







幸福的家庭都是一样的,不幸的家庭各有各的不幸 - 论一个糟糕的大数据平台工程师的自我修养
本来想写写如何成为一名优秀的大数据平台开发工程师,但说实话,这个话题太简单了!虽然我没有被Jeff dean大神附体,也不好意思腆着脸自认为有资格指点江山。但是,讲道理,谁不会呢?
好比,炒股票,不就是低买高抛吗,玩互联网,不就是拉流量去变现吗?
而要想成为一名优秀的大数据平台开发工程师,只要做到深度与广度并重,钻研技术,理解产品,能搭架构,能解Bug,那就妥妥的了。
道理如此简单,还需要多解释么?而我们,大概不是轻松的碾压了巴菲特,就是早已经顺利的在风口起飞了!

是的,优秀就是这么简单,太过无聊,所以,本文的重点,是聊聊如何能够做到不那么优秀,要想成为一个糟糕的开发工程师都需要有哪些表现。
我是小白我怕谁,正确的入门姿势
要想成为一个糟糕的大数据平台开发工程师,首先你得干上这行不是,怎么入门不重要,重要的是,自我修养,要从入门抓起。
大数据开发如何入门,在各种论坛或者技术会议中,时不时的总会有人问起。而提问者的问法往往也很类似:你好,我对大数据开发很感兴趣,我想学大数据,但我不知道该怎么入门,我该学些什么呢?
每每面对如此切中要害的问题,我总会有一种无比喜悦,乃至脱力的感觉。是的,真正感兴趣的同学,一定是激情澎湃,迫不及待的爱上了大数据,调研工作?没有的事,还需要调研,那不是真的热爱!况且那样的话,还怎么能问出如此粗旷而又犀利的问题呢?
对于这个问题,我也总能估计到提问者的预期答案。应该包括一串技能清单,以及回答问题者自身的成功实践示范:先看什么书,再学什么课程,然后搭建个什么系统,最好列个完整的学习计划和清单,要是还有各种职位需求的市场调研,薪资待遇的统计分析什么的,那就更完美了!
所以,我会怀疑这位同学是真的有兴趣,还是无脑跟风热点,又或者是学习能力/做事方法有问题吗? 不会,我只会认为,这位同学,简直太他妈好学了!

至于搞清楚自己到底喜欢什么,为什么喜欢,很重要吗?让砖家来替我做主,告诉我该学什么,效率岂不是更高?
敏而好学,不耻下问
学什么解决了,下一步是怎么学。
遇到问题前先思考一下,看一下文档,读点代码,分析一下日志?不存在的!都什么年代了,社交为王懂不懂?微信里加了这么多大数据群组干嘛用的,“讨论”问题啊!“敏”而好学,快就一个字!
什么?有人胆敢拿出“如何问一个好问题”这样的垃圾文章出来敷衍我这样好学的同学?傲娇了是吗?问一下能死啊?你懂还是不懂?懂就回答,不懂就不要瞎BB!古人不云么,不耻下问!你能有回答的机会就是你的荣幸!
好吧好吧,那么,如果想在这个领域长期耕耘下去,这样做靠不靠谱呢?据说大数据平台相关开发工作,面对的问题往往是复杂的,需要从业人员具备良好的学习总结和推理分析的能力。如果不具备主动学习和思考的习惯,听说也就几乎不可能成长成为这个领域的专家?
这简直就是妖言惑众啊!事实胜于雄辩,你看,明明有好多公司,有很多同学,日常工作中,就是这么做的。他们也搭过集群,C&V过代码,写过ETL程序,遇上“特别复杂”的难题,比如集群莫名其妙起不来了之类的,百度一下专家推荐的配置参数,搜索一下出错信息,就搞定了,还经常写点我司数据平台的踩坑经验和实战的分享,你就说牛不牛吧!
什么,这种情况长久不了,这类工作迟早会被替代,尤其是在偏底层的基础平台开发工作环境中?那得多久的将来啊?什么AWS和阿里云,他们平台上的标准化服务?没听过,我们要有自主知识产权啊!
效率优先,中文至上
能百度就不谷歌;能找到不知道谁写的搭建笔记,就坚决不读官网的Tutorial,要是还有手把手的教学视频,那就更好了。
集群如何调优,问题如何解决?根据错误信息,搜索踩坑指南啊,别管花多少时间,在多么犄角旮旯的博客也要搜出来。官网的FAQ或者Tuning Guide?抱歉,没时间看。Mailing list,Jira?那是什么东东?
怎么,不行么?这也没啥大不了啊,我不是看不懂英文,但是还是更习惯看中文,效率更高,如果不到山穷水尽,能用中文用中文呗。

