








Capacity
上篇博客说过,ML的central challenge就是model的泛化能力,也就是generalization.
The ability to perform well on previously unobserved inputs is called generalization.
那什么是Capacity呢?通俗的说就是你的model能够很好地表达examples的数量.
The ability of the learner (or called model) to discover a function
taken from a family of functions.
比如说,下面的几个predictor:
- Linear predictor
y = wx + b- Quadratic predictor
y = W2X^2 + W1X + b- Degree-4 polynomial predictor
y = b+W1x+W2X^2+W3X^3+W4X^4
明显对于4次多项式函数,其能够capture更复杂的functions.
对于线性的predictor,其能够很好地的代表线性数据,假设此时能够代表的examples的数量是n1,对于二次函数很明显其能够拟合线性的(W2=0)也能够拟合二次的(W2!=0),假设此时能够代表的examples的数量是n2:
明显的, n2 > n1,quadratic predictor family更加丰富(richer).
Capacity can be measured by the number of training examples {Xi , Yi} that the learner could always fit, no matter how to change the values of Xi and Yi.
Underfitting && Overfitting
说这个的话,还是先从训练(Training)开始说起,大家可能经常说训练,但是什么是Training呢?
Training: estimate the parameters of f from training examples {Xi , Yi)}.
Training中,我们会定义一个cost function或者叫objective function,训练中我们需要做的就是最优化次此函数,此时会产生training error.
衡量model的generalization,我们会让model作用在一个单独的set上,叫做test set,同样的也会产生generalization error或者叫test error.
决定算法的优秀程度的因素(factor)就是:
Make the training error small.
Make the gap between training and test error small.
这两个factor实际对应的就是Underfitting和Overfitting.
从学习feature的能力方面描述就是:
Underfitting就是learner不能有效的学习到training examples的特征.
Overfitting就是learning对于training examples fits well,但是泛化能力很弱.
从training error和test error方面,大牛Bengio是这样描述的:
Underfitting occurs when the model is not able to obtain a sufficiently low error value on the training set.
Overfitting occurs when the gap between the training error and test error is too large.
下面的图直观的表示了Underfitting和Overfitting:
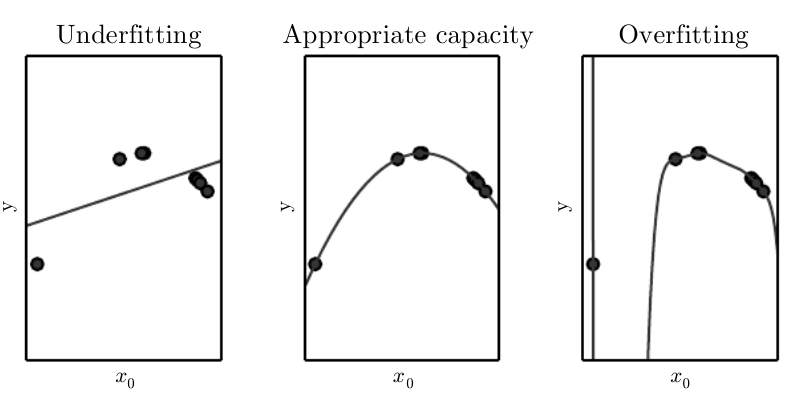
我们通过控制model的capacity,可以看出其更加倾向于Underfitting或者是Overfitting.
