







下面是一些学习摘录,比较零散。由于过去时间比较久,主要是去年3、4月份开始接触深度学习及卷积神经网络。现在好久没搞了,对这块领域大脑没状态、热度降低,自然有些知识点就模糊了,当然花些时间还是可以捡起来的,所以本文写的很不走心。后悔当时没有及时整理文章,按照那时的状态及学习心得,应该可以写出很多东西。本文主要还是适合有一些卷积神经网络基础,但是很多细节还没彻底搞明白的人读。
对于单个样例(x,y),其代价函数为:
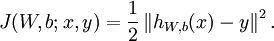
这是一个(二分之一的)方差代价函数。给定一个包含m个样例的数据集,我们可以定义整体代价函数为:
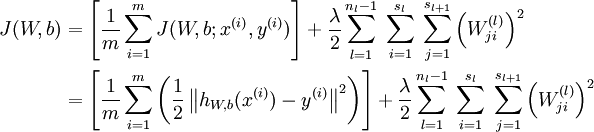
以上公式中的第一项J(W, b)是一个均方差项。第二项是一个规则化项(也叫权重衰减项),其目的是减小权重的幅度,防止过度拟合。J(W, b; x, y)是针对单个样例计算得到的方差代价函数。J(W, b)是整体样本代价函数,它包含权重衰减项。我们的目标是针对参数W和b来求其函数J(W, b)的最小值。不过J(W, b)是一个非凸函数,梯度下降法很可能会收敛到局部最优解。但是在实际应用中,梯度下降法通常能得到令人满意的结果。