或许吧,但除非你想永远玩别人早就玩剩下的东西,否则,尽可能接触第一手的资讯。英语差,看英文文档代价高?筛选过时或错误信息的代价可能更高!
流行的就是最好的
什么技术热门就学什么,这还用问么?别管行不行,先看赚不赚钱啊~~~
这种现象,不光大数据,各个技术领域都是如此,从这几年我所接触的求职者的求职意愿上就能很明显的看出来。
无论校招还是社招,无论是刚从别的方向转行想做大数据,还是在大数据领域内已经有过一些简单业务开发经验的同学,几乎90%以上的应聘者,都会把自己将来工作和实时计算挂上钩,越是“初生牛犊”的同学越是积极。可不,不玩Spark,不玩Flink,还怎么跟上时代,人家都说Hadoop已经被淘汰了!
而在985以上好一点的院校的应届生中,把技能点和求职方向放在算法和机器学习相关领域的同学更是大幅上升。决策树,向量机,贝叶斯,xNN , 天池竞赛,哪个没玩过都不好意思投简历。而大数据生态系中底层存储,计算组件,分布式原理架构等相关领域有过深入学习或实践的同学则明显呈下降趋势。
这也很容易理解,一方面机器学习和人工智能这一两年来风头正劲,Alpha狗,Alpha狗元,Alpha元赚足了眼球,另一方面,学习算法的门槛多低啊,即使没有工业环境,实践起来也相对容易,撸一下NG的课,做几个Demo,参加两个比赛,大多数理论知识也就能说个七七八八,还有满地的AI公众号,AI速成培训班等等(早几年则是各种大数据公众号和速成班,再早,是Java/Spring之类?),没几个月时间,就“略有小成”了啊~~~

而大数据平台的开发工作,属于偏底层工程技术的领域,如果没有合适的实践环境,多数同学靠看论文,读代码,想要真正入门其实难度还是不小的(事实上,这两年也很少有同学愿意花时间这么去做),即使相关实验室的项目,通常也偏理论,和现实问题相距甚远,动手能力堪忧。至于能靠参与开源项目进阶的同学更是凤毛麟角了。多数在中小公司实习的同学,也就是搭个Flume,做一下日志统计之类的工作。
当然,这没有贬低算法工程师的意思,事实上,优秀的算法工程师永远都是匮乏的,但和早几年的大数据一样,机器学习目前正处于技术成熟度曲线的第二个阶段,即期望膨胀阶段,有大量的人群拥入,加上早期具备相关知识的人也比较缺乏,所以蹭热点的同学,不管实际能力如何,就业情况也还不错。
不过,很明显的,这个领域也开始往第三阶段前进,人员开始沉淀,简单工作开始标准化,对从业人员的要求早晚也将不再是速成班出来的同学就能满足的了。不信,你去了解一下这两年阿里系招聘算法工程师的标准和待遇的变化。
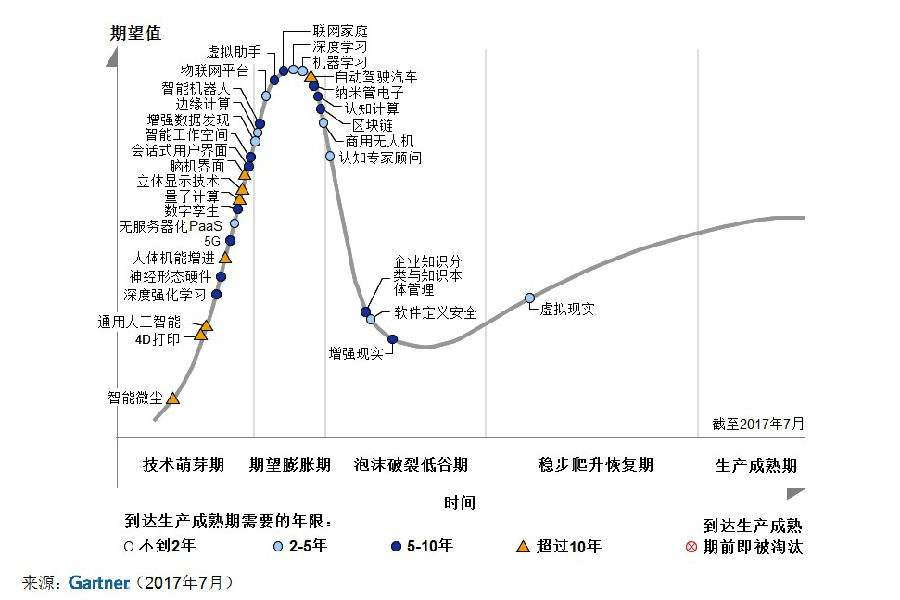
而大数据平台开发工作,在当前阶段,基本就属于速成的同学很难进一步发展的阶段,因为这个领域的部分基础设施,已经差不多渡过谷底第三阶段来到爬升,甚至稳定阶段了,简单的工作很快都要被成熟的服务或解决方案所替代。不具备进入下一阶段能力的同学,就业和成长的空间会越来越窄。
浙大的老校长竺可桢曾经说过,诸位在校:有两个问题要自己问问,第一:到浙大来做什么? 第二:将来要做什么样的人? 很显然,认清自己,是做任何事情的第一要务。
我相信,多数同学的答案当然不会是:1: 混,2: 混混。但是随波逐流,大家怎么做我就怎么做,却可能是不少同学在实际行动中给出的答案。
说这么多,其实就想说,蹭热点,本身问题不大,不过要想长期发展的话,关键是你本身也要具备对应的实力,大家都想做的事,你凭什么能比得过别人,就算眼下没问题,过几年等该领域成熟了呢?与其琢磨哪里是热点,不如想想自己适合做什么样的工作,如何让自己在技术的变革中持续的成长。
我们的征途,是星辰大海
也有同学会说,我并不是跟风追热点,只是,当前的工作,真的不适合我,我希望去做更有价值,更有挑战的事。至于为什么现在的工作不适合呢? 比如:
- 业务太烦,琐事太多,没有时间学习
- 干了很长时间,重复劳动,没有长进的空间
- 系统很成熟了,没有什么可做的了
- 做的事没挑战,发挥不出我的能力
- 做的事太Low,觉得没前途
- 问题太多,团队技术水平太差
总之,就是我行,但是,这事不行,环境不行,所以我要换方向,我要换地方。

