在work-group的id。
__local int Asub[TS][TS];
__ 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