梯度下降法中每一次迭代都按照如下公式对参数 W和b进行更新:
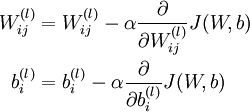
其中是α学习速率。梯度下降算法,其中最重要的步骤就是求梯度,这可以通过反向传播算法(back propagation)来实现。
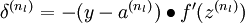
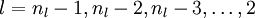 的各层,计算:
的各层,计算:
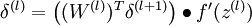 (通过下一层的残差来计算本层的残差,这样层层向前迭代推进)
(通过下一层的残差来计算本层的残差,这样层层向前迭代推进)
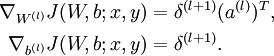
实现批量梯度下降法中的一次迭代:
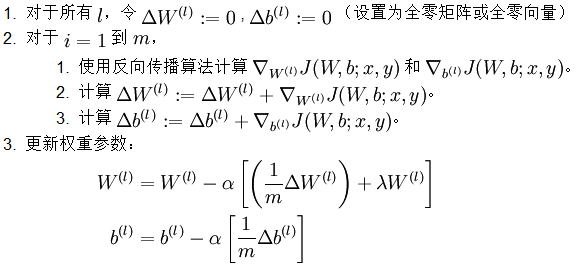
现在,可以重复梯度下降法的迭代步骤来减小代价函数的值,进而求解我们的神经网络。还记得那个把大象装冰箱分三步的段子吗?这个就是“把大象装冰箱分三步”算法。简洁公式的背后,隐藏着无比复杂的推导。
单个神经元训练,直接计算代价函数J对W和b的偏导数即可。总代价函数为每个样本代价函数之和。

从公式结果向上看,要想计算偏导数(梯度),需要计算J对z的导数及z对w的导数,而J对z的导数又可分解为J对a的导数及a对z的导数,J对a的导数就推到公式根部了,即上述代价函数的定义,代价函数中,J对a的导数,即为-(y - a),这样就可以依次计算了。
多层神经网络训练,对多层网络的训练需要求代价函数J对每一层的参数求偏导。该过程由反向前传播,这也是反向传播算法的本义所在。对每一个样本,先算出残差,再计算偏导数即梯度。

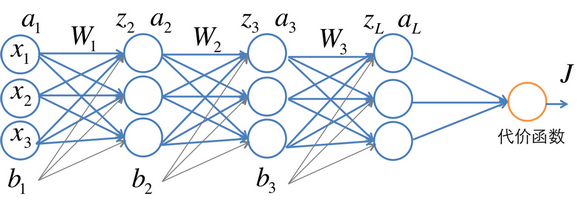
注意这里a与z,z与w,z与b的层内关系及层间的关系,a与z层内关系是: a = sigmoid( z ),a与z层间关系是: z = a*w + b,即本层的z等于上一层的a与w卷积加上偏置b。
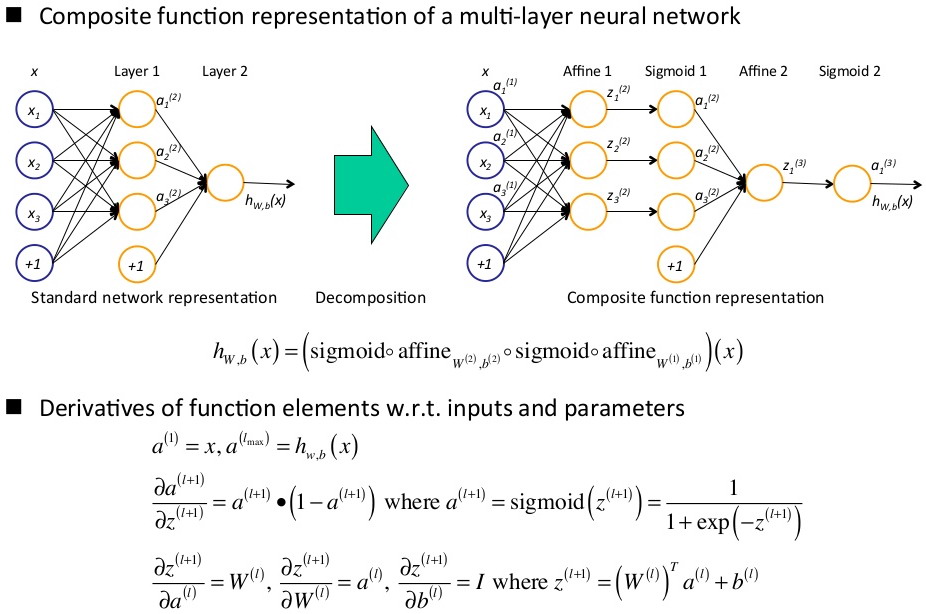