诚然,上述情况未必不客观,他们很可能也是这些同学在工作过程中的真实感受,但我敢说,如果这就是全部原因的话,那么,有一多半的可能,根源不在环境,而在我们自身。因为上述情况,只是问题和现象,不是答案和原因。
- 琐事太多,重复劳动太多?有没有思考过如何化繁为简,还是只会用体力劳动代替脑力劳动?
- 系统成熟,没什么可做的?是系统真的完美无瑕了,还是我们坐井观天,眼界太低,不知道该如何改进?
- 做的事没挑战,做的事太Low?是事情本身太Low,还是我们做事的目标和方法太Low?
- 问题太多?是周边同事能力太差,还是自己只会头痛医头,解决问题不彻底,又或者是没有能力推进复杂问题的解决?
当然,每个人都希望在一个最好的环境中工作,这本身并没有错,但如果你只是单纯的回避问题,而未曾解决过这些问题,那么十有八九,在新的环境中,你早晚还是会遇上同样的问题。
书中自有颜如玉,让我看一下代码先
有些同学,特别是经常和开源相关组件打交道的同学,会特别喜欢阅读代码。
阅读代码,当然没错,说实话,爱读代码的同学现如今也不好找了。而且由于大数据环境下的底层组件在代码,流程和并发逻辑上的复杂性,再加上上层业务繁多,关系复杂。所以再成熟的系统,在生产过程中,也难免会遇上各种各样的疑难问题。如果还要做性能优化,那更需要对系统有深入的了解。所以不愿意看代码,只依靠百度的同学一定做不好相关的工作。

