







本博客主要是受到了《Learning Sentiment-Specific Word Embedding for Twitter Sentiment Classification》2014 ACL会议的启发。
在应用深度学习框架处理自然语言问题的时候,传统方法一般是首先利用无监督的语言模型训练出低维的distributed词向量,然后使用cnn或者rnn模型对这些词向量进行encode操作,最后得到句子的向量化表示,紧接着所有的处理都是基于该句向量的。
由于在训练得到词向量的时候使用的是无监督的方法,因此该词向量实际上代表了该词语在整个language中的语义信息,对于各种各样的nlp任务来说具有很好的普适性(相对于随机化生成词向量来说)。但正是这种普适性,造成了其对某一类特定任务的处理存在一定的瓶颈,其效果肯定不如针对该任务生成的定制化的词向量。举个例子来说,如果我们想做文本的情感分类,那么生成的词向量最好能够表征词语的情感含义,比方说“高兴”和“悲伤”这两个词语,如果应用普适化的方法它们在语义上都代表了情感,故它们的上下文可能十分相似,这直接导致它们在向量空间中的距离十分的接近,而这对应于情感分类场景来说是十分不利的。因为在情感分类的领域里,这两个向量的距离其实应该是比较远的。如果根据句子的情感倾向生成定制化的词向量,这些问题就能迎刃而解。
关于定制化的词向量,上述提到的论文里运用到了以下的结构:
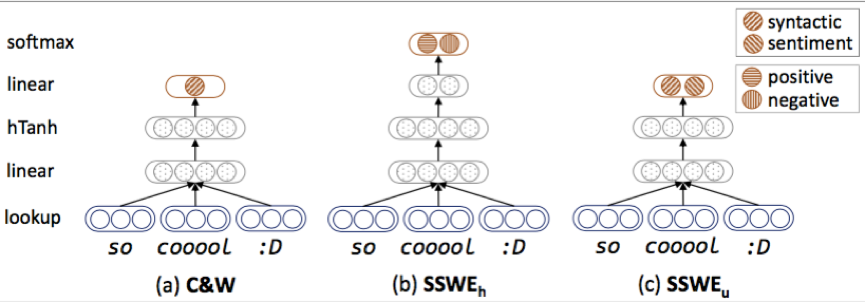
最左边的就是传统的语言模型C&W,它通过把固定窗口内的词语的向量concat起来作为正确的序列
t
,然后随机替换掉中间的词语作为错误序列
中间的 SSWEh 就是根据C&W改造的,不过省去了生成错误序列的步骤,整体的目标也变为预测当前窗口内短语的情感倾向。原文里是这样写的“An intuitive solution to integrate the sentiment information is predicting the sentiment distribution of text based on input ngram. We do not utilize the entire sentence as input because the length of different sentences might be variant. We therefore slide the window of ngram across a sentence, and then predict the sentiment polarity based on each ngram with a shared neural network. ”由于句子长度是不固定的,因此这里只预测了固定窗口内的短语的情感倾向,我个人感觉这里存在着较大的问题,因为即使是一句正向情感的话,并不是说这句话里所有短语体现出正向的倾向,这样一些一般的短语可能在正向和负向情感的句子中都出现,对于这部分词向量的生成就会存在较大的问题。要想避免这些问题,必须对窗口内出现的所有短语的组合进行重新的标注,或者对整个句子进行encode,整体的预测是基于该句子的。
最右边的 SSWEU 的模型是把C&W和 SSWEh 的损失函数进行结合,然后联合训练。
这篇论文给我带来最大的启发式定制化词向量的思想,的确传统的无监督的语言模型训练的词向量过于泛化,对于特定的任务会存在瓶颈,而打破瓶颈的一种比较明显的方式便是生成针对该任务(比方说情感分析)定制化的词向量,这样就能更好地提升模型效果。















 420
420

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









