







 本文通过实例介绍朴素贝叶斯分类器的工作原理。它基于贝叶斯公式和特征间的独立性假设,通过计算后验概率来决定分类。文章讨论了如何处理未出现的特征值,介绍了拉普拉斯修正来解决概率为零的问题,并提供了实际应用示例。
本文通过实例介绍朴素贝叶斯分类器的工作原理。它基于贝叶斯公式和特征间的独立性假设,通过计算后验概率来决定分类。文章讨论了如何处理未出现的特征值,介绍了拉普拉斯修正来解决概率为零的问题,并提供了实际应用示例。
分类器是根据某一事物一系列特征来判断该事物的类别。朴素贝叶斯分类器就是根据先验概率应用贝叶斯公式来求解 后验概率的一种分类器,哪种类别的概率大,就划分为哪种类别。(先验概率和后验概率不熟悉的请看最大似然估计),其实原理很简单,并不需要什么复杂的训练结构,复杂只是计算量,这个交给计算机即可,所以懂了原理,朴素贝叶斯分类器也就掌握了。先不写理论,以例子开始,希望能说的浅显易懂。
一、西瓜的好坏
这里是要借鉴周志华老师书中西瓜的例子的形式,这用这类例子讲解贝叶斯分类问题容易理解。现作简化如下:
现已知7个西瓜的好坏,西瓜的特征有三种:色泽{青绿、乌黑、浅白},根蒂{蜷缩、稍蜷、硬挺},敲声{浊响、沉闷、清脆},不同特征之间的组合,对应着西瓜的好坏,如下表:
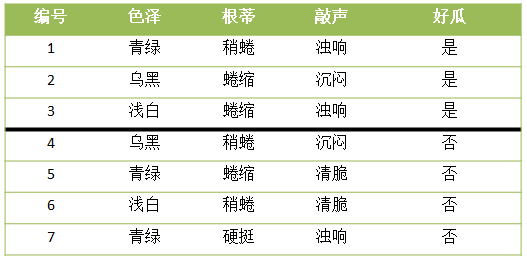
现在拿来一个新的西瓜,只知道它具有如下特征,问这个西瓜是好是坏?

要得出好瓜还是坏瓜,就要看他们分别对应的概率,谁大就是谁。
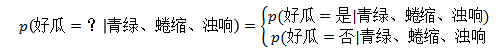
怎么求解呢?根据贝叶斯公式可以根据已知条件来求解

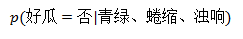
这两个哪个概率大,西瓜就属于那一类。贝叶斯公式忘记的,请看浅谈全概率公式和贝叶斯公式


由上述公式我们可以看出分母都是一样的,因此在计算的时候这个可以忽略,不影响最终的结果。对与分子中好瓜与坏瓜对应的概率,我们可以根据已知的数据,计算好瓜与坏瓜的比例即可:

那么对于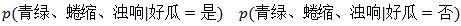


为什么要这么做呢?这就要说到朴素贝叶斯的由来了。
二、”朴素”由来
所谓朴素就是假设特征之间是相互独立的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 1687
1687

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









