







k均值聚类
原文地址:http://blog.csdn.net/hjimce/article/details/45200985
作者:hjimce
高斯混合模型和k均值聚类是聚类算法中的两种比较常用而简单的算法,这里先介绍k均值聚类算法。
一、K-means算法理论简介
K-means算法是硬聚类算法,是典型的基于原型的目标函数聚类方法的代表,它是数据点到原型的某种距离作为优化的目标函数,利用函数求极值的方法得到迭代运算的调整规则。K-means算法以欧式距离作为相似度测度,它是求对应某一初始聚类中心向量V最优分类,使得评价指标J最小。算法采用误差平方和准则函数作为聚类准则函数,总之就是要使得下面的公式最小化:
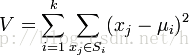
算法过程如下:
1)从N个文档随机选取K个文档作为质心
2)对剩余的每个文档测量其到每个质心的距离,并把它归到最近的质心的类
3)重新计算已经得到的各个类的质心
4)迭代2~3步直至新的质心与原质心相等或小于指定阈值,算法结束
二、K-means算法实现
K均值聚类算法实现分为四个步骤,设数据集为二维data,用matlab把数据绘制出来,如下所示:
绘制代码:

绘制结果:

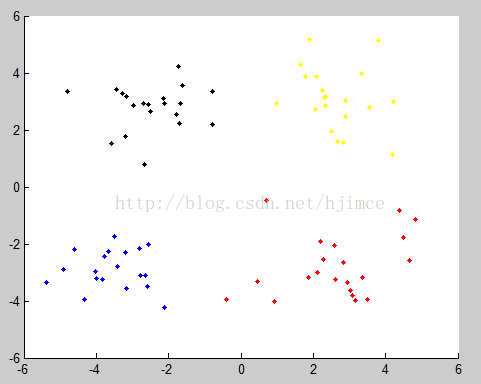
现在假设要把该数据集分为4类,算法步骤如下:
1) 初始化聚类中心
由于聚类个数选择4,因此我们用matlab随机生成4个不重复的整数,且大小不超过数据点的个数,得到初始聚类中心A,B,C,D。
2) 计算每个点分别到4个聚类中心的距离,找出最小的那个。假设点p为数据集中的点,求出A、B、C、D中距离p点最近的那个点,设B距离P最近,那么就把p点聚类为B类。
3) 更新聚类中心。根据步骤2可得数据集的聚类结果,根据聚类结果,计算每个类的重心位置,作为更新的聚类中心。然后返回步骤2,重新进行聚类,如此循环步骤2与步骤3,直到迭代收敛。
最后贴一下代码:
聚类结果如下:
opencv版kmeans:
声明:
enum
{
KMEANS_RANDOM_CENTERS=0, // Chooses random centers for k-Means initialization
KMEANS_PP_CENTERS=2, // Uses k-Means++ algorithm for initialization
KMEANS_USE_INITIAL_LABELS=1 // Uses the user-provided labels for K-Means initialization
};
//! clusters the input data using k-Means algorithm
CV_EXPORTS_W double kmeans( InputArray data, int K, CV_OUT InputOutputArray bestLabels,
TermCriteria criteria, int attempts,
int flags, OutputArray centers=noArray() );
实现函数:
double kmeans( const Mat& data, int K, Mat& best_labels,
TermCriteria criteria, int attempts,
int flags, Mat* _centers )
{
const int SPP_TRIALS = 3;
int N = data.rows > 1 ? data.rows : data.cols;
int dims = (data.rows > 1 ? data.cols : 1)*data.channels();
int type = data.depth();
bool simd = checkHardwareSupport(CV_CPU_SSE);
attempts = std::max(attempts, 1);
CV_Assert( type == CV_32F && K > 0 );
Mat _labels;
if( flags & CV_KMEANS_USE_INITIAL_LABELS )
{
CV_Assert( (best_labels.cols == 1 || best_labels.rows == 1) &&
best_labels.cols*best_labels.rows == N &&
best_labels.type() == CV_32S &&
best_labels.isContinuous());
best_labels.copyTo(_labels);
}
else
{
if( !((best_labels.cols == 1 || best_labels.rows == 1) &&
best_labels.cols*best_labels.rows == N &&
best_labels.type() == CV_32S &&
best_labels.isContinuous()))
best_labels.create(N, 1, CV_32S);
_labels.create(best_labels.size(), best_labels.type());
}
int* labels = _labels.ptr<int>();
Mat centers(K, dims, type), old_centers(K, dims, type);
vector<int> counters(K);
vector<Vec2f> _box(dims);
Vec2f* box = &_box[0];
double best_compactness = DBL_MAX, compactness = 0;
RNG& rng = theRNG();
int a, iter, i, j, k;
if( criteria.type & TermCriteria::EPS )
criteria.epsilon = std::max(criteria.epsilon, 0.);
else
criteria.epsilon = FLT_EPSILON;
criteria.epsilon *= criteria.epsilon;
if( criteria.type & TermCriteria::COUNT )
criteria.maxCount = std::min(std::max(criteria.maxCount, 2), 100);
else
criteria.maxCount = 100;
if( K == 1 )
{
attempts = 1;
criteria.maxCount = 2;
}
