







浅说深度学习(1):核心概念
原文来自Nvidia开发者社区:Deep Learning in a Nutshell: Core Concepts
作者:Tim Dettmers, Author at Parallel Forall
翻译:Kaiser
此为系列首篇,旨在提供直观简明的深度学习引导,涵盖深度学习的基本概念,而不设计很多数学和理论细节。当然如果要做更深入的研究,数学肯定是必不可少的,但是本系列主要还是用图片和类比等方式,帮助初学者快速建立大局观。
第一节介绍深度学习的主要概念。第二节交代一些历史背景,并解释训练过程、算法和实用技巧。第三节主讲序列学习,包括循环神经网络、LSTM和机器翻译中的编码-解码系统。第四节将转进到增强学习领域。
Kaiser:因为本篇主要讲概念,所以较为平铺直叙,结构上呈“分-总”模式。如果你对某些概念已经了解,可以跳过当节。
核心概念
机器学习(Machine Learning)
在机器学习中,我们(1)读取数据,(2)训练模型,(3)使用模型对新数据做预测。训练可以看作是当模型拿到新数据的时候、逐步学习一个的过程。在每一步,模型做出预测并且得到准确度的反馈。反馈的形式即是某种衡量标准(比如与正确解的距离)下的误差,再被用于修正预测误差。
学习是一个在参数空间里循环往复的过程:当你调整参数改正一次预测,但是模型却可能把原先对的又搞错了。需要很多次的迭代,模型才能具有良好的预测能力,这一“预测-修正”的过程一直持续到模型再无改良空间。
特征工程(Feature Engineering)
特征工程从数据中提取有用的模式,使之更容易被机器学习模型进行分类。比如,把一堆绿色或蓝色的像素区域作为标准,来判断照片上是陆生动物还是水生动物。这一特征对于机器学习模型十分有效,因为其限制了需要考虑的类别数量。
在多数预测任务中,特征工程是取得好结果的必备技能。然而,因为不同的数据集有着不同的特征工程方法,所以很难得出普遍规律,只有一些大概的经验,这使得特征工程更是一门艺术而非科学。一个数据集里极其关键的特征,到了另一个数据集里可能没有卵用(比如下一个数据集里全是植物)。正因为特征工程这么难,才会有科学家去研发自动提取特征的算法。
很多任务已经可以自动化(比如物体识别、语音识别),特征工程还是复杂任务中最有效的技术(比如Kaggle机器学习竞赛中的大多数任务)。
特征学习(Feature Learning)
特征学习算法寻找同类之间的共有模式,并自动提取用以分类或回归。特征学习就是由算法自动完成的特征工程。在深度学习中,卷积层就极其擅长寻找图片中的特征,并映射到下一层,形成非线性特征的层级结构,复杂度逐渐提升(例如:圆圈,边缘 -> 鼻子,眼睛,脸颊)。最后一层使用所有生成的特征来进行分类或回归(卷积网络的最后一层,本质上就是多项式逻辑回归)。
 图1:深度学习算法学得的层级特征。每个特征都相当于一个滤波器,用特征(比如鼻子)去过滤输入图片。如果这个特征找到了,相应的单元就会产生高激励,在之后的分类阶段中,就是此类别存在的高指标。
图1:深度学习算法学得的层级特征。每个特征都相当于一个滤波器,用特征(比如鼻子)去过滤输入图片。如果这个特征找到了,相应的单元就会产生高激励,在之后的分类阶段中,就是此类别存在的高指标。
图1显示了深度学习算法生成的特征,很难得的是,这些特征意义都很明确,因为大多数特征往往不知所云,特别是循环神经网络、LSTM或特别深的深度卷积网络。
深度学习(Deep Learning)
在层级特征学习中,我们提取出了好几层的非线性特征,并传递给分类器,分类器整合所有特征做出预测。我们有意堆叠这些深层的非线性特征,因为层数少了,学不出复杂特征。数学上可以证明,单层神经网络所能学习的最好特征,就是圆圈和边缘,因为它们包含了单个非线性变换所能承载的最多信息。为了生成信息量更大的特征,我们不能直接操作这些输入,而要对第一批特征(边缘和圆圈)继续进行变换,以得到更复杂的特征。
研究显示,人脑有着相同的工作机理:视锥细胞接受信息的第一层神经,对边缘和圆圈更加敏感,而更深处的大脑皮层则对更加复杂的结构敏感,比如人脸。
