







 本文介绍了KNN(K-Nearest Neighbor)学习算法的原理,包括分类过程、回归处理以及算法改进方法,如组合分类器、核映射、预聚类和超球搜索。还提供了一个C语言实现KNN算法的示例。
本文介绍了KNN(K-Nearest Neighbor)学习算法的原理,包括分类过程、回归处理以及算法改进方法,如组合分类器、核映射、预聚类和超球搜索。还提供了一个C语言实现KNN算法的示例。
KNN学习(K-Nearest Neighbor algorithm,K最邻近方法)是一种统计分类器,属于惰性学习,对包容型数据的特征变量筛选尤其有效。KNN的基本思想是:输入没有标签即未经分类的新数据,首先提取新数据的特征并与测试集中的每一个数据特征进行比较;然后从样本中提取k个最邻近(最相似)数据特征的分类标签,统计这K个最邻近数据中出现次数最多的分类,将其作为新数据的类别。
一、KNN算法
KNN按一定的规则,将相似的数据样本进行归类。首先,计算待分类数据特征与训练数据特征之间的距离并排序,取出距离最近的k个训练数据集特征;然后,根据这k个相近训练数据特征所属的类别来判定新样本的类别:如果它们都属于同一类,那么新样本也属于这一类;否则,对每个候选类别进行评分,按照某种规则确定新样本的类别。
一般采用投票规则,即少数服从多数,期望的k值是一个奇数。精确的投票方法是计算每一个测试样本与k个样本之间的距离。
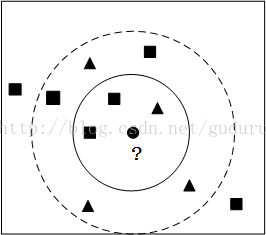
如下图小圆形要被归为哪一类,是三角形还是矩形?如果k = 3,由于矩形所占比例为2/3,小圆形将被归为矩形一类;如果k = 9, 由于三角形比例为5/9,因此小圆形被归为三角形一类。
假设数据集为:
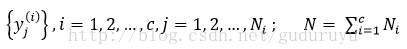
这些数据分别属于c种不同类别,其中Ni是第i个分类wi的样本个数。对于一个待测数据x,分别计算它与这N个已知类别的样本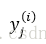
wi类的判决函数为:
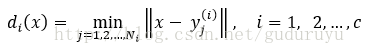
判决规则为:
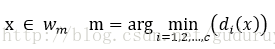
上述方法仅根据距离待识模式最近的一个样本类别决定其类别,称为最邻近法或1-邻近法。
为了克服单个样本类别的偶然性,增加分类的可靠性,可以考察待测数据的k个最邻近样本,统计这k个最邻近样本属于哪一类别的样本最多,就将x归为该类。
设k1, k2, ..., kc分别是x的k个样本属w
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 6315
6315

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