但是,过犹不及,毕竟阅读和熟悉代码只是手段,而非最终目的。遗憾的是,有时候,很多同学往往并没有认识到这一点,举些例子:
我们曾经有个同学特别喜欢阅读某个开源组件的代码,而且非常愿意把代码的阅读理解写成文档,发表在博客上。这本身并非坏事,你甚至会觉得,这简直太好学了不是!
但非常遗憾的是:
一来,这位同学的博客基本写的都是代码微观层面的流程理解,比如:要做件事,那么是怎么做到的呢?你看,代码是这样这样的。缺乏更高层的抽象归纳,需不需要这样做,为什么这样做,背后的思想是什么,有没有更好的方式等等
二来,他看代码的过程对日常工作的解决,往往没有什么帮助。比如遇到业务出错,任务运行缓慢,集群不稳定啦之类的问题,要不然觉得都是小问题,不屑一顾;要不然就是只会照本宣科,你看代码逻辑是这样的,遇到这种场景,就是这种现象。而几乎不会思考这样的场景下,就算代码本身没有bug,逻辑是不是合理,可以怎么改良,能否有其他方式规避等等。
第三点,最重要的,还是思想认识,总觉得代码读得多就牛逼了,这不,博客文档有人点赞,还能给社区贡献代码呢(虽然大多patch,都是哪里文档错误,哪个参数默认设置有问题,哪个逻辑,代码分支流程有缺失之类的补丁),至于工作没做好?那是这个工作太简单,不适合自己,发挥不了自己的能力,从来不认为是自己并没有真正具备解决问题的能力。所以,这位同学后来另谋高就了,而我一点都不觉得可惜。
写出来也不是为了喷这位同学,纯粹就事论事,也真心希望他在将来能慢慢意识到这一点。
多读点代码总没有坏处?
你可能会说,这只是个极端的例子,多数同学还是会针对问题和工作内容来学习代码的。即便如此,还是有很多时候,我觉得,有些同学代码看得过多了。
比如在还没有梳理清楚问题的核心矛盾是什么,可选的方案的优缺点有哪些之前,热爱阅读代码的同学可能就会将大量的时间投入到代码的深度阅读中去,总觉得多读点代码没有什么坏处。
这些同学可能未必不明白全局评估的重要性,但是他们很可能惯性的认为只有依靠完全彻底的理解代码,才能得到第一手的资料,才能“更好”的评估实施方案。
而事实上,这往往事与愿违,一方面,你可能迷失在一些无关痛痒的局部细节上,另一方面可能忽视了真正需要尽早找出答案的问题。

实际上,这其实在某种程度上来说,也是一种用战术上的勤快来掩盖战略上的懒惰的行为表现。因为阅读代码可能是程序员最习惯做的事。但是,采用其它可能的方式去评估或熟悉一个未知的系统呢?
比如详细阅读官方文档,进行功能验证,Demo测试,对类似系统进行横向比较,收集他人踩坑经验,寻找问题的其它可能解决途径等等,这些工作往往有可能更加快速全面的帮你了解一个系统,并做出合理的方案设计,但是这么做,因为涉及到持续的思考,分析,判断和尝试的过程,所以有时候很多同学往往反而不愿意在上面多费力气
“迷”之问题的“谜”之解决方式
相比代码阅读的执着,很多同学在分析问题时的表现却往往相反。
分布式环境下的问题往往错综复杂,如果一个问题不是明显的确定性逻辑错误,而是比如跑得慢,性能差,莫名随机Crash,timeout等等,不少同学很容易就快速陷入迷茫中。而为了将自己从迷茫中挣脱出来,往往会在问题排查过程中,轻易的将某些故障的现象归结为故障的原因,进而以治标不治本的方式来解决问题。
比如发现程序Crash或者跑得慢,存在GC或OOM的现象,就去调大内存或者调整GC配置参数,至于什么原因导致GC,什么情况会发生GC,谁在使用内存,合不合理,程序逻辑有Bug吗?就不想分析或者不会分析了;简单的归因为数据量变大啦,数据可能倾斜啦,宇宙射线爆发啦等等
再比如发现程序失败是因为某些方法调用过程超时,那就调大并发线程数,调大服务超时时间参数,增加机器资源等等,至于能否解释为什么偏偏这时候神秘超时,超时的现象合不合理?抱歉,现象无法复现,日志信息不足,分析不出来。。。
总之,看起来就是迷之问题,经过迷之自信的推理,得到一个迷之解决方案,就算治标,上述参数该怎么调,调多少,调完以后能不能有效,也是迷之结果,反正,先观察一段时间吧。。。
而做的好一点的代码流派的同学则可能在排查问题过程中,发现一个Error或Warning日志,还会去阅读相关的代码,最后花了几天阅读完代码,可能分析出了什么流程会打印出了这个Error日志,但却不知道,或者解释不了为什么当时程序会走到这个流程;再然后,同样也就排查不下去了。