层级特征学习诞生在深度学习之前,其结构面临很多严重问题,比如梯度消失——梯度在很深的层级处变得太小,以致于不能提供什么学习信息了。这使得层级结构反而表现不如一些传统机器学习算法(比如支持向量机)。
为解决梯度消失问题,以便我们能够训练几十层的非线性层及特征,很多新的方法和策略应运而生,“深度学习”这个词就来自于此。在2010年代早期,研究发现在GPU的帮助下,激励函数拥有足以训练出深层结构的梯度流,从此深度学习开始了稳步发展。
深度学习并非总是与深度非线性层级特征绑定,有时也与序列数据中的长期非线性时间依赖相关。对于序列数据,多数其他算法只有最后10个时间步的记忆,而LSTM循环神经网络(1997年由Sepp Hochreiter和Jürgen Schmidhuber发明),使网络能够追溯上百个时间步之前的活动以做出正确预测。尽管LSTM曾被雪藏将近10年,但自从2013年与卷积网络结合以来,其应用飞速成长。
基本概念
逻辑回归(Logistic Regression)
回归分析预测统计输入变量之间的关系,以预测输出变量。逻辑回归用输入变量,在有限个输类别变量中产生输出,比如“得癌了” / “没得癌”,或者图片的种类如“鸟” / “车” / “狗” / “猫” / “马”。
逻辑回归使用logistic sigmoid函数(见图2)给输入值赋予权重,产生二分类的预测(多项式逻辑回归中,则是多分类)。
 图2:logistic sigmoid函数
f(x)=11+e−x
f(x)=11+e−x
图2:logistic sigmoid函数
f(x)=11+e−x
f(x)=11+e−x
逻辑回归与非线性感知机或没有隐藏层的神经网络很像。主要区别在于,只要输入变量满足一些统计性质,逻辑回归就很易于解释而且可靠。如果这些统计性质成立,只需很少的输入数据,就能产生很稳的模型。因而逻辑回归在很多数据稀疏的应用中,具有极高价值。比如医药或社会科学,逻辑回归被用来分析和解释实验结果。因为逻辑回归简单、快速,所以对大数据集也很友好。
在深度学习中,用于分类的神经网络中,最后几层一般就是逻辑回归。本系列将深度学习算法看作若干特征学习阶段,然后将特征传递给逻辑回归,对分类进行输入。
人工神经网络(Aritificial Neural Network)
人工神经网络(1)读取输入数据,(2)做计算加权和的变换,(3)对变换结果应用非线性函数,计算出一个中间状态。这三步合起来称为一“层”,变换函数则称为一个“单元”。中间状态——特征——也是另一层的输入。
通过这些步骤的重复,人工神经网络学的了很多层的非线性特征,最后再组合起来得出一个预测。神经网络的学习过程是产生误差信号——网络预测与期望值的差——再用这些误差调整权重(或其他参数)使预测结果更加准确。
Kaiser:以下为几个名词的辨析,包括最近几年的习惯变迁,我认为不需要深究。
单元(Unit)
单元有时指一层中的激励函数,输入正是经由这些非线性激励函数进行变换,比如logistic sigmoid函数。通常一个单元会连接若干输入和多个输出,也有更加复杂的,比如长短期记忆(LSTM)单元就包含多个激励函数,并以特别的布局连接到非线性函数,或最大输出单元。LSTM经过对输入的一系列非线性变换,计算最终的输出。池化,卷积及其他输入变换函数一般不称作单元。
人工神经元(Artificial Neuron)
人工神经元——或神经元——与“单元”是同义词,只不过是为了表现出与神经生物学和人脑的紧密联系。实际上深度学习和大脑没有太大关系,比如现在认为,一个生物神经元更像是一整个多层感知机,而不是单个人工神经元。神经元是在上一次AI寒冬时期被提出来的,目的是将最成功的神经网络与失败弃置的感知机区别开来。不过自从2012年以后深度学习的巨大成功以来,媒体经常拿“神经元”这个词来说事儿,并把深度学习比作人脑的拟态。这其实是具有误导性,对深度学习领域来讲也是危险的。如今业界不推荐使用“神经元”这个词,而改用更准确的“单元”。
激励函数(Acitivation Function)
激励函数读取加权数据(输入数据和权重进行矩阵乘法),输出数据的非线性变换。比如output = max(0, weight_{data})就是修正线性激励函数(本质上就是把负值变成0)。“单元”和“激励函数”之间的区别是,单元可以更加复杂,比如一个单元可以包含若干个激励函数(就像LSTM单元)或者更复杂的结构(比如Maxout单元)。