model的capacity小的话,可能会出现Underfitting的状况; model的capacity太大的话,可能会出现Overfitting的状况.
Models with low capacity may struggle to fit the training set. Models with high capacity can overfit by memorizing properties of the training set that do not serve them well on the test set.
比如说,对于二次函数可以很好表达的examples,你使用线性去拟合,此时就会出现Underfitting,表现就是training error和test error都很大,同时两者之间的gap很小.
Overfitting的话,其典型表现如下:
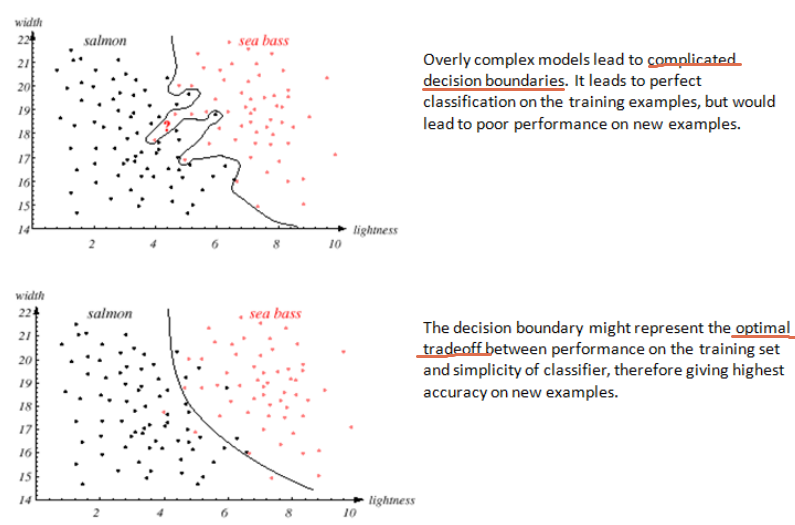
很明显,对于上面的图,其发生了Overfitting,下面的图才是此数据点应该有的decision boundary.
常见的发生Underfitting的原因是:
Model is not rich enough.
Difficult to find the global optimum of the objective function on the training set or easy to get stuck at local minimum.
Limitation on the computation resources (not enough training iterations of an iterative optimization procedure).
常见的发生Overfitting的原因是:
The family of functions is too large (compared with the size of the training data) and it contains many functions which all fit the training data well.
Without sufficient data, the learner cannot distinguish which one is most appropriate and would make an arbitrary choice among these apparently good solutions.
In most cases, data is contaminated by noise. The learner with large capacity tends to describe random errors or noise instead of the underlying models of data (classes).
所以谨慎的决定你的model的capacity,我们需要找到Underfitting和Overfitting的过渡点,即找到optimal capacity.
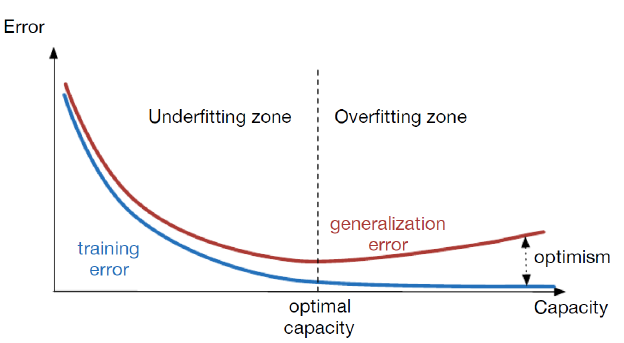
optimal capacity 此时test error和training error的gap最小.
同样的随着training examples的增加,optimal capacity也在变化,如下图:
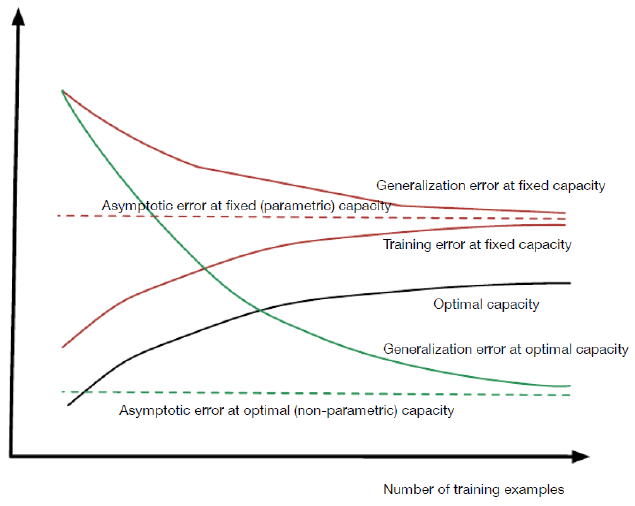
如果capacity过大,如何减小呢?常用的有如下几种方式:
Reduce the number of features.
Reduce the number of independent parameters.
Add regularization to the learner.
Reduce the network size of deep models.
Reduce the number of training iterations.
这篇就说到这,下篇继续














 246
246











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









