







简单概念理解
在opencl中,有个索引空间NDRange的概念,NDRange是一个N维的索引空间,N可以是1,2,3。NDRange由一个长度为N的整数阵列来定义,他指定了索引空间各个维度的宽度,每个work-item的全局id和局部id,都是N维元组。
有多个work-item构成的叫做work-group,作業組的 ID 跟作業項的全局 ID差不多。一個長度為 N 的陣列定義了每個維度上作業組的數 目。作業項在所隸屬的作業組中有一個局部 ID,此 ID 中各維度的取值範圍為0到作業組在相應維 度上的大小減一。因此,作業組的 ID 加上其中一個局部 ID可以唯一確定一個作業項。有兩種途徑 來標識一個作業項:根據全局索引,或根據作業組索引加一個局部索引。
下面一张简单的图介绍下在代码中的应用:

具体实例介绍
==—–矩阵的相乘。==
串行实现代码:
int a[midle*heightA];
int b[widthB*midle];
//初始化省略
for(int l=0;l<heightA;l++){
for(int n = 0;n<widthB;n++){
for(int q=0;q<midle;q++){
result[l*widthB+n] +=a [l*midle+q]*b[q*widthB+n];
}
//std::cout<<"r = "<<result[l*widthB+n]<<std::endl;
}
}
简单从网上找几张图片理解下矩阵乘法的基本步骤和原理:

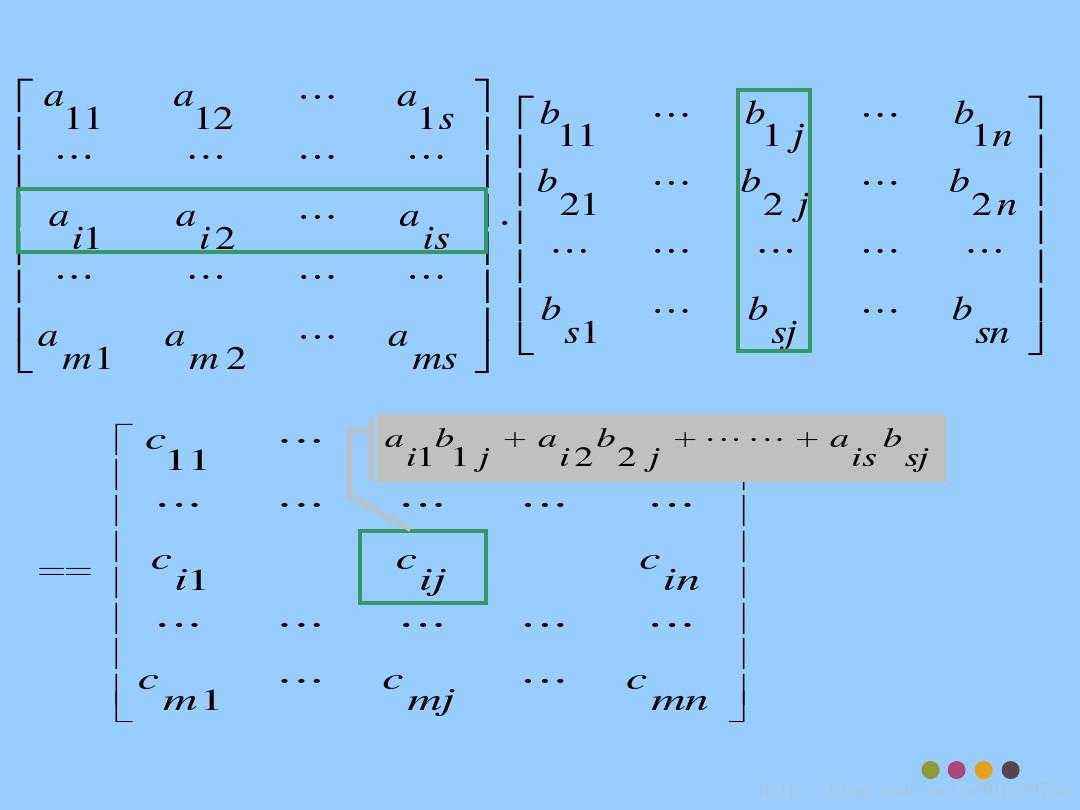
可以得知矩阵A其中的第i行和矩阵B中的第j列对应项相乘并相加的结果就是结果矩阵C[i][j]的元素了。
opencl实现矩阵相乘
a*b=c
下面是opencl的运行在gpu上内核具体实现,也就是矩阵相乘代码中在gpu中并行执行的单位代码:
__kernel void hello_kernel(__global const int *a,
__global const int *b,
__global int *result_matrix,int result_matrix_row,
int result_matrix_col,int compute_size)
{
int row = get_global_id(0);
int col = get_global_id(1);
int sum = 0;
for(int i=0;i<compute_size;i++)
{
sum += a[row*compute_size+i] * b[i*result_matrix_col+col];
}
result_matrix[row*result_matrix_col+col] = sum;
}这边的参数:a(M*P),b(P*N)是输入矩阵,result_matrix 是结果矩阵,result_matrix_row是结果矩阵的行(M),result_matrix_col是结果矩阵的列(N)。compute_size是a和b两个矩阵相同的行列,也就是P,是矩阵相乘中元素想加的个数。
kernel的核心代码即为上述串行代码中去掉外面两个for循环的代码,row和col分别是对应结果矩阵行和列的id,是变化的。目前这个kernel是也是这个work-item每次计算出结果矩阵中的一个元素,可以根据需要,改成每次计算出结果矩阵的一行数据,或其他块数据。我这边有做实验,计算出一个元素和一行元素在我的macbook pro上时间没有什么区别,网上看别的大神用代码说明改成计算一行的的元素,时间上减少了2/3,这部分有待验证。
如上所说,一次执行这个kernel算出结果矩阵当中的一个元素,那么需要执行M*N个这个kernel,意思就是说会有M *N个这样的(work-item)线程同时执行这个kernel,也就是并行执行。
这边为了加深对opencl 运行时的理解分析,对这个kernel做了打印测试分析。不过opencl spec上说printf是从缓冲区flush 出来的,没有顺序的,所以打印的结果仅供参考。
在cl文件中加入以下两句:
#pragma OPENCL EXTENSION cl_khr_fp64: enable
#pragma OPENCL EXTENSION cl_amd_printf : enable
就可以在kernel 中使用printf了,语法跟平时一样。
位了方便测试,把矩阵大小改成 6*6 ,10*10,20*20,对比他们的结果:
kernel中的改动:
__kernel void hello_kernel(__global const int *a,
__global const int *b,
__global int *result_matrix,int result_matrix_row,
int result_matrix_col,int compute_size)
{
int row = get_global_id(0);
int col = get_global_id(1);
printf("row =%d,col=%d\n",row,col);
int sum = 0;
for(int i=0;i<compute_size;i++)
{
sum += a[row*compute_size+i] * b[i*result_matrix_col+col];
}
printf("result_matrix[%d]=%d\n",row*result_matrix_col+col,sum);
result_matrix[row*result_matrix_col+col] = sum;
}
下面是结果:
row =0,col=0
row =1,col=0
row =2,col=0
row =3,col=0
row =4,col=0
row =5,col=0
row =0,col=1
row =1,col=1
row =2,col=1
row =3,col=1
row =4,col=1
row =5,col=1
row =0,col=2
row =1,col=2
row =2,col=2
row =3,col=2
row =4,col=2
row =5,col=2
row =0,col=3
row =1,col=3
row =2,col=3
row =3,col=3
row =4,col=3
row =5,col=3
row =0,col=4
row =1,col=4
row =2,col=4
row =3,col=4
row =4,col=4
row =5,col=4
row =0,col=5
row =1,col=5
row =2,col=5
row =3,col=5
row =4,col=5
row =5,col=5
result_matrix[17]=36
result_matrix[23]=36
result_matrix[29]=36
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