Kaiser:原文这个例子显然把简单的问题说复杂了,建议跳过。
线性激励函数,与非线性激励函数的区别,可以通过一组加权值之间的关系体现:想象4个点A1, A2, B1, B2。点(A1 / A2),和(B1 / B2)很接近,但是A1和B1, B2都很远,A2亦然。
经过线性变换,点之间的关系会变化,比如A1和A2远离了,但同时B1和B2也远离了。但是(A1 / A2)和(B1 / B2)的关系不变。
而非线性变换则不同,我们可以增加A1和A2的距离,同时减小B1和B2的距离,如此就建立了复杂度更高的新关系。在深度学习中,每一次层的非线性激励函数都创造了更复杂的特征。
而纯线性变换,哪怕有1000层,也可以用一个单层来表示(因为一连串的矩阵相乘可以用一个矩阵乘法来表示)。这就是为什么非线性激励函数在深度学习中如此重要。
层(Layer)
层是深度学习更高级的基本构成单位。一层,就是接受加权输入、经过非线性激励函数变换、作为输出传递给下一层的容器。一层通常只含一种激励函数,池化、卷积等等,所以可以简单地与网络其他部分作对比。第一层和最后一层分别称为“输入层”和“输出层”,中间的都称作“隐藏层”。
卷积深度学习
卷积(Convolution)
卷积是一种数学操作,表述了混合两个函数或两块信息的规则:(1)特征映射或输入数据吗,与(2)卷积核混合,形成(3)变换特征映射。卷积也经常被当做是一种滤波器,卷积核(kernel)过滤特征映射以找到某种信息,比如一个卷积核可能是只找边缘,而抛掉其他信息。
 图3:用边缘检测卷积核,对图像进行卷积操作。
图3:用边缘检测卷积核,对图像进行卷积操作。
卷积在物理和数学中都很重要,因为他建立了时域和空间(位置(0,30)的,像素值147)以及频域(幅度0.3,频率30Hz,相位60度)的桥梁。这一桥梁的建立是通过傅里叶变换:当你对卷积核与特征映射都做傅里叶变换时,卷积操作就被极大简化了(积分变成了相乘)。
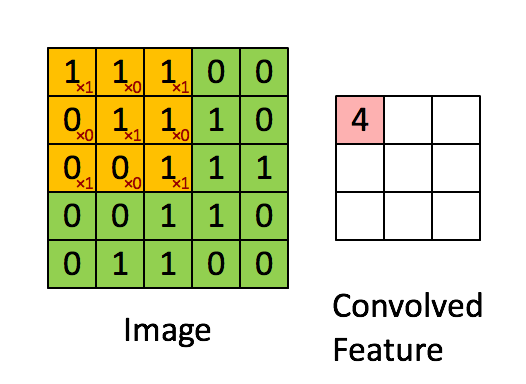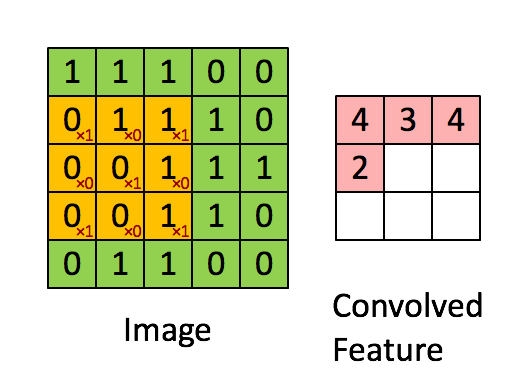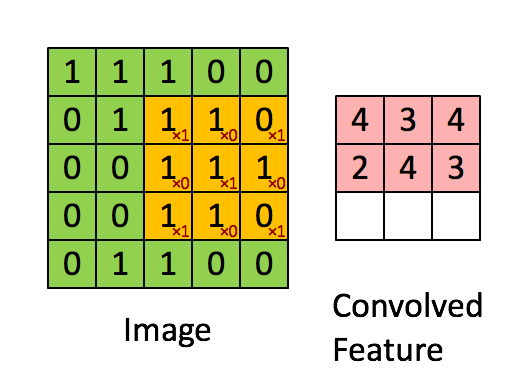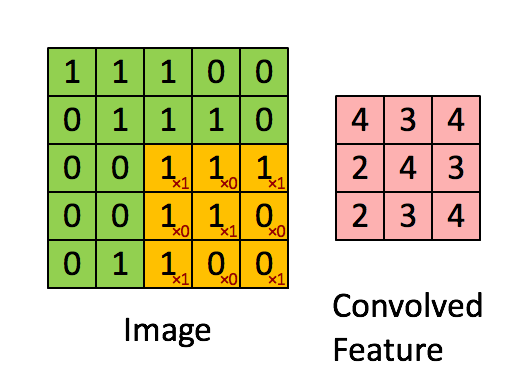 图4:用图像窗在整个图像上滑动计算卷积。原始图像(绿色)的图像窗(黄色)与卷积核(红字)相乘再相加,得到特征映射中的一个像素(Convolved Feature里的粉红单元)。
图4:用图像窗在整个图像上滑动计算卷积。原始图像(绿色)的图像窗(黄色)与卷积核(红字)相乘再相加,得到特征映射中的一个像素(Convolved Feature里的粉红单元)。
卷积,可以描述信息的扩散。比如当你把牛奶倒进咖啡却不搅拌,这时扩散就发生了,而且可以通过卷积精确描述(像素向着图像边缘扩散)。在量子力学当中,就是你测量一个量子位置的时候,量子在特定位置出现的概率(像素在边缘处于最高位置的概率)。在概率论中,则描述了互相关,也就是两个序列的相似度(如果一个特征(如鼻子)里的像素,与一个图像(比如脸)重叠,那么相似度就高)。在统计学中,卷积针对一系列正则化的输入,计算了加权动平均(边缘权重高,其他地方权重低)。另有其它很多不同角度的解释。
Kaiser:这里的“边缘”不同于之前的edge,原词为contour,指决策边界。比如对于人脸识别,人脸的轮廓就是contour,识别的重点。

不过对于深度学习,我们也不知道卷积的哪一种解释才是正确的,互相关(cross-correlation)解释是目前最有效的:卷积滤波器是特征检测器,输入(特征映射)被某个特征(kernel)所过滤,如果该特征被检测到了,那么输出就高。这也是图像处理中互相关的解释。
 图5: 图像的互相关。卷积核上下倒过来,就是互相关了。核Kernel可以解释为特征检测器,如果检测到了,就会产生高输出(白色),反之则为低输出(黑色)。
图5: 图像的互相关。卷积核上下倒过来,就是互相关了。核Kernel可以解释为特征检测器,如果检测到了,就会产生高输出(白色),反之则为低输出(黑色)。
