








引言
LDA(Latent Dirichlet Allocation)称为潜在狄利克雷分布,是文本语义分析中比较重要的一个模型,同时,LDA模型中使用到了贝叶斯思维的一些知识,这些知识是统计机器学习的基础。为了能够对LDA原理有清晰的认识,也为了能够对贝叶斯思维有全面的了解,在这里对基本知识以及LDA的相关知识进行阐述,本系列包括两个部分:
- Latent Dirichlet Allocation——理论篇
- Latent Dirichlet Allocation——实践篇
在理论篇中将重点阐述贝叶斯相关的知识和LDA的基本思想,基本的知识点包括Gamma函数和分布,Beta函数和分布,Dirichlet函数和分布,贝叶斯定理,Gibbs采样等等。在接下来的文章,我们通过以下几个方面具体介绍LDA的核心思想:
- 基础知识:二项分布,多项式分布,Gamma分布,Beta分布,Dirichlet分布,贝叶斯定理,共轭分布
- 文本建模:Unigram Model,概率主题模型,Gibbs采样以及贝叶斯推理
一、基础知识
在贝叶斯思维以及LDA中需要使用到一些概率的知识,下面我们罗列下会使用到的一些基本知识。
1、二项分布
二项分布是概率分布里面最简单也是最基本的分布,要理解二项分布,我们首先得定义
n
次独立重复试验的概念:
假设对于一个事件
A
,在一次试验中,其发生的概率为
在这里,参数
k
是一个随机变量,便称这样的随机变量
可以验证下式成立:
2、多项式分布
多项式分布是二项分布的一个推广形式,在二项分布中,事件
A
的取值可能只能是发生或者是没有发生,而在多项式分布中事件
多项式分布的概率形式为:
3、Gamma分布
Gamma函数的具体形式如下:
其中, x>0 。Gamma函数的图像如下所示:
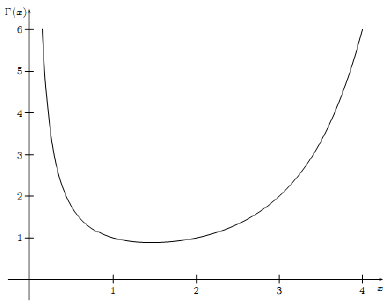
Gamma函数 Γ(x) 具有如下的一些性质:
- 性质1:
这个性质可以通过分部积分的方法得到证明,证明如下:
- 性质2:
- 性质3:
4、Beta分布
Beta函数的具体形式如下:
其中, a>0,b>0 。Beta函数有如下的一个性质:
上述的关于Beta函数的性质将Beta函数与Gamma函数联系起来,对于该性质的证明如下所示:
此时,令 z=u+v , t=uu+v ,上式可转化为:
由此可知: Beta(a,b)=Γ(a)Γ(b)Γ(a+b) 。
5、Dirichlet分布
Dirichlet函数的基本形式为:
其中, x1⋯xk⩾0 , ∑ki=1xi=1 。而Dirichlet分布的概率密度函数为:
其中, 0⩽x1⋯xn⩽1 ,且 ∑ki=1xk=1 , D(a1,⋯,ak) 的形式为:
注意到Beta分布是特殊的Dirichlet分布,即 k=2 时的Dirichlet分布。
6、贝叶斯定理
贝叶斯定理中牵涉到概率的一些基本知识,包括:
- 条件概率
- 联合概率
- 边缘概率
条件概率的表达形式为:
P(A∣B)
,其表示的含义是事件
A
在事件
联合概率的表达形式为:
P(A,B)
,其表示的含义是事件
A
和事件
事件
A
的边缘概率的表达形式为:
有了以上的定义,贝叶斯定理可以通过如下的贝叶斯公式表示:
对于上述的贝叶斯公式, P(B) 称为先验概率,即在得到新的数据前某一假设的概率; P(B∣A) 称为后验概率,即在得到了新的数据后,对原假设的修正; P(A) 称为标准化常量; P(A∣B) 称为似然度。
对于两个相互独立的事件的联合概率有如下的性质:
7、共轭分布
有了如上的贝叶斯定理,对于贝叶斯派而言,有如下的思考方式:
先验分布+样本信息 ⇒ 后验分布
上述的形式定义是贝叶斯派的思维方式,人们对于事物都会存在着最初的认识(先验分布),随着收集到越来越多的样本信息,新观察到的样本信息会不断修正人们对事物的最初的认识,最终得到对事物较为正确的认识(后验分布)。若这样的后验概率 P(θ∣x) 和先验概率 P(x) 满足同样的分布,那么先验分布和后验分布被称为共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
有了如上的的共轭先验分布的定义,有如下的两个性质:
1、Beta分布是二项分布的共轭先验分布,即:
Beta(p∣α,β)+Count(m1,m2)=Beta(p∣α+m1,β+m2)
对于上式,对于事件
A
,假设其发生的概率为
而对于参数
p
,则是服从参数为
已知在贝叶斯定理中有如下的公式成立:
则对于上述的后验概率,即为:
由上可知,Beta分布是二项分布的共轭先验分布。
2、Dirichlet分布是多项式分布的共轭先验分布,即:
Dir(p⃗ ∣α⃗ )+MultCount(m⃗ )=Dir(p⃗ ∣α⃗ +m⃗ )
我们对上式采用与Beta分布同样的证明方式,对于多项式分布,有下式成立:
然而概率 p⃗ 服从的参数为 α⃗ 的Dirichlet分布,即:
由贝叶斯定理可知:
由此可知,Dirichlet分布是多项式分布的共轭先验分布。
二、文本建模
对于一篇文章,是文章中出现的次的过程,在文章中,我们已经知道每个词出现的概率,则在省城文章的过程中,我们在词库中根据概率取出每个词,形成一篇文章。
1、Unigram Model
1.1、频率派
上述的过程说明了最简单的文本是如何产生的,我们对上述的过程数学化,假设:
- 词库中(即对所有文档中的词去停用词)共有
V
个词:
v1,v2,⋯,vV ; - 词库中每一个词出现的次数记为: n1,n2,⋯,nV ,所有词出现的总次数为 N ;
- 每个词对用的概率记为:
p⃗ ={p1,p2,⋯,pV} 。
假设有
m
篇文档,记为
在这里,我们假设文档与文档之间是相互独立的,而且进一步词与词之间也是相互独立的——词袋模型(Bag-of-words)。词袋模型表名词的顺序是无关紧要。基于这样的假设后上述的概率可以表示为:
对所有的这
m
篇文档中,词
至此,已经计算出全部文档的联合概率,但是对于每个词被选择的概率 pi 是一个未知数,一个很重要的任务就是估计上式中的每个词被选择的概率,通常使用的方法是使用最大似然估计的方法:
- 取上式的log似然函数:
- 对上述似然函数取最大值,即对每个概率值 pi 求导数:
最终,可以求得参数 pi 的估计值:
1.2、贝叶斯派
对于贝叶斯派来说,其并不认同上述的求解参数值估计的方法,贝叶斯思维认为,一切的参数都是随机变量,因此上述的选择每个词的概率不是一个确定的值,而是一个随机变量,随机变量就应该服从一个分布。因此参数 p⃗ 是由分布 P(p⃗ ) 决定的,该分布称为先验分布。则上述的过程就变成了如下的两个过程:
- 首先由先验分布 P(p⃗ ) 得到参数的样本 p⃗ ;
- 由参数 p⃗ 生成文档。
上述的过程,可以由下面的概率图模型表示:
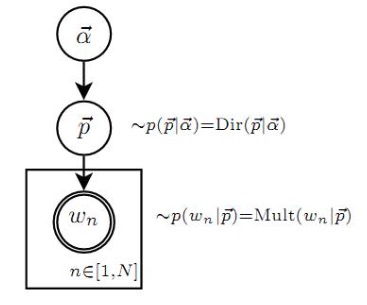
依据上述的观点,则文档的概率可以表示为:
此处的 P(p⃗ ) 称为先验分布,已知 P(W∣p⃗ ) 服从多项式分布,由上述的共轭分布的知识可知:
多项式分布的共轭分布是Dirichlet分布。
因此对于先验分布 P(p⃗ ) 可以选择为Dirichlet分布:
其中, α⃗ =(α1,α2,⋯,αV) , Δ(α⃗ ) 称为归一化因子:
由共轭分布的知识可知:
先验分布为Dirichlet分布+多项分布的数据知识=后验分布为Dirichlet分布
Dir(p⃗ ∣α⃗ )+MultCount(n⃗ )=Dir(p⃗ ∣α⃗ +n⃗ )
基于上述的共轭分布的性质,已知了参数 p⃗ 的先验分布为 Dir(p⃗ ∣α⃗ ) ,对于每个词出现的次数的统计服从多项式分布,则可以通过上述的性质得到后验分布:
为了求得后验分布中的参数 p⃗ ,可以使用其均值来估计每一个参数,即:
即:
对于整个文本的概率:
由于 P(W∣p⃗ ) 服从多项式分布,而 P(p⃗ ∣α⃗ ) 服从的Dirichlet分布,则上式可以表示成:
而已知: Δ(α⃗ )=∫∏Vi=1pαi−1idp⃗ ,则上式可以表示成:
2、概率主题模型
前面对文档的生成方式做了简单的介绍,其实在写文章的过程中,每一篇文章都会有一些主题,表示这篇文章主要讲的是关于哪方面的文章,如本篇文章主要是在介绍贝叶斯,LDA等等,而文章的基本组成单元式词,文章的主题则主要表现在词在不同组题的分布上,每一个词是在这些确定的主题上产生的,具体的如下图所示:
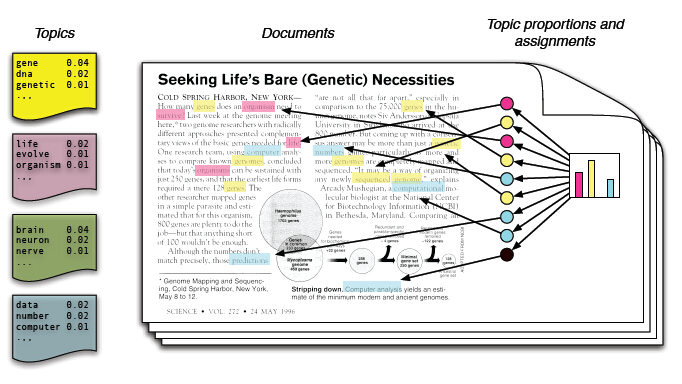
文章的主题最终体现在词在每个主题的分布上。在写文章的过程中,首先我们需要做的是确定文章的主题,在确定了文章的主题的前提下,我们产生每一个词,从而构成了整篇文章。
如果要写一篇文章,我们往往是先确定其主题,比如这篇文章是写社会的,还是写的技术类的,或者游记类的,在主题确定的条件下,如要写一篇关于机器学习方面的文章,在确定了主题的条件下,会谈及到损失函数,模型,神经网络,深度学习等等,每个词在这篇文章中的比重会有所不同。这便是文章的生成过程,即:
一篇文章,通常是由多个主题构成的,而每个主题大概可以用于该主题相关的频率最高的一些词来描述。
在上面们提及到一篇文章的生成过程,即:
- 对于文章选择主题
- 每个主题下对词汇的选择
2.1、频率派
频率派的观点是选择每个主题的概率和根据主题选择具体词的概率都是具体的值,根据上述的概率主题模型的思想,我们假设文档集中有
M
篇文档,每一篇文章对应的主题的概率为:
注意:这里的文档与文档之间是相互独立的,同一个文档中的词与词之间也是相互独立的。
因此,上述过程中很多步骤是可以合并在一起的,同样,我们有如下的假设:
- 词库中(即对所有文档中的词去停用词)共有
V
个词:
v1,v2,⋯,vV ; - 词库中每一个词出现的次数记为: n1,n2,⋯,nV ,所有词出现的总次数为 N ;
- 第
k 个主题下对应的词的概率为: φ⃗ k={φk,1,φk,2,⋯,φk,V} ,其中 k∈[1,K] ; - 第
m
篇文档对应的主题的概率记为:
θ⃗ m={θm,1,θm,2,⋯,θm,K} ,其中 m∈[1,M] ; - 对于每一篇文章中对应的词所属主题的编号为: zm,n 。
则对于第
m
篇文档
其中 P(z∣dm) 表示的是在每一篇文章对应的主题的编号,可以由 θm,z 表示; P(w∣z) 表示的是在主题编号确定的条件下选择词的概率,可以由 φz,w ,因此上式可以表示成:
由于在文档中词与词之间是相互独立的,因此对于一篇文档,其生成概率为:
2.2、贝叶斯派
上面介绍的思路中,对于文档选择主题的概率以及依据主题选择每一个词的概率都是固定的数,对于贝叶斯派来说,这是无法接受的,贝叶斯派认为所有的值都是随机变量,因此,在文档对应的主题以及依据指定的主题选择每一个词的概率都服从特定的分布。因此上述的过程可以通过如下的概率图模型表示:

该图可以分解成如下的两个部分:
1、 α⃗ →θ⃗ m→zm,n ,表示的是对于第 m 篇文档,我们首先根据参数
α⃗ 计算出其对应的主题的概率 θ⃗ m ,然后生成该文档中的第 n 个词对应的主题的编号zm,n ;
2、 β⃗ →φ⃗ k→wm,n∣k=zm,n ,表示的是根据参数 β⃗ 计算出在主题编号确定的条件下主题对应的词的概率,依据这个概率选择出每个词。
对于上述过程中的两个阶段,其中从文档的主题的概率到词对应主题的编号服从的是多项式分布,由上述的共轭先验分布的知识可以知道:
多项式分布的共轭分布是Dirichlet分布。
可以选择 θ⃗ m 是服从参数为 α⃗ 的Dirichlet分布,同样,我们可以选择 φ⃗ k 是服从参数为 β⃗ 的Dirichlet分布。
对于整个文档集来说,文档与文档之间是相互独立的,单个文档中词与词之间也是相互独立的,因此上述的两个过程我们可以分解成如下的两个过程:
- 首先对于 M 篇文档生成其对应的词对应的主题的编号
- 对于
K 个主题,生成所有的文本
有了上述的两个过程的分解,对于整个文档集,我们可以得到下述的生成概率:
其中, P(W∣Z,β⃗ ) 表示的是在文章主题确定的条件下生成词的概率, P(Z∣α⃗ ) 表示的是文档对应主题的概率。
对于上述的第一个过程有:
已知 P(z⃗ m∣θ⃗ m) 服从的是多项式分布,而 P(θ⃗ m∣α⃗ ) 服从的是Dirichlet分布,因此,上式可以转换成为:
其中,
n⃗ m=(n(1)m,n(2)m,⋯,n(K)m)
,
n(k)m
表示的是第
m
篇文档中属于第
对于第二个过程,有下式成立:
其中, P(w⃗ k∣φ⃗ k) 服从的是多项式分布,而 P(φ⃗ k∣z⃗ k,β⃗ ) 服从的是Dirichlet分布,则上式可以转化为:
其中,
n⃗ k=(n(1)k,n(2)k,⋯,n(V)k)
,
n(v)k
表示的是属于第
k
个主题的词中词
因此,对于整个文档,有:
3、LDA训练——Gibbs采样
3.1、Markov Chain的相关概念
MCMC(Markov Chain Monte Carlo)和Gibbs采样算法是用来生成样本的随机模拟方法,Gibbs采样算法是LDA中参数求解的一种很有效的方法,想要理解Gibbs采样,必须了解以下的几个概念:
1、马尔可夫链
马尔可夫链的数学表示如下所示:
上述公式的含义是由状态 Xt 到状态 Xt+1 只与状态 Xt 有关,而与之前的状态无关。
2、马氏链的平稳分布
如果一个非周期马氏链具有转移概率矩阵为
P
,且它的任何两个状态是连通的,那么
a.
b.
c. π 是方程 πP=π 的唯一非负解,其中:
π 称为马氏链的平稳分布。
3、细致平稳条件
如果非周期马氏链的转移矩阵
P
和分布
则 π(x) 是马氏链的平稳分布,上式被称为细致平稳条件。
以上三条定理摘自参考文献1。
3.2、Gibbs采样
现在我们假设平面上有一些点,这些点服从概率分布
P(x,y)
,取其中两个点
A
和
由上式可得:
由上式可以知道,如果以 P(y∣x) 作为任意两点之间的转移概率,那么任何两点之间的转移满足细致平稳条件,前提是两点之间的转移概率的条件是相同的,即在两点之间转移,必须保证这两点的其中一个维度是相同的,如上式中的横坐标 x 是相同的。
由此,我们可以得到Gibbs采样的通俗理解方式,即已知样本
(x0,y0),(x1,y0),(x1,y1),(x2,y1),⋯
当马氏链收敛后,得到的样本:
上述过程可由下面的形式描述:

这样的情况很容易推广到多维的情况:

上述两张图来自参考文献1。
3.3、LDA训练
对于LDA,我们希望的是能够计算在词确定的条件下计算其所属主题的概率,即如下的条件分布:
由于主题 Z 是一个隐含的变量,我们通过如上的Gibbs采样去求解,由贝叶斯公式可知:
而已知:
则可以推出下面的式子:
在Dirichlet分布中,我们知道:
因此有:
LDA的训练过程如下所示:

4、LDA推理
LDA推理的过程与LDA训练的过程类似,具体过程如下所示:

两张图来自参考文献1。
参考文献
1、LDA数学八卦
2、通俗理解LDA主题模型
5、Xuan-Hieu Phan and Cam-Tu Nguyen. GibbsLDA++: A C/C++ implementation of latent Dirichlet allocation (LDA), 2007















 85
85

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









