







梯度下降
- 对于机器学习中其中一个主要的步骤是构造Cost函数,当构建好Cost函数后需要对Cost函数进行优化,使得Cost值最小。
* 策略1:随机寻找(不太实用)
最直接粗暴的方法就是,我们尽量多地去试参数,然后从里面选那个让损失函数最小的参数组,最为最后的W。
* 策略2:随机局部搜索
在现有的参数W基础上,随机搜索一下周边的参数,查看有没有比现在更好的W,然后用新的W替换现有的W,不断迭代。
* 策略3:梯度下降
找到最陡的方向,逐一小步,然后再找到当前位置最陡的下山方向,再迈一小步…
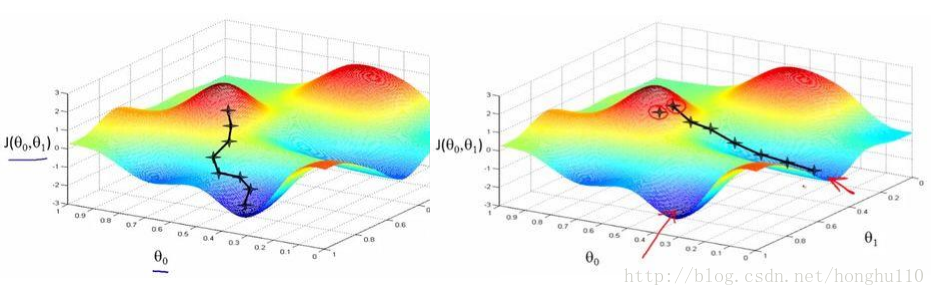
以线性回归为例,对于假设函数(Hypothesis):
构造Cost函数:
优化目标是最小化:
高等数学中我们学过求函数最小值可以通过求解导数,对 J(θ0,θ1) 求偏导数:
梯度下降(Gradient descent algorithm)
repeat until convergence{
θ0:=θ0−α∂J(θ0,θ1)∂θ0
θ1:=θ1−α∂J(θ0,θ1)∂θ1
}
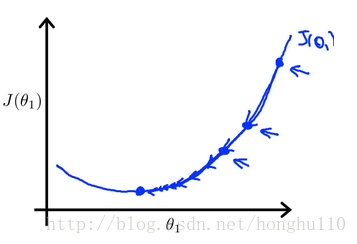
原理:对于某个点
(x0,y0)
,其导数表示在该点的瞬时变化率,也就是在在该点的斜率,表示从该点向其他点下滑的最快梯度。
具体推导见:http://blog.csdn.net/honghu110/article/details/55052909
反向传播
反向传播算法是神经网络中最有效的算法,其主要的思想是将网络最后输出的结果计算其误差,并且将误差反向逐级传下去。
方向传播运用的是链式求导的基本思想(隐函数求导),例如:
函数 u=ϕ(t) 在点t处可导, z=f(u)
dzdt=∂z∂u×dudt
举个简单的例子对于如下图所示的神经网络:

假设第一个神经元的表达式为
f1(x)=w0+w1x
, 第二个神经元的表达式为
f2(y)=θ0+θ1y
,那么实际上第一个神经元的输出是第二个神经元的输入,也就是第二个表达式中的
y=f1(x)
。对于训练这个模型首先采用前向传播算法(也就是按步骤计算得出输出结果):
对于输入
x1
计算:
假设输出结果计算后得到 y′1
构造代价函数为:
注: y1 表示分类, y′1 表示预测值
计算误差之后需要将误差反向传播回去,首先计算最后一层的误差,更新
θ1,θ0
θ0:=θ0−α∂C∂θ0
θ1:=θ1−α∂C∂θ1
然后再更新前一个节点的
w1,w0
w0=w0−α∂C∂f2×∂f2∂f1×∂f1∂w0
w1=w1−α∂C∂f2×∂f2∂f1×∂f1∂w1
采用梯度下降依次逐层更新知道最终收敛为止。
(感觉网上总结的反向传播算法都说的好高大上,看完理解后我自己总结了个比较容易理解的方案)
参考文献:http://m.blog.csdn.net/article/details?id=51039334














 91
91











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









