








接着上篇,上篇讲解了怎么在ubuntu下安装Caffe,如果一切没问题的话应该是可以用了,下面自己测试一下。
测试mnist
首先切换到caffe-master的主目录,mnist是作为一个演示存在于caffe-master/examples/mnist下的,需要三步来运行:
<1>获得mnist手写数据库数据
$ sh data/mnist/get_mnist.sh<2>根据获得的原始数据建立数据集(Lmdb形式)
$ sh examples/mnist/create_mnist.sh<3>训练并获得验证集合的成功率
$ sh examples/mnist/train_lenet.sh这些脚本Caffe都是写好了的,直接运行就可以了,如果没错的话,你应该看到类似于下面的输出
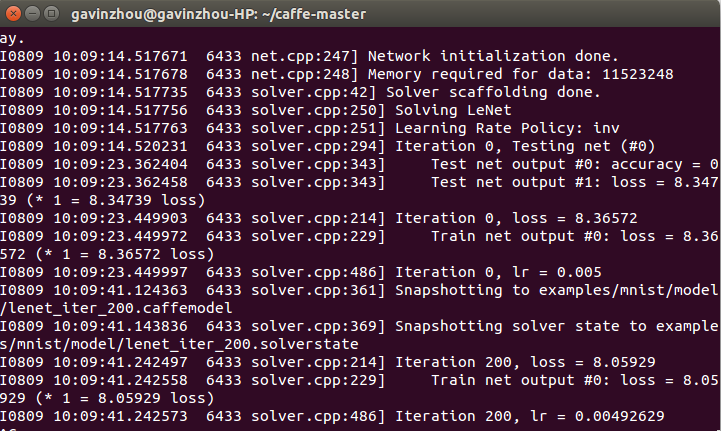
输出的内容就是创建相应的网络和进行迭代训练,这里我只截图了刚开始训练的部分,它会产生相应的model,以后我们就可以拿这些model去进行识别了
Caffe上训练使用自己的数据集
我就以这个来演示下如何使用caffe来使用自己的数据进行训练和识别(分类);这是自己做的中文汉字识别的一个实验,大概有3K多个汉字,我将每个汉字归为一个类,所以总共有3K多个类,然后就可以在上面训练识别。由于汉字什么的长得和手写数字还是很像的(明显不同与猫、狗之类的),所以我就偷懒用了mnist的网络结构来训练,最后效果也还不错。ps:数据多点结果应该更好点
(1)对自己的数据进行分类
在我这个来说,就是把每个汉字归为一类,首先新建个train文件夹用来做训练,类的编号从0开始,1,2,3,4,5…….这样写,大概是这样的:

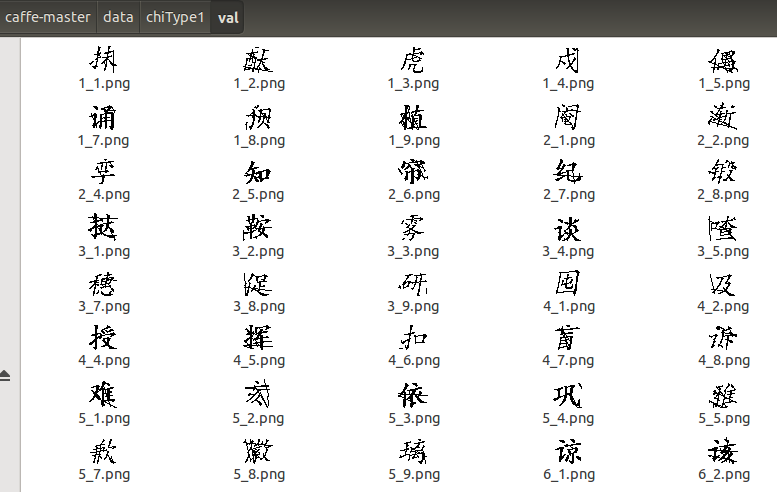
再建个val文件夹,用来做验证,val文件夹下所有的图片不用分类,直接放一起就可以了,大概是这样:
(2)写训练的数据集和验证的数据集TXT
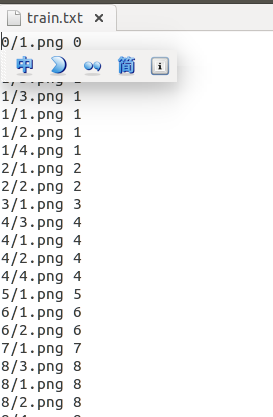
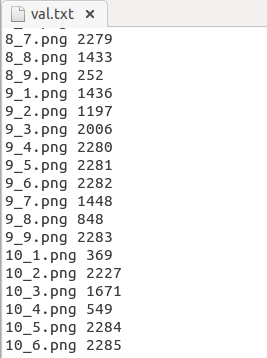
train.txt就是将train文件夹下的图片归类,val.txt直接写图片的类编号,大概是这样:
(3)做数据集
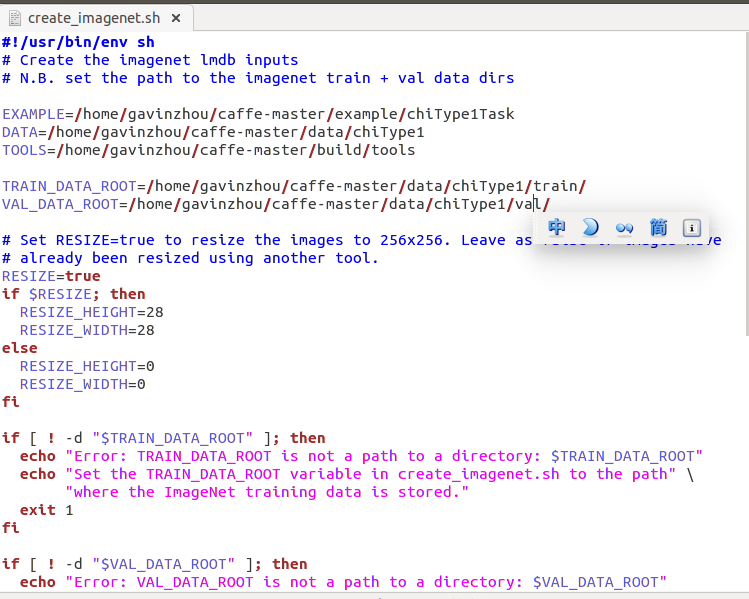
从imagenet拷贝create_imagenet.sh,进行修改,主要写上自己的train和val的路径
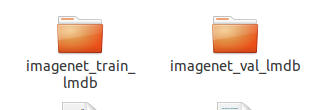
修改完之后就可以运行了,会创建两个数据集:
(4)定义网络结构
上面说了,对于汉字我就采用了mnist的网络结构,直接拷贝(3)中获得的两个数据集到examples/mnist下,最后就是这样的:
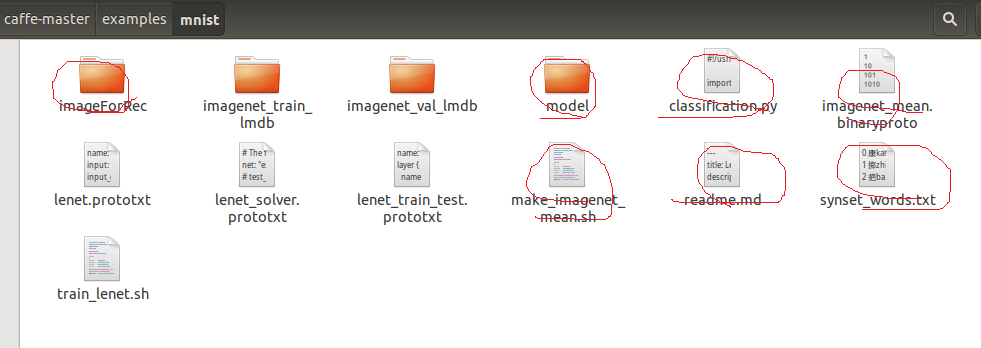
红色圈出的是不需要的,当然如果你需要加均值的话,可以使用make_imagenet_mean.sh,改下路径就可以用了,但不是必须的
主要是修改lenet_train_test.prototxt文件的内容:
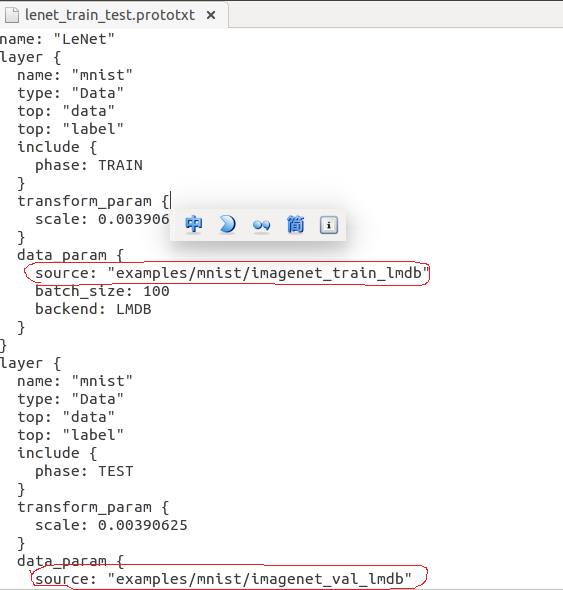
修改下路径就可以了,红色标明的地方
还有就是连接的个数,写上自己实际的类的个数,很重要不然会报错
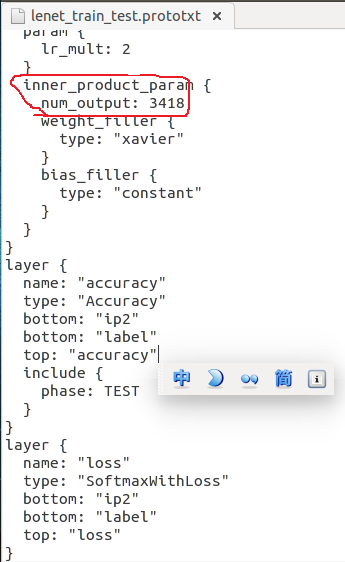
(5)训练
直接运行lenet_train.sh就可以了,它调用lenet_train_test.prototxt的网络结构,学习率,decay之类的参数在lenet_solvet.prototxt里面,大家看着需要自己设置,会产生model文件和验证结果,类似于上面用mnist自带的数据集训练的结果
最后结果截图我就不放了,跟第一张差不多,说的就是迭代到多少次,成功率(accuracy)是多少,损失(loss)是多少
总结一下做自己的训练集的步骤:
<1>分类;将自己的训练数据分成类并写train.txt文件,val直接全放一起,写val.txt文档
<2>做数据集文件(lmdb)
<3>定义网络结构
<4>训练并验证
上面说的不太清楚的地方,欢迎咨询!















 8239
8239

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