上述情况,通常可能还是方法论问题,不知道如何把握问题的重点,在问题自身信息尚未收集清楚的时候,就过早的聚焦在某个收益未知的现象上。而对于进一步的动作,比如
- 质疑问题,考证现象,现有的结论是否站的住脚,是否还有疑点
- 能否再多方面收集一些信息,或者换一个角度,尝试别的方式分析问题
- 能否想办法复现问题,或者学习新的技能解锁进一步分析问题的能力
- 能否改进日志,争取下一次问题出现时能收集到更多信息
- 在自以为修复问题后,能否针对性的进行后续的监控分析,看看是否真的解决了问题
在类似这些工作方面,往往就没有表现出应有的执着了。
你可能要问,那我怎么知道信息收集完整了没有呢?这一方面,固然依靠你对系统的了解和过往的经验。但其实,多数情况下,你只需要将问题的现象(结果)和你怀疑的原因进行充分的因果对照,多数情况下就能避免过早的陷入一个错误的方向。你需要做的就是问自己三个问题:
- 历史分析,由果推因:如果问题的出现是由于这个原因,那么之前没有出现这个问题的时候,这个原因存在么?
- 当前现状,由因推果:如果这个原因会导致这个问题,那么他还会导致其它什么问题吗?那些问题是否存在?
这两个问题检验因果之间的相关性,就是因果关系要进行正反论证,而不仅仅是单方面推理。但这有时候还不够,你还需要问第三个问题来验证因果性自身。
- 这个原因是源头么?还是也可能只是一个和问题强相关的共生现象?
这个问题有时候不太好回答,也没有固定的套路来排查,但如果对于这个原因本身,你并没有找到一个明确的变更点,那无论它有多么的强相关,也不要过早的认为它就是根源。
总之,事出必有因,排查问题的过程,你要针对的是疑点,哪里解释不通,就针对哪里收集信息;这并不是说你不能去猜想可能的原因,不能快速的做决定,但猜想不是一厢情愿,需要信息来支撑,需要和现象相比对。
世间繁华,尽是过眼云烟
作为一个有梦想的工程师,你一定会去关注新技术。
如果方法得当,在短期内,靠深入阅读文档,翻阅核心代码等等手段,你往往是可以快速的在几天内对一个系统形成基本的认知。
只可惜,大数据领域的技术日新月异,加上很多系统相对复杂的架构特点,决定了这些新技术,往往信息量不小,如果你没有真正深入的实践过,通常很难形成有效的长期知识记忆。可能再过一个月,你刚掌握的内容,就都忘得一干二净了。
于是,无论你多么勤奋努力的去拓展你的知识面,到头来可能的结果就是,所有这些努力,都打了水漂,在你脑海中留下的,就只是各种人云亦云的皮毛概念和广告用语了。

按照互联网领域的说法,这是花了很多时间精力去拉新,但是在留存环节,效果惨淡。
这种现象其实很普遍,毕竟人的脑容量是有限的,理论上,要解决不外乎就几条路
- 天赋异禀,容量超人,过目不忘
- 重要知识,印象深刻,选择性留存
- 借助外部存储单元
第一条,你这把年纪了,估计很难有质的变化。
第二条,最常见的就是通过实践,加深认识,反复接触相关知识,不断刷新巩固。但是如果你要追求知识面,很显然你无法在所有的方向都投入这么多的时间。
第三条,该备份的没备份,就算备份了,加载不回来又怎么办 ;)
所以,怎么办呢?有什么最佳实践么?个人以为,可行的方法之一,是对相关的知识及时进行总结而不是仅仅浏览。如何总结呢?这一点,固然没有绝对适合每个人的最佳方式,但是撰写一些具有分享性质的文档,不管是以外部的博客文章,公众号文章的形式,还是以内部ppt分享的形式,通常都会是一个相对有效的方法。
可能也会有很多同学说,我其实也是有记笔记,但是我没有时间整理,另外,我也没想过要通过分享扬名立万,就自己学习嘛,所以也没有写这类文档的需求。
对此我想说,分享固然是写这类文档的目的之一,但其实,它只是一个副产品,更重要的是帮助自己提升知识留存的能力。如果你的学习笔记只是对各种知识点的copy/paste性质的摘要文档,缺乏整理,没有分享的价值,那么,这种类型的笔记,对于你自己的价值,可能也远低于你的想象。
总之,花过的时间,就要产生价值,想办法燕过留毛。做好留存的工作,在一个需要长期积累的领域,很多时候可能比拉新更加重要,将来的激活成本也会低很多。
小结
挣扎了很久,还是写出了一篇俗套乏味的文章,好吧,我尽力了,从鸡汤的角度再总结一下吧:
- 有“钱途”的方向,未必适合你,除非你具备战胜80%以上的跟风者的能力
- “快速”学习的结果通常是欲速则不达,请学会思考,请阅读第一手资料
- 阅读代码很重要,但比阅读代码更重要的,是阅读问题。
- 知识面决定了你的广度的,但信息不等于知识面,人云亦云的概念一钱不值。
- 在抱怨工作之前,先审视自身问题,毕竟改变自己更加容易,也更加普遍有效。
最后再补充一句在食品安全反反伪科学中常说的一句话:“脱离剂量谈毒性,都是耍流氓”,上述所有问题,并无绝对对错,重要的是程度的把握,你是否认清了自己的目标,你所做事情与你所想要结果是否能够匹配。
常按扫描下面的二维码,关注“大数据务虚杂谈”,务虚,我是认真的 ;)















 212
212











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