同样,这个公式从上往下看很容易看晕,而从下往上看反而容易看懂。
卷积神经网络训练,cnn:卷积-->sigmoid函数(或使用其他激励函数)-->池化。其前向传播和反向传播的示意图如下:
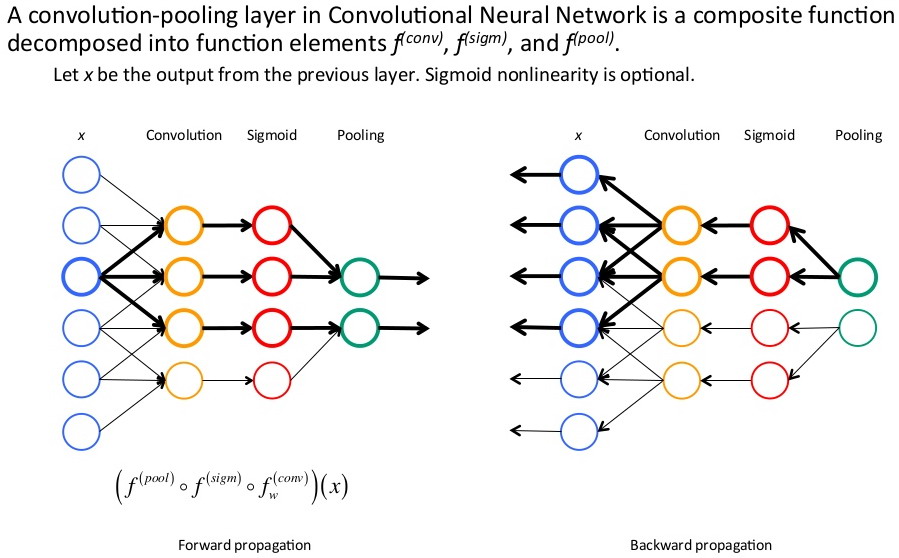
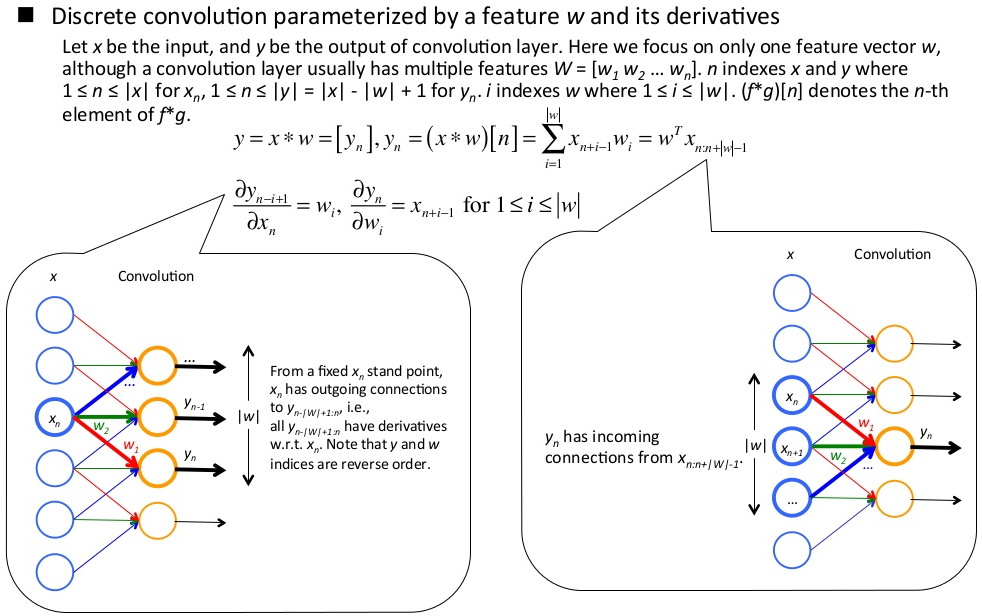
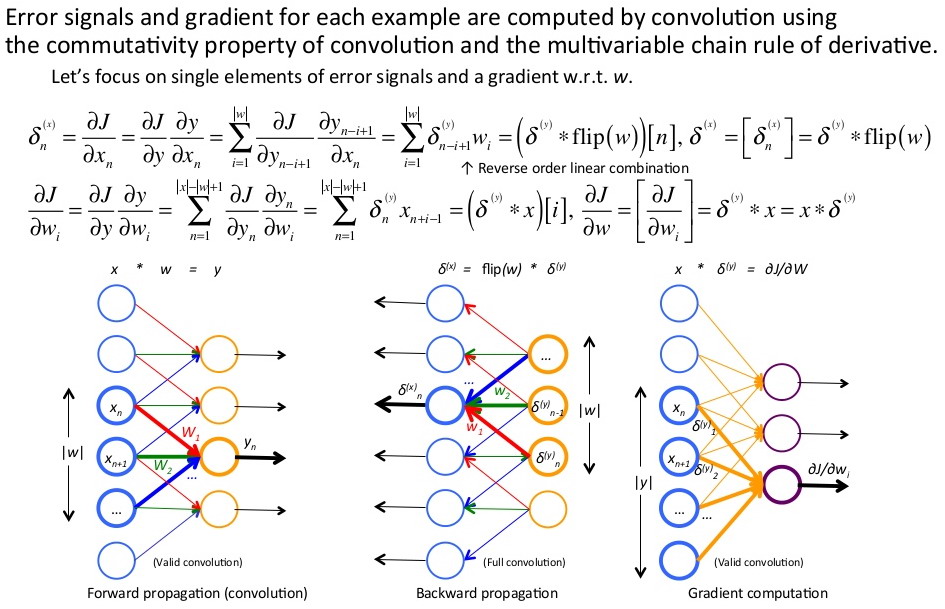
池化层:均值、最大值、p范数池化,这里池化不同,导数计算方式也不同。

池化层的反向传播推导:
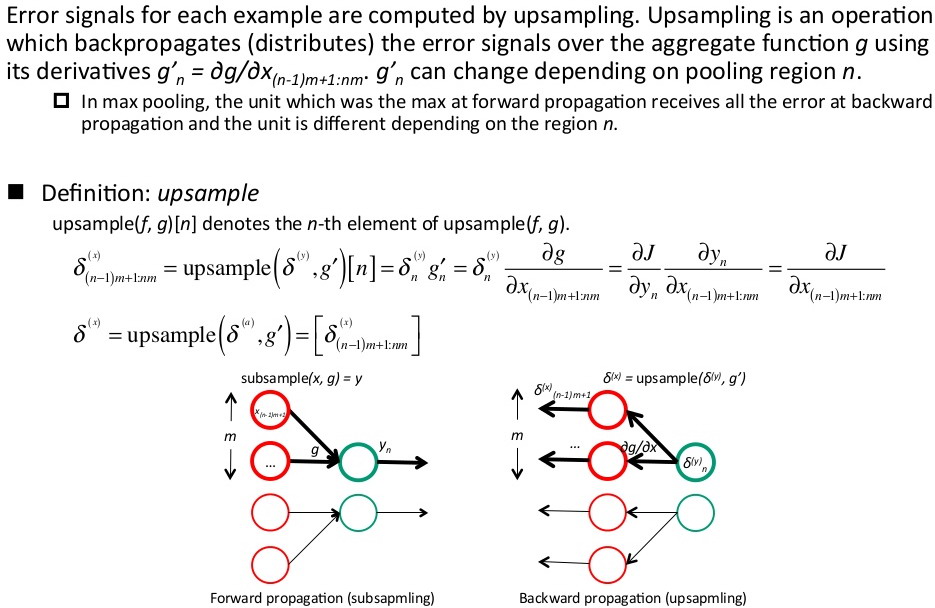
这里的推导过程也要从后往前看,从J对池化区域内x的偏导,得出前一层池化区域内x的偏导等于当前层y的偏导乘g的导数,这里g是池化映射关系,y=g(x)。
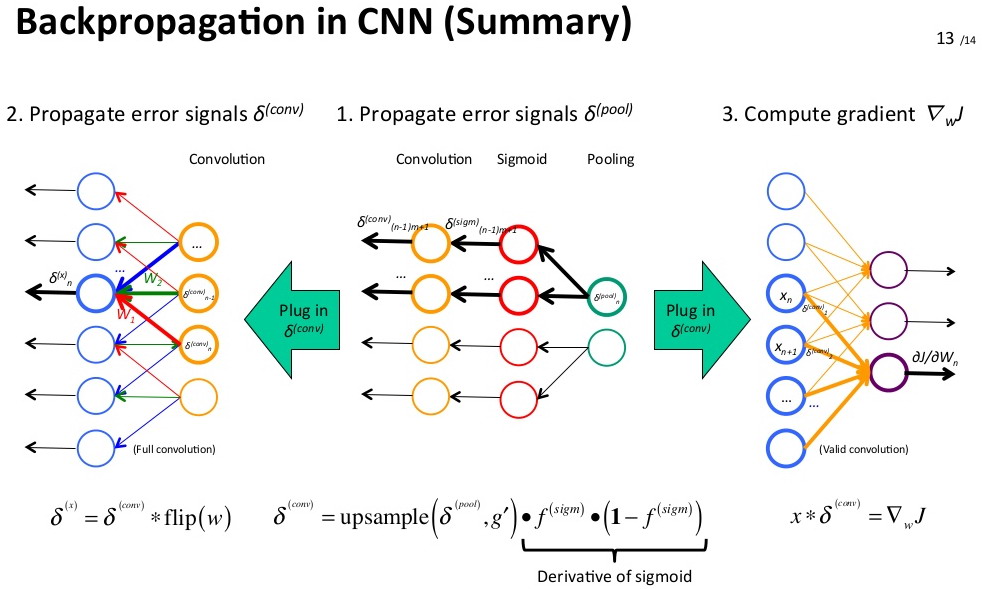
反向传播推导过程总结:















 4176
4176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