const float* sample = data.ptr<float>(0);
for( j = 0; j < dims; j++ )
box[j] = Vec2f(sample[j], sample[j]);
for( i = 1; i < N; i++ )
{
sample = data.ptr<float>(i);
for( j = 0; j < dims; j++ )
{
float v = sample[j];
box[j][0] = std::min(box[j][0], v);
box[j][1] = std::max(box[j][1], v);
}
}
for( a = 0; a < attempts; a++ )
{
double max_center_shift = DBL_MAX;
for( iter = 0; iter < criteria.maxCount && max_center_shift > criteria.epsilon; iter++ )
{
swap(centers, old_centers);
if( iter == 0 && (a > 0 || !(flags & KMEANS_USE_INITIAL_LABELS)) )
{
if( flags & KMEANS_PP_CENTERS )
generateCentersPP(data, centers, K, rng, SPP_TRIALS);
else
{
for( k = 0; k < K; k++ )
generateRandomCenter(_box, centers.ptr<float>(k), rng);
}
}
else
{
if( iter == 0 && a == 0 && (flags & KMEANS_USE_INITIAL_LABELS) )
{
for( i = 0; i < N; i++ )
CV_Assert( (unsigned)labels[i] < (unsigned)K );
}
// compute centers
centers = Scalar(0);
for( k = 0; k < K; k++ )
counters[k] = 0;
for( i = 0; i < N; i++ )
{
sample = data.ptr<float>(i);
k = labels[i];
float* center = centers.ptr<float>(k);
for( j = 0; j <= dims - 4; j += 4 )
{
float t0 = center[j] + sample[j];
float t1 = center[j+1] + sample[j+1];
center[j] = t0;
center[j+1] = t1;
t0 = center[j+2] + sample[j+2];
t1 = center[j+3] + sample[j+3];
center[j+2] = t0;
center[j+3] = t1;
}
for( ; j < dims; j++ )
center[j] += sample[j];
counters[k]++;
}
if( iter > 0 )
max_center_shift = 0;
for( k = 0; k < K; k++ )
{
float* center = centers.ptr<float>(k);
if( counters[k] != 0 )
{
float scale = 1.f/counters[k];
for( j = 0; j < dims; j++ )
center[j] *= scale;
}
else
generateRandomCenter(_box, center, rng);
if( iter > 0 )
{
double dist = 0;
const float* old_center = old_centers.ptr<float>(k);
for( j = 0; j < dims; j++ )
{
double t = center[j] - old_center[j];
dist += t*t;
}
max_center_shift = std::max(max_center_shift, dist);
}
}
}
// assign labels
compactness = 0;
for( i = 0; i < N; i++ )
{
sample = data.ptr<float>(i);
int k_best = 0;
double min_dist = DBL_MAX;
for( k = 0; k < K; k++ )
{
const float* center = centers.ptr<float>(k);
double dist = distance(sample, center, dims, simd);
if( min_dist > dist )
{
min_dist = dist;
k_best = k;
}
}
compactness += min_dist;
labels[i] = k_best;
}
}
if( compactness < best_compactness )
{
best_compactness = compactness;
if( _centers )
centers.copyTo(*_centers);
_labels.copyTo(best_labels);
}
}
return best_compactness;
}
}调用方法:
const int kMeansItCount = 10; //迭代次数
const int kMeansType = cv::KMEANS_PP_CENTERS; //Use kmeans++ center initialization by Arthur and Vassilvitskii
cv::Mat bgdLabels, fgdLabels; //记录背景和前景的像素样本集中每个像素对应GMM的哪个高斯模型,论文中的kn
//kmeans中参数_bgdSamples为:每行一个样本
//kmeans的输出为bgdLabels,里面保存的是输入样本集中每一个样本对应的类标签(样本聚为componentsCount类后)
kmeans( _fgdSamples, GMM::componentsCount, fgdLabels,
cv::TermCriteria( CV_TERMCRIT_ITER, kMeansItCount, 0.0), 0, kMeansType ); 














 1208
1208

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