池化/下采样(Pooling/Sub-Sampling)
池化过程从特定区域读取输入,并压缩为一个值(下采样)。在卷积神经网络中,信息的集中是种很有用的性质,这样输出连接通常接收的都是相似信息(信息像经过漏斗一样,流向对应下一个卷积层的正确位置)。这提供了基本的旋转/平移不变性。比如,如果脸不在图片的中心位置,而是略有偏移,这应该不影响识别,因为池化操作将信息导入到了正确位置,故卷积滤波器仍能检测到脸。
池化区域越大,信息压缩就越多,从而产生更“苗条”的网络,也更容易配合显存。但是如果池化面积太大,丢失信息太多,也会降低预测能力。
Kaiser:以下部分将之前罗列的概念串了起来,是全文的精华所在。
卷积神经网络(Convolutional Neural Network, CNN)
卷积神经网络,或卷积网络,使用卷积层过滤输入以获得有效信息。卷积层有的参数是自动学习获得的,滤波器自动调整以提取最有用的信息(特征学习)。比如对于一个普适的物体识别任务,物体的形状可能是最有用的;而对于鸟类识别人物,颜色可能是最有用的(因为鸟的形状都差不多,而颜色却五花八门)。
一般我们使用多个卷积层过滤图像,每一层之后获得的信息,都越来越抽象(层级特征)。
卷积网络使用池化层,获得有限的平移/旋转不变性(即使目标不在通常位置,也能检测出来)。池化也降低了内存消耗,从而能够使用更多卷积层。
最近的卷积网络使用inception模块,即1x1的卷积核进一步降低内存消耗,加速计算和训练过程。
 图6:一个交通标志图像被4个5x5卷积核滤波,生成了4个特征映射,这些特征映射经过“最大池化”。下一层对之前下采样过的图像应用10个5x5卷积核,并在此池化。最后一层是全连接层,所有的特征都组合起来传递给分类器(本质上就是逻辑回归)。
图6:一个交通标志图像被4个5x5卷积核滤波,生成了4个特征映射,这些特征映射经过“最大池化”。下一层对之前下采样过的图像应用10个5x5卷积核,并在此池化。最后一层是全连接层,所有的特征都组合起来传递给分类器(本质上就是逻辑回归)。
Inception
卷积网络中,inception模块的设计初衷是为了以更高的计算效率,执行更深、更大的卷积层。Inception使用1x1的卷积核,生成很小的特征映射。比如192个28x28的特征映射,可以经过64个1x1的卷积,被压缩成64个28x28的特征映射。因为尺寸缩小了,这些1x1的卷积后面还可以跟跟大的卷积,比如3x3,5x5。除了1x1卷积,最大池化也用来降维。
Inception模块的输出,所有的大卷积都拼接成一个大的特征映射,再传递给下一层(或inception模块)。
Additional material: Going Deeper with Convolutions
Conclusion to Part 1
This concludes part one of this crash course on deep learning. Please check back soon for the next two parts of the series. In part 2, I’ll provide a brief historical overview followed by an introduction to training deep neural networks.
Meanwhile, you might be interested in learning about cuDNN, DIGITS, Computer Vision with Caffe,Natural Language Processing with Torch, Neural Machine Translation, the Mocha.jl deep learning framework for Julia, or other Parallel Forall posts on deep learning.















 690
690

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









