







这篇不算是基础系列,只是在网上看见别人写的,感觉很不错,翻译的别人的英文
原文链接: 原文
数据集扩充
对于深度的NN来说,数据集过小会很容易造成Overfitting,扩充数据集的方法通常有以下几种:
horizontally flipping
random crops
color jittering
预处理(normalization)
常见的有一下三种:
减去均值
zscore
白化(whittening)
效果逐步增强
减去均值
>> x -= np..mean(X, axis = 0) # zero-centerzscore
就是减去均值,除以标准差
>> X -= np.mean(X, axis = 0) # zero-center
>> X /= np.std(X, axis = 0) # normalize白化(whitening)
两种白化的操作:
PCA白化ZCA白化
首先,需要求出协方差矩阵和方向向量(u1,u2),将原始的数据点使用u1和u2来表示,得到新的坐标(投影)
PCA whitening
pca白化是指对上面的pca的新坐标X’,每一维的特征做一个标准差归一化处理
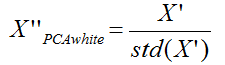
或者是:
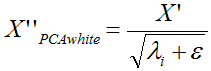
ZCA whitening
ZCA白化是在PCA白化的基础上,又进行处理的一个操作。具体的实现是把上面PCA白化的结果,又变换到原来坐标系下的坐标:
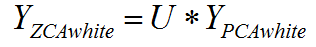
权重的初始化
初始化为全0,是错误的做法
一般采用两种方法:
Small Random Numbers
初始化为随机的接近0的小数
>> 0.01 * N(0,1) #N(0,1)表示均值为0的标准高斯分布Calibrating the Variances
方差(variance)为2/n
>> w = np.random.randn(n) * sqrt(2.0/n) # current recommendationTraining
Filter size
训练图片的大小是2的倍数的时候,比如32,64,224,512等
it is important to employ a small filter (e.g.,
3*3) and small strides (e.g., 1) with zeros-padding, which not only reduces the number of parameters, but improves the accuracy rates of the whole deep network. Meanwhile, a special case mentioned above, i.e.,3*3filters with stride 1, could preserve the spatial size of images/feature maps. For the pooling layers, the common used pooling size is of2*2.
Learning rate
推荐使用mini-batch的方式进行训练,初始的lr典型为0.1
对于validation set来说,没什么作用的话,可以将lr/2或者lr/5来试试
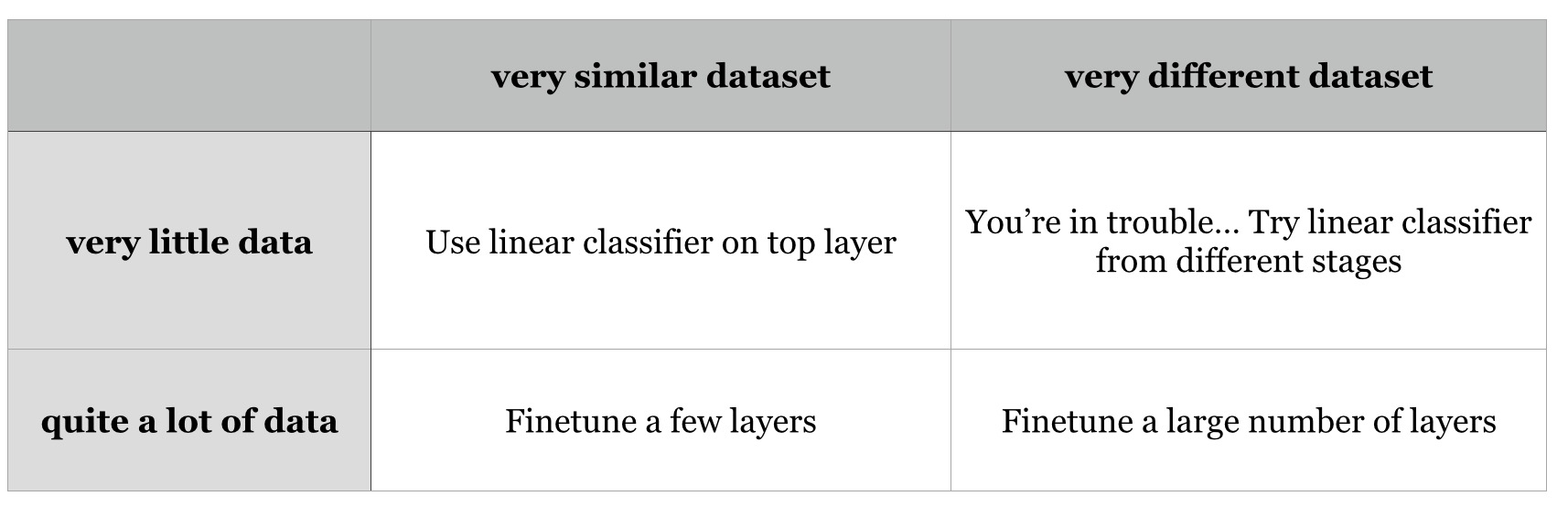
Fine-tune on pre-trained models
推荐使用VGG的网络
Activation Functions
sigmoid很少用,不推荐(kill gradients, not zero-centered)tanh比sigmoid要好(is zero-centered)ReLU系列:ReLU,PReLU,Leaky ReLU,RReLU,中推荐使用PReLUandRReLU
Regularizations
L1正则
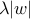
L2正则
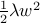
l2正则一般情况下优于l1正则
Dropout
0.5的概率值是典型的做法
数据倾斜
常用的解决方法:
sampling techniques
1. duplicating instances(maybe special crops processing) from the minority classes until a balanced distribution is reached (oversampling)
2. removing instances from over-represented classes (undersampling)
3. it is suggested that a combination is the best solution for extremely imbalanced distributions
4. generating new data in minority classes based on the current data
cost sensitive techniques
a higher penalty can be given to the network when it misclassifies the minority classes during training
One-class learning
- only provides training data from a single class(每一类去训练,不停的fine-tuning)
- firstly fine-tune on the classes which have a large number of training samples (images/crops), and secondly, continue to fine-tune but on the classes with limited number samples














 2302
2302











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









