







 这篇博客详细介绍了神经网络和卷积神经网络的训练过程,重点讲解了反向传播算法。从单个神经元开始,解释了如何求取代价函数关于参数的梯度,然后扩展到多层神经网络,阐述了误差信号如何通过网络层进行反向传播。接着,博主探讨了卷积神经网络中卷积和池化层的导数计算,以及它们在反向传播中的应用。通过这些理论,可以使用梯度下降等方法找到使代价函数最小化的最优参数,完成神经网络的训练。
这篇博客详细介绍了神经网络和卷积神经网络的训练过程,重点讲解了反向传播算法。从单个神经元开始,解释了如何求取代价函数关于参数的梯度,然后扩展到多层神经网络,阐述了误差信号如何通过网络层进行反向传播。接着,博主探讨了卷积神经网络中卷积和池化层的导数计算,以及它们在反向传播中的应用。通过这些理论,可以使用梯度下降等方法找到使代价函数最小化的最优参数,完成神经网络的训练。
神经网络的训练过程,就是通过已有的样本,求取使代价函数最小化时所对应的参数。代价函数测量的是模型对样本的预测值与其真实值之间的误差,最小化的求解一般使用梯度下降法(Gradient Decent)或其他与梯度有关的方法。其中的步骤包括:
- 初始化参数。
- 求代价函数关于参数的梯度。
- 根据梯度更新参数的值。
- 经过迭代以后取得最佳参数,从而完成神经网络的训练。
其中最重要的步骤就是求梯度,这可以通过反向传播算法(back propagation)来实现。
单个神经元的训练
单个神经元的结构如下图。假设一个训练样本为 (x,y) 。在下图中, x 是输入向量,通过一个激励函数
J(W,b,x,y)=12∥y−hw,b(x)∥2 (公式2)
这里激励函数以使用sigmoid为例,当然也可以使用其他的比如tanh或者rectived linear unit函数。要求的参数为 W 和
通过定义变量 z=∑ixiwi+b 可以将激励函数看做是两部分,如下图右图所示。第一部分是仿射求和得到 z , 第二部分是通过sigmoid得到
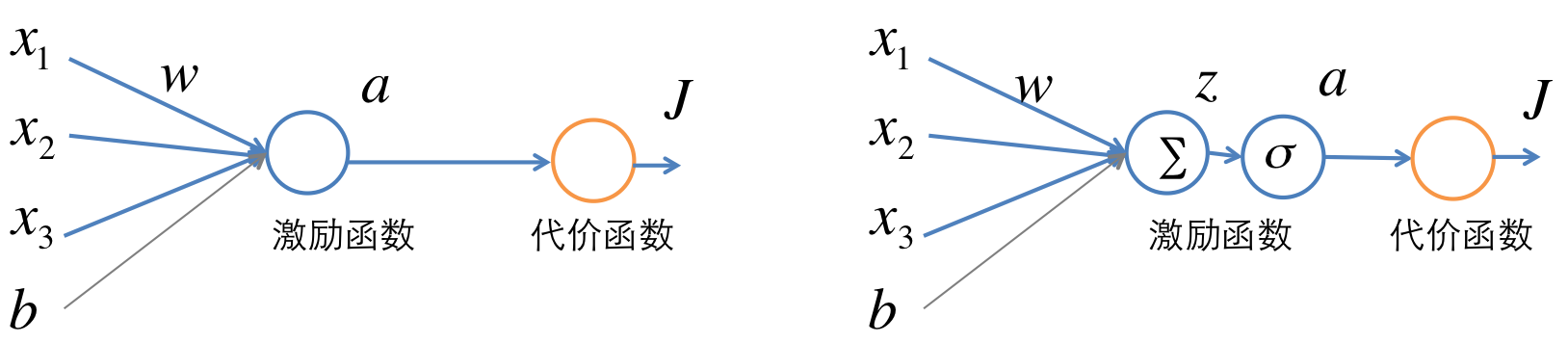
训练过程中,要求代价函数 J 关于
δ(a)=∂∂aJ(W,b,x,y)=−(y−a) (公式3)
δ(z)=∂∂zJ(W,b,x,y)=∂J∂a∂a∂z=δ(a)a(1−a) (公式4)
公式(4)中根据sigmoid函数的定义 σ(z)=11+e−z 可得 ∂a∂z=a(1−a) 。
再根据链导法则,可以求得 J 关于
∇bJ(W,b,x,y)=∂∂bJ=∂J∂z∂z∂b=δ(z) (公式6)
在这个过程中,先求 ∂J/∂a ,进一步求 ∂J/∂z ,最后求得 ∂J/∂W 和 ∂J/∂b 。结合上图及链导法则,可以看出这是一个将代价函数的增量 ∂J 自后向前传播的过程,因此称为反向传播(back propagation)。
多层神经网络的训练
多层网络的一个例子如下图。
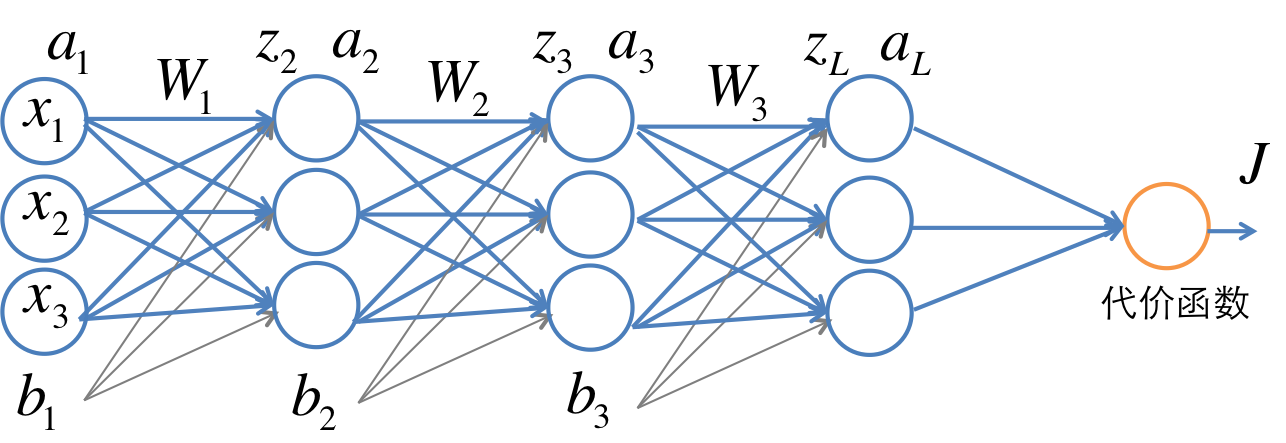
假设第 l+1 层的输入和输出分别是 al 和 al+1 , 参数为 Wl 和 b
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









