







 本文详细解析了深度学习神经网络中反向传播算法的原理,包括变量、常量的定义,网络权值和输入作为变量的推导过程,以及残差的计算方法。通过数学公式和实例解释了如何计算网络各层节点的残差,进而用于更新网络权重和偏置,实现模型的训练优化。
本文详细解析了深度学习神经网络中反向传播算法的原理,包括变量、常量的定义,网络权值和输入作为变量的推导过程,以及残差的计算方法。通过数学公式和实例解释了如何计算网络各层节点的残差,进而用于更新网络权重和偏置,实现模型的训练优化。
只限于自己看!
预先说明
首先,这里面什么看成变量,什么看成常量。
变量:网络的权值W(偏置b默认在W内。)以及输入X。
常量:就是target
你可能会说呃呃呃,不是输入都是有值吗,不都是数吗,怎么会是变量啊。。一般来说网络的反向传播就是两种类型。一种是更新网络权值W,这是属于常规的,一种是更新输入X。 不管哪种情况,我们都要把W和X看成变量,才能有反向传播。
推导过程中,W和X都是变量,输出是W和X的函数。
字母说明
W(l)ijWij(l):第ll层到第层的权值,并且是ll层的第个单元到l+1l+1层的第ii个单元的权值。
:第ll层的第个结点的输入和。
显然Z(l)i=∑s(l−1)j=0Wl−1ijxjZi(l)=∑j=0s(l−1)Wijl−1xj , 其中sl−1sl−1代表l−1l−1层的结点个数(不计算偏置单元)。可以这样说,第0个单元是偏置,1~s(n−1)s(n−1)是权重项。a(l)iai(l):表示第ll层的第个结点的激活值,就是下面说的out的输出,或是说a=f(net)a=f(net),写成a=f(z)a=f(z)也是一样的。
δ(l)iδi(l): 叫做“残差”,这里表示第ll层的第个节点的残差。这个非常重要,残差的定义就是——总的代价函数对于某个节点的“net”的偏导。注意的是这里的“net”指的是W*x+b这样的函数结构。可以这样看网络:
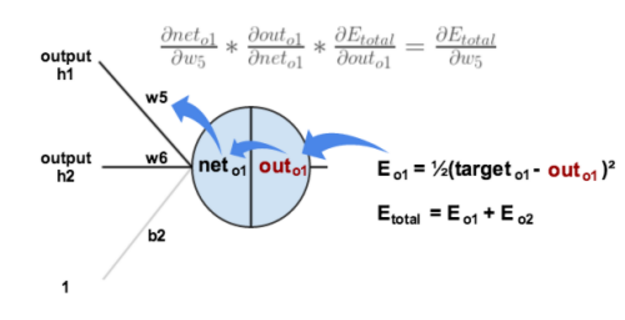
现在只需要看每个结点是如何处理数据的。不要看箭头,可以看到,h1和h2再加上“1”共三个结点输入,构成输入x⃗ x→, 而相应的权值W⃗ W→是w5w5,w6w6,b2b2, 也就是说 W⃗ ∗x⃗ W→∗x→就是这里的“net”,然后“out”是指激活后的值,就是f(net)f(net). 残差就是∂E∂net∂E∂net,*不是∂E∂out∂E∂out哦!
BP算法细节
参数说明:假设有n层。J表示代价函数,和上面的E是同样的意思,只不过用不同的字母写而已。
1: 首先当然是正向计算咯,分别求出L2,L3,...L2,L3,...直至最后一层LnLn的激活值。我们这里把输入当做第一层。下面是真正的反向传播。
2: 对于第n层(最后一层是特殊的,必须单独拿出来)每个输出单元ii,下面的的值为nn, 计算每个结点的残差:
注意:这里最后乘上了对“net”的导,如果是用sigmoid的函数的话,根据f′(z(l)i)=a(l)i(1−a(l)i)f′(zi(l))=ai(l)(1−ai(l)), 最后一层的第ii个结点的残差
3: 从倒数第二层开始,也就是说 l=n−1,n−2,n−3,...,2l=n−1,n−2,n−3,...,2 的各层,第ll层的第个结点的残差计算:
分析:要想知道第ll层的第个结点的残差,必须知道该节点所连接的下一层的各个结点的权值,以及这些结点的残差,幸亏第l+1l+1层已经计算出来了残差,你只要把后面一层的每个结点jj的残差乘以该结点与这一层的结点相连的权值,然后加和,最后别忘了乘以这一层的激活方式的导数。 不吹不黑,如果你不太懂得话,这段话可以够你看10遍,你就懂了。
4: 你可能会说要残差干嘛?当然是计算∂J∂w∂J∂w和∂J∂b∂J∂b用的。
只要:
结论:求J对“结点j到i的线路”的导数,求出后者i的残差,然后乘以这条线路的流量即可。
分析:其实是这样的,WlijWijl是第ll层到层的权值,并且是从结点jj到结点的权值。根据链式法则:
请仔细看上面的公式,好好理解。
残差的定义就是∂J(W,b;x,y)∂neti∂J(W,b;x,y)∂neti,根据链式法则:
注意,第l+1l+1层的∂neti∂wij∂neti∂wij就是该层的输入,也就是第ll层的输出.
最后一个问题,为啥
慢慢看,看懂问题不大。
编码
- 进行前馈传导计算,利用前向传导公式,得到 L2,L3,…L2,L3,… 直到输出层 LlLl 的激活值。
- 对输出层(第 ll层),计算:
- 对于l=nl−1,nl−2,nl−3,…,2l=nl−1,nl−2,nl−3,…,2 的各层,计算:
- δ(l)=((W(l))Tδ(l+1))∙f′(z(l))δ(l)=((W(l))Tδ(l+1))∙f′(z(l))
- 计算最终需要的偏导数值:
- ∇W(l)J(W,b;x,y)=δ(l+1)(a(l))T,∇b(l)J(W,b;x,y)=δ(l+1).∇W(l)J(W,b;x,y)=δ(l+1)(a(l))T,∇b(l)J(W,b;x,y)=δ(l+1).
最后说明一点,BP传播,计算各层的各点的残差是关键,残差是总的代价函数对于该点的net的偏导,从倒数第二层开始,求残差就要用到其后面的一层的各个残差,只要用后面一层的各个结点残差乘以其与这一层这个的结点所连接的权值,再求和,最后乘以这一层这个结点的out对net的偏导就可以了。如此一来,残差乘以这个结点的输入,就可以得到整个代价函数对于这个结点的w偏导了。

















 1454
1454

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









