







通常,深度学习模型都是运行在GPU(图像处理器单元),因为它有SIMD并行化指令,所以能够快速处理图片。SIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。其实CPU也可以使用SIMD指令,只不过GPU更擅长使用SIMD并行指令,GPU拥有更好地性能。Python的numpy库中矩阵运算会运用SIMD并行指令,从而获得更高的运算速度。所以深度学习会尽可能避免使用循环,尽量地多使用numpy库。下面举一个例子,看看他们之间的性能差距:

例子中可以看出,矩阵运算的效率会比循环运算高出将近600倍。
在使用numpy库时,通常有两点值得注意:
(1)使用矩阵而不要使用数组,如果该使用矩阵的时候使用了数组,会报一些莫名其妙的错误,下面举一个例子,以便于理解:
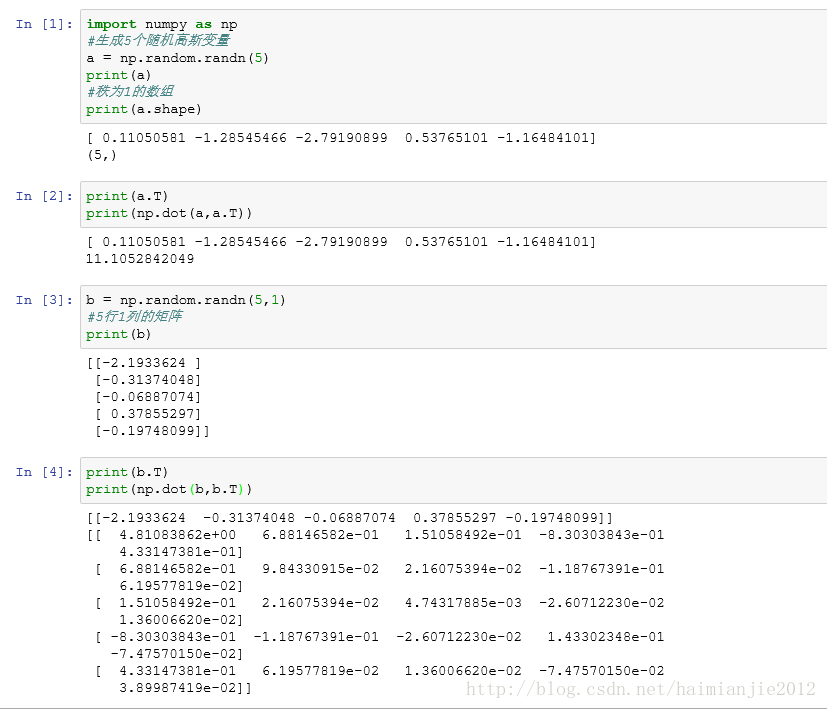
创建数组的时候,通常使用np.random.randn(5,1)形式,而不要使用np.random.randn(5),因为后者创建的是数组而不是矩阵。
(2)理解numpy的广播原则
首先举一个例子,计算每种食物各种成分的百分比:

下面是该题的源代码:
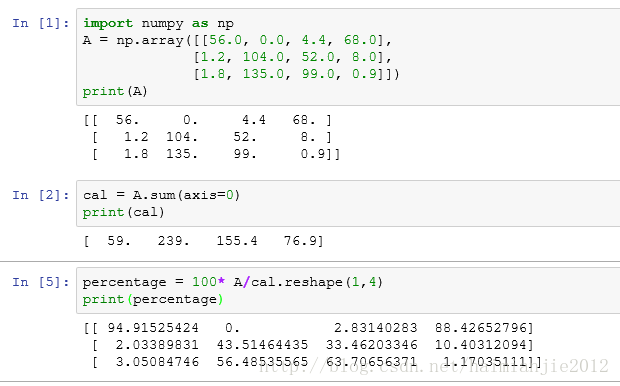
上面代码中,In [5]处的cal.reshape(1,4)显得有些多余,因为cal已经是一个1行4列的矩阵,但是这样做能够有效避免(1)所提到的错误。
计算percentage = 100*A/cal.reshape(1,4)时,cal矩阵首先进行了广播,广播后的形式为:
[ 59. 239. 155.4 76.9
59. 239. 155.4 76.9
59. 239. 155.4 76.9
59. 239. 155.4 76.9]
那么numpy的广播原则是怎样的呢,先看看下面这图:

图中,前两行的意思是:当一个m行n列矩阵与一个(1,n)或(m,1)矩阵运算时,(1,n)会复制m行广播为(m,n)矩阵,(m,1)会复制n列广播为(m,n)矩阵。
图中,后三行的意思是:当一个行矩阵或列矩阵与一个实数运算时,实数会广播成为与矩阵维数相同的同元素矩阵。
参考资料:
网易云课堂《神经网络和深度学习》第二周,吴恩达















 3132
3132











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











